Download as PDF, PPTX












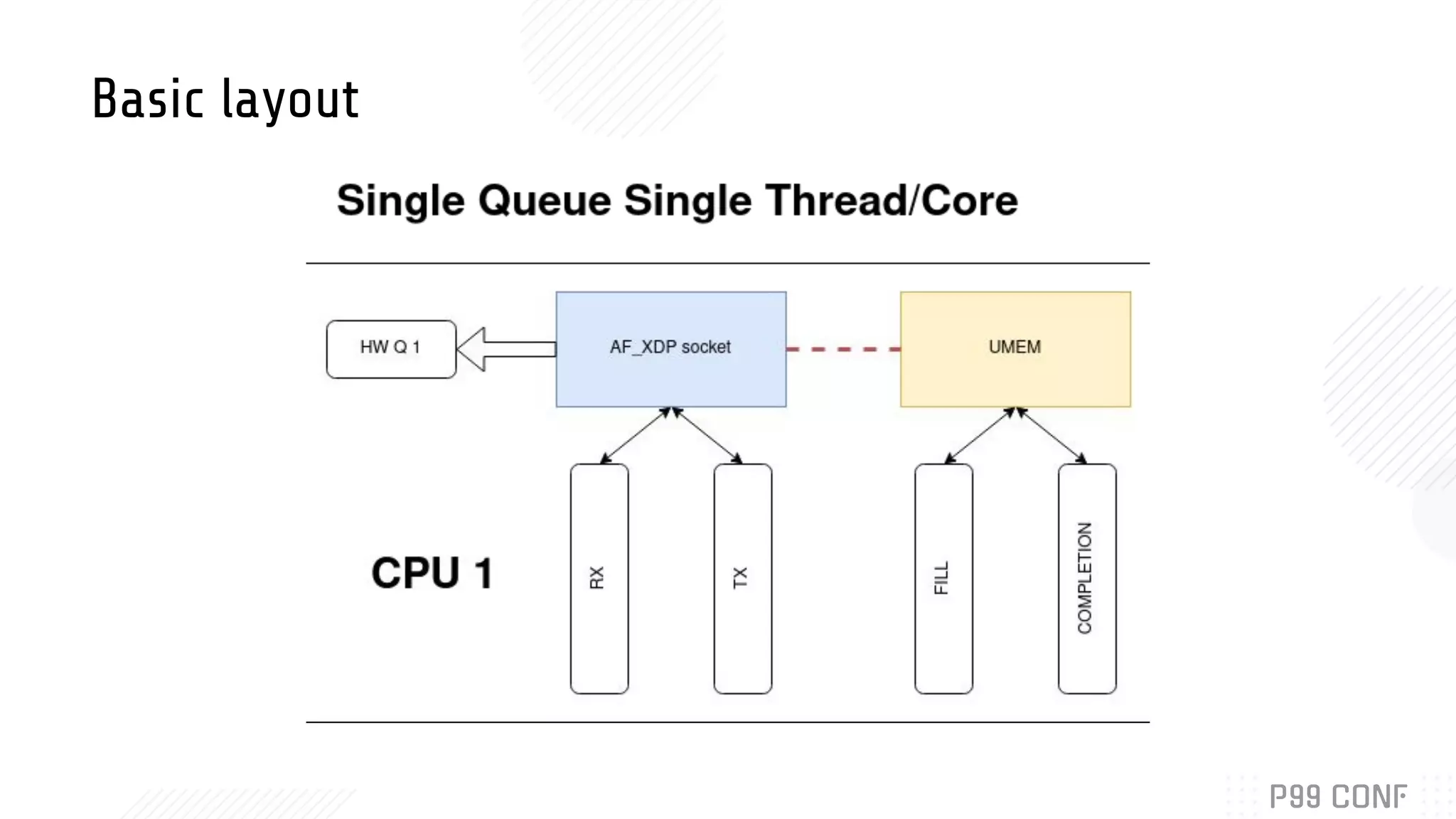
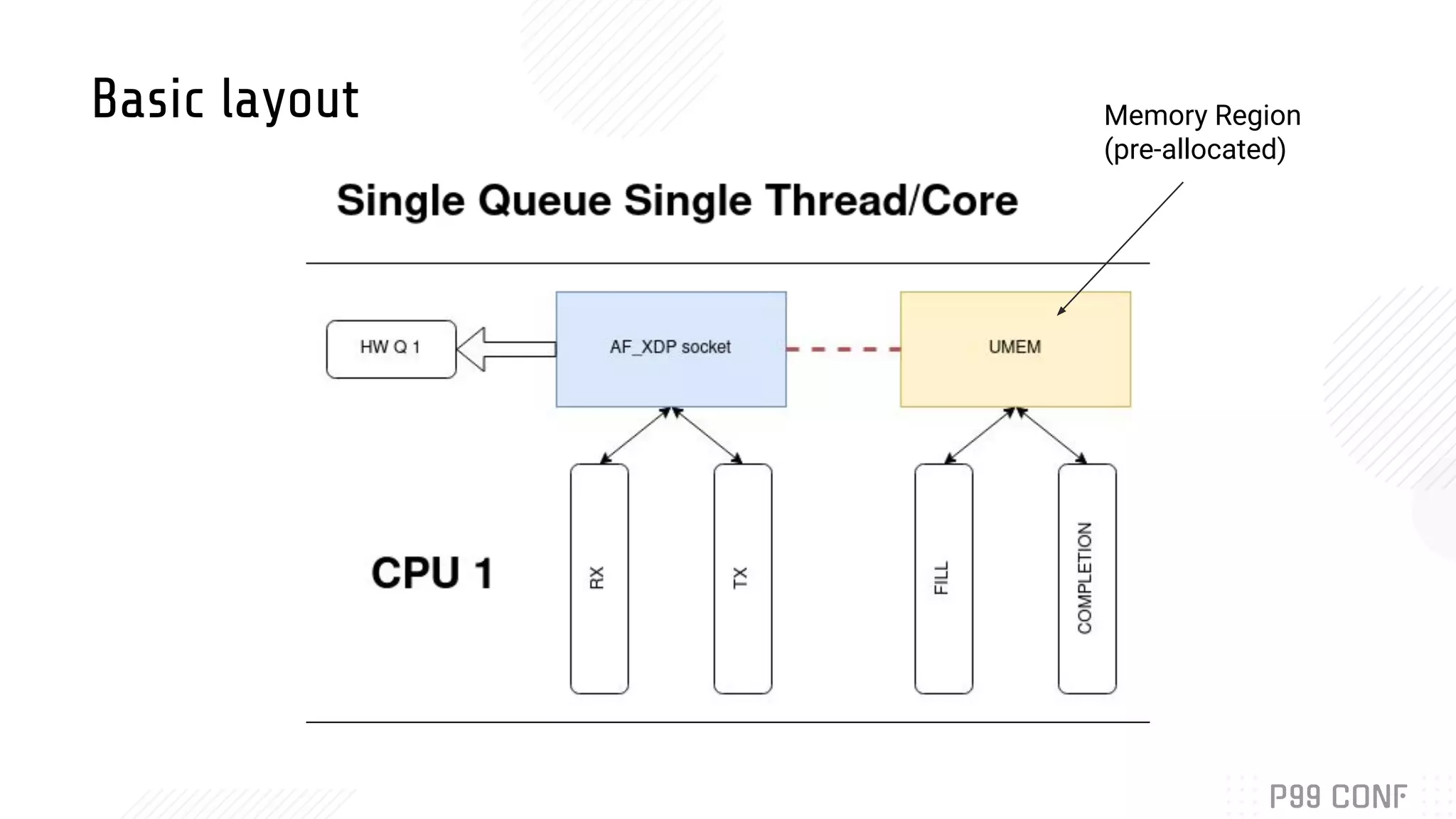
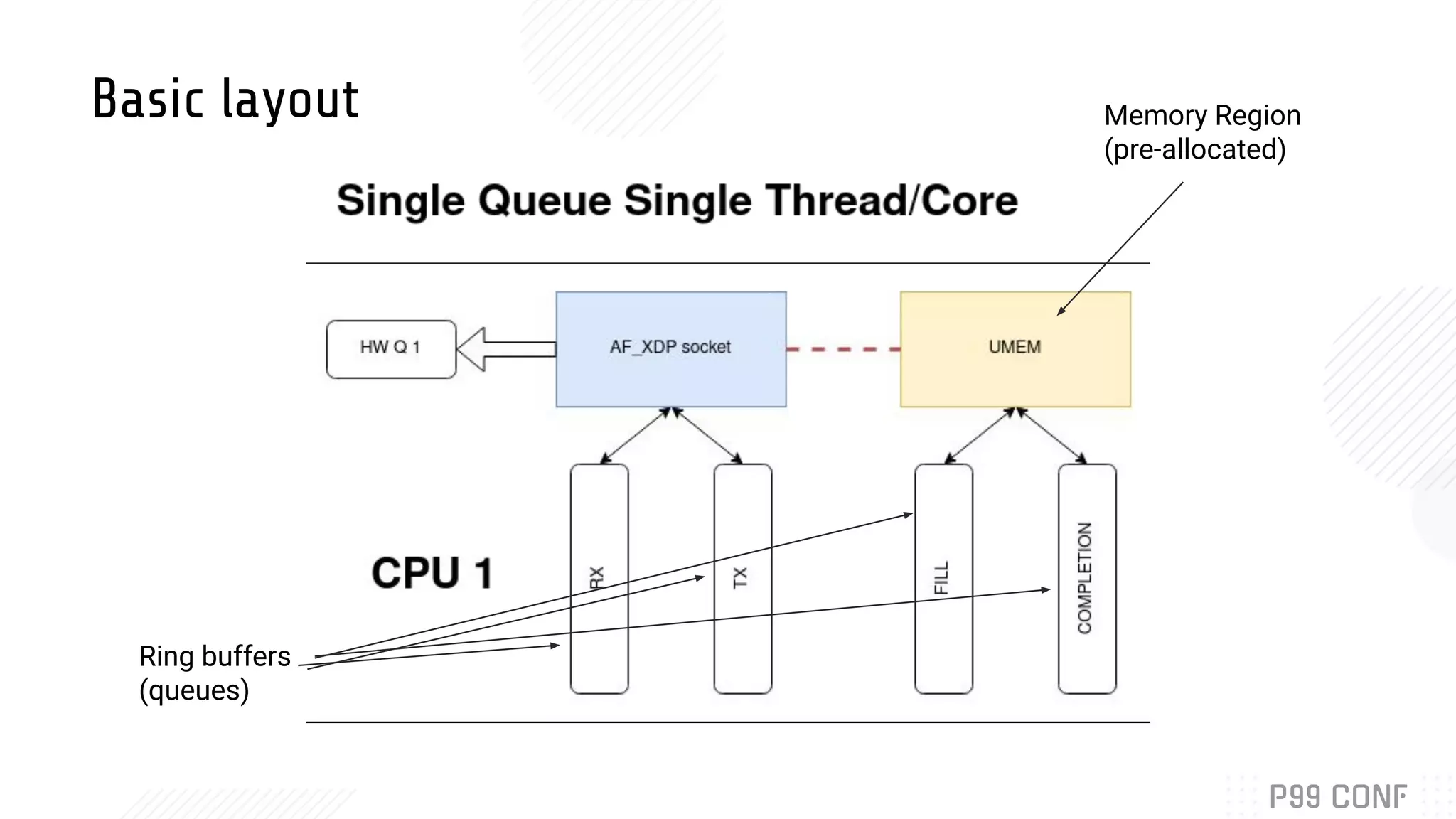
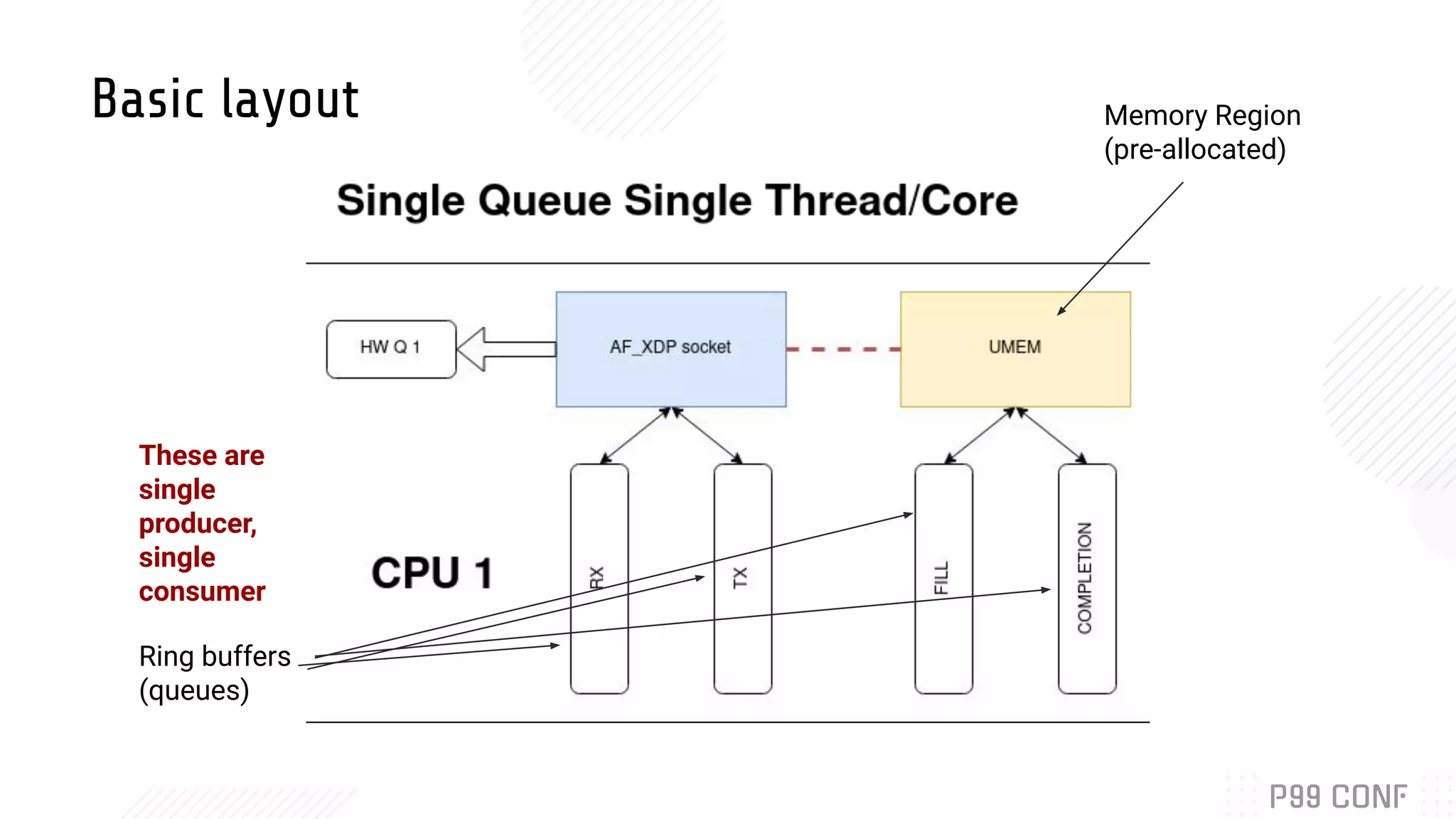
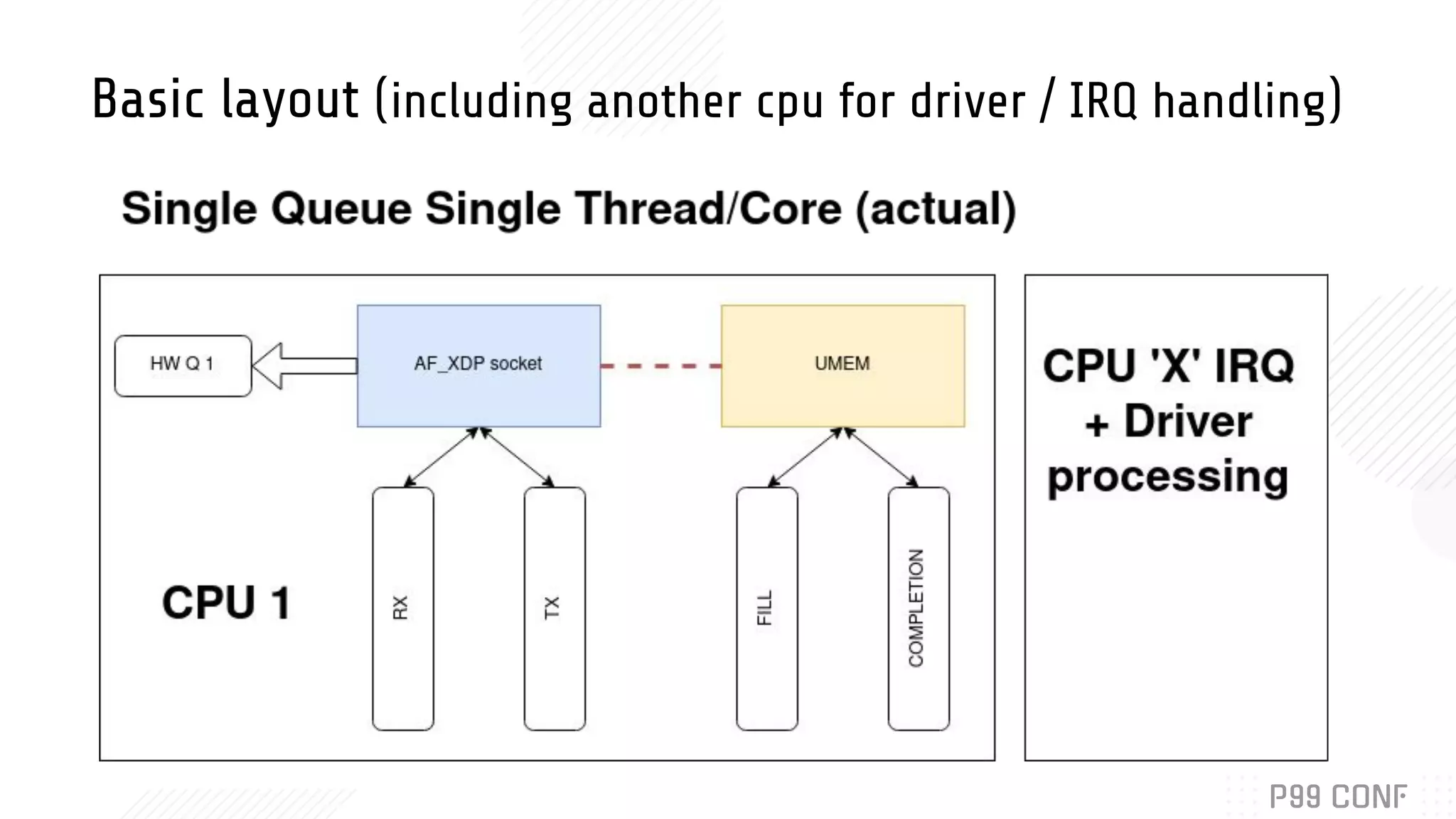



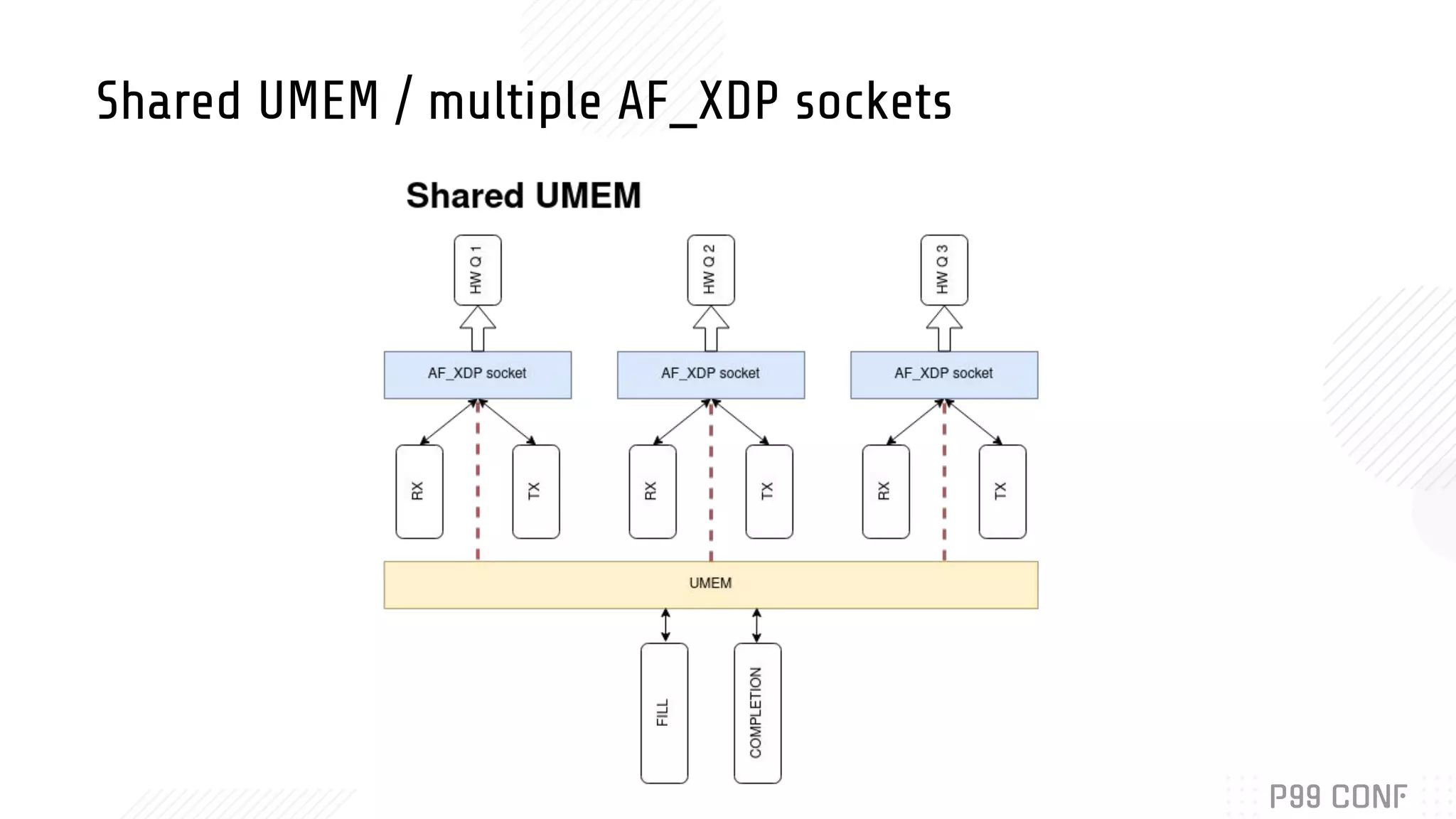
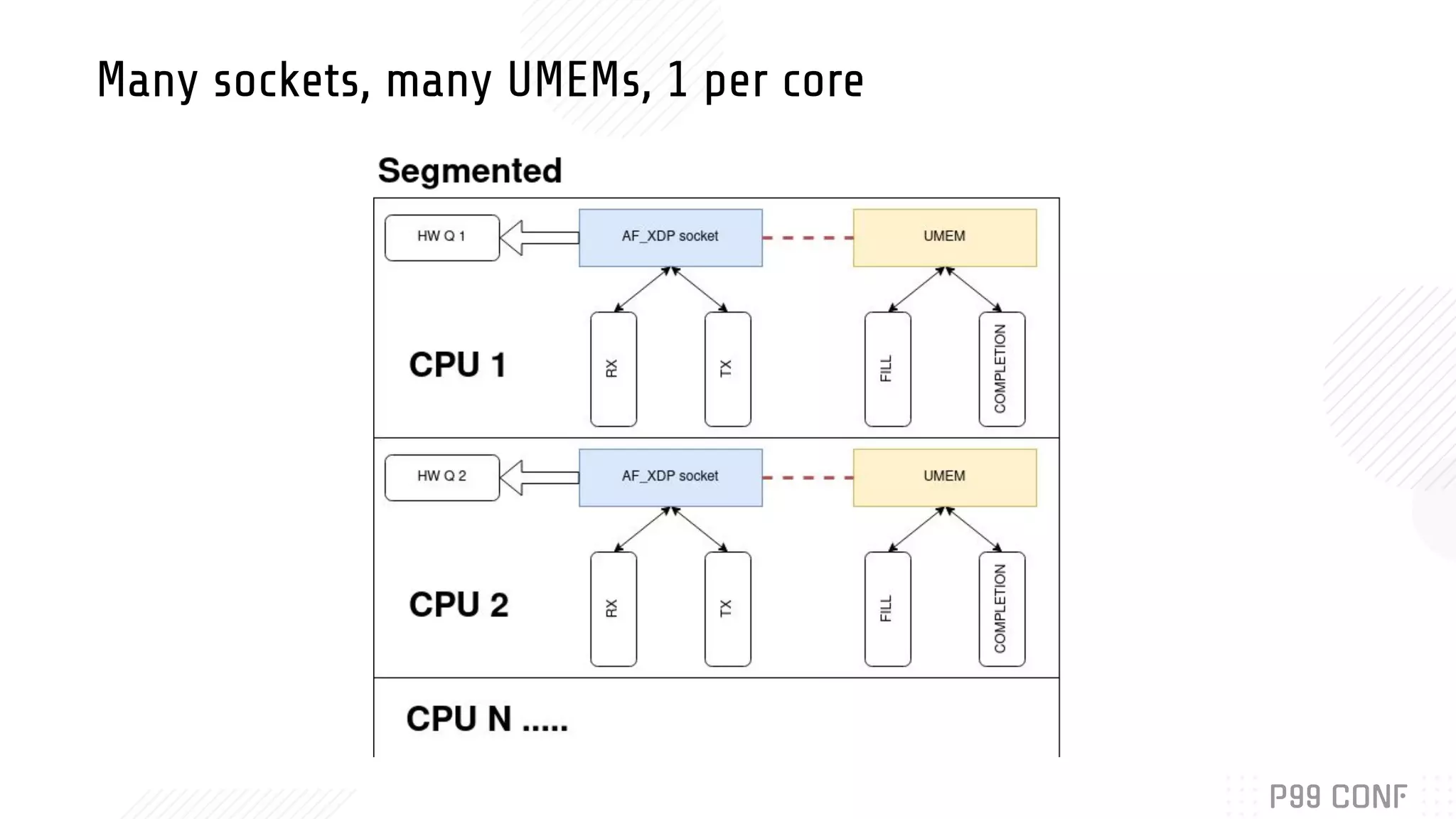







Bryan McCoid discusses using eBPF, XDP, and io_uring for high performance networking. XDP allows programs to process packets in the kernel without loading modules. AF_XDP sockets use eBPF to route packets between kernel and userspace via ring buffers. McCoid is building a Rust runtime called Glommio to interface with these techniques. The runtime integrates with io_uring and allows multiple design patterns for receiving packets from AF_XDP sockets.
Bryan McCoid introduces himself as a software engineer focused on Linux, eBPF, and networking.
High-performance applications are I/O bound, necessitating a focus on networking for improved performance.
Discusses various networking methods in Linux like blocking sockets, async sockets, and introduces eBPF.
XDP is introduced as a solution for kernel bypass, and its integration with eBPF is discussed.
Explains scalability issues and latency concerns with traditional networking methods in Linux.
Details the design and integration of AF_XDP with Rust’s Glommio library, exploring runtime design.
Discusses performance considerations when using io_uring and invites contributions to ongoing work.
Bonus slide highlighting popular projects relating to DPDK and XDP for reference.