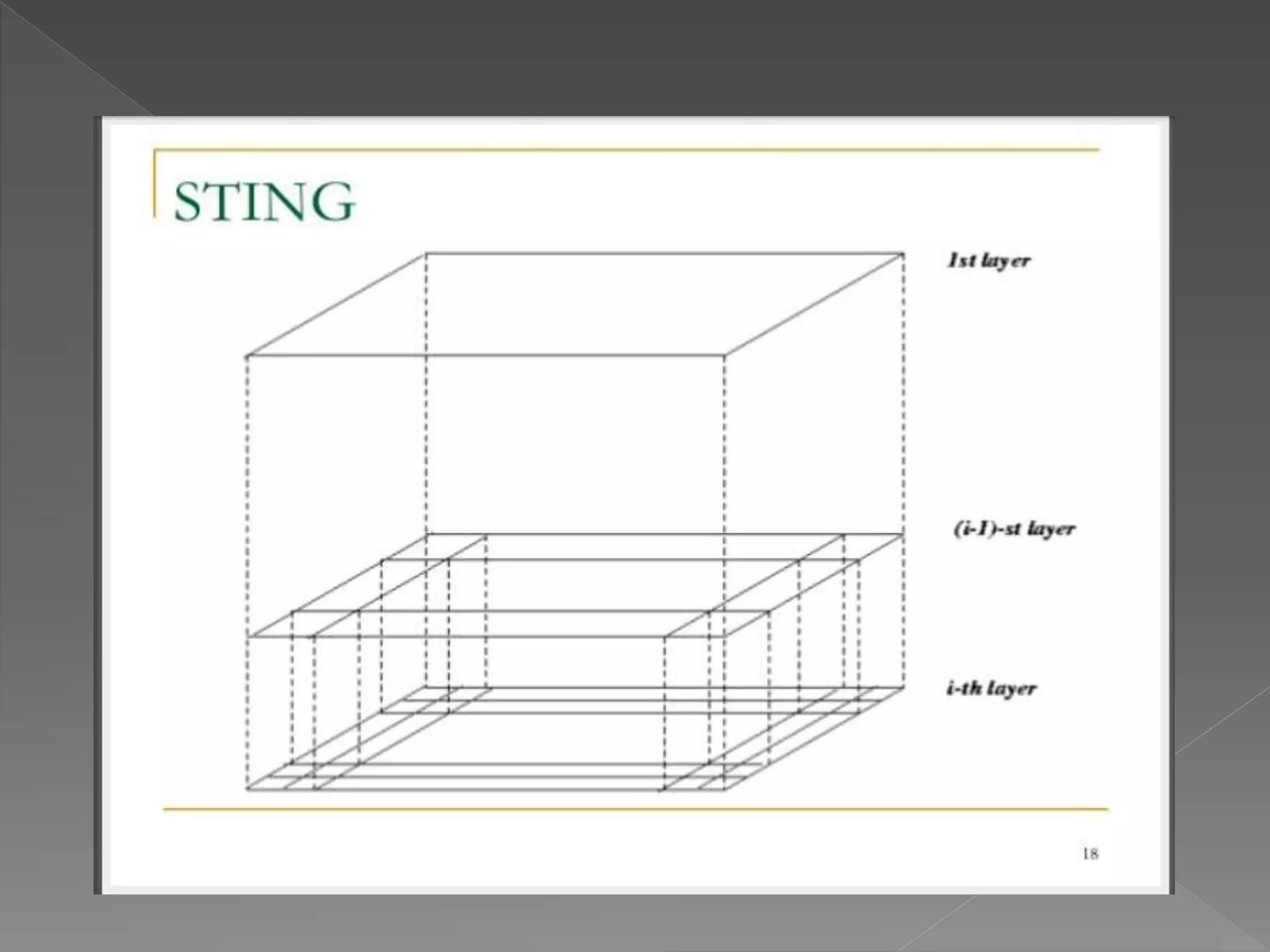
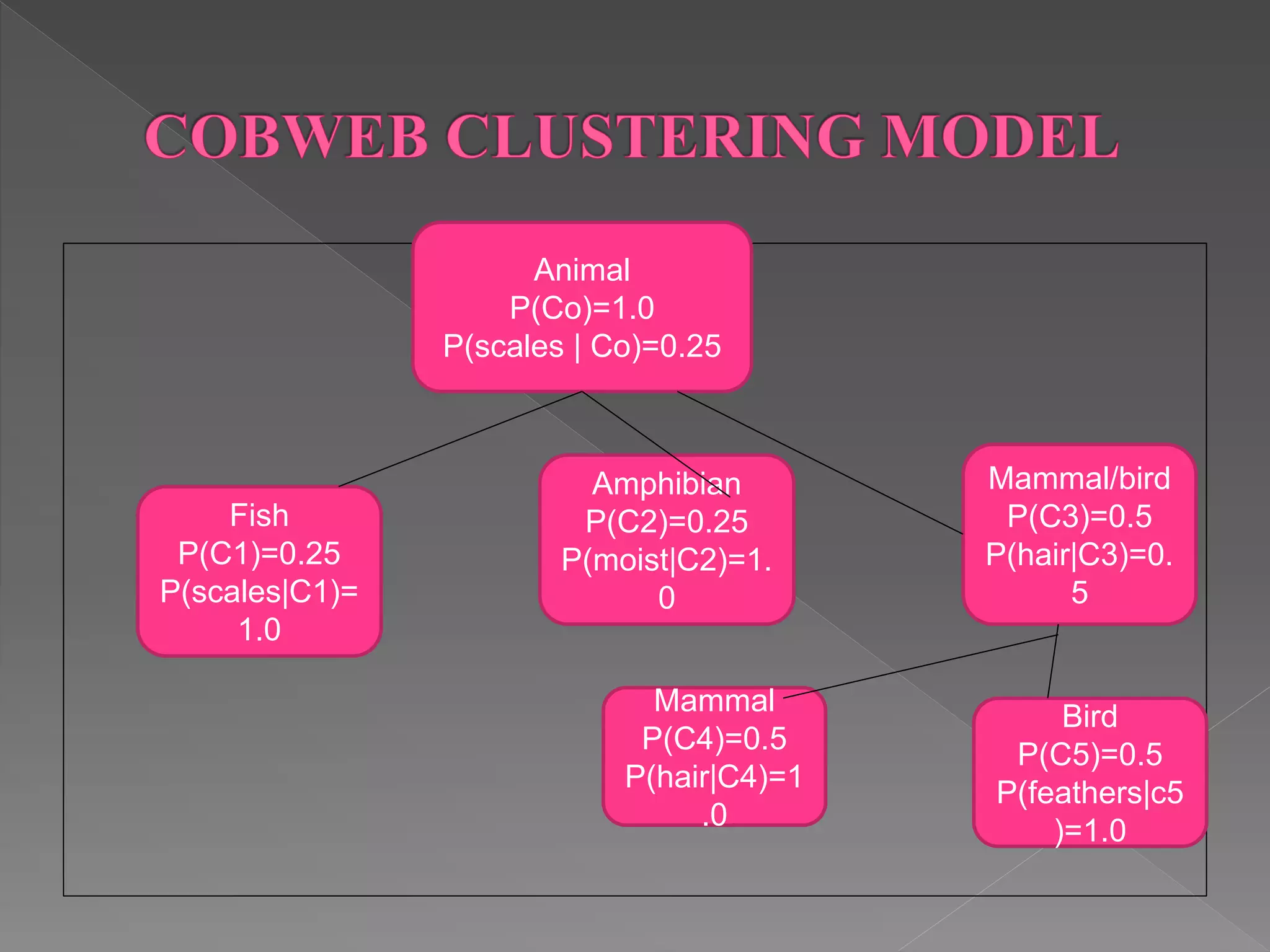
The document discusses several grid-based, density-based, and conceptual clustering algorithms. Grid-based approaches like STING and WAVECLUSTER cluster data by quantizing space into grids or cells. CLIQUE uses a grid-based approach to identify dense units of data. Conceptual clustering algorithms like COBWEB create hierarchical cluster trees to classify objects based on attribute probabilities.