Download as PDF, PPTX































The document outlines the Apache Flink Kubernetes Operator, detailing its functionalities for managing Flink applications and session clusters, including deployment, upgrades, and monitoring. Key features include support for different deployment modes, lifecycle management, and observability metrics. It also highlights the project's status, contributions from the community, and a roadmap for future enhancements.
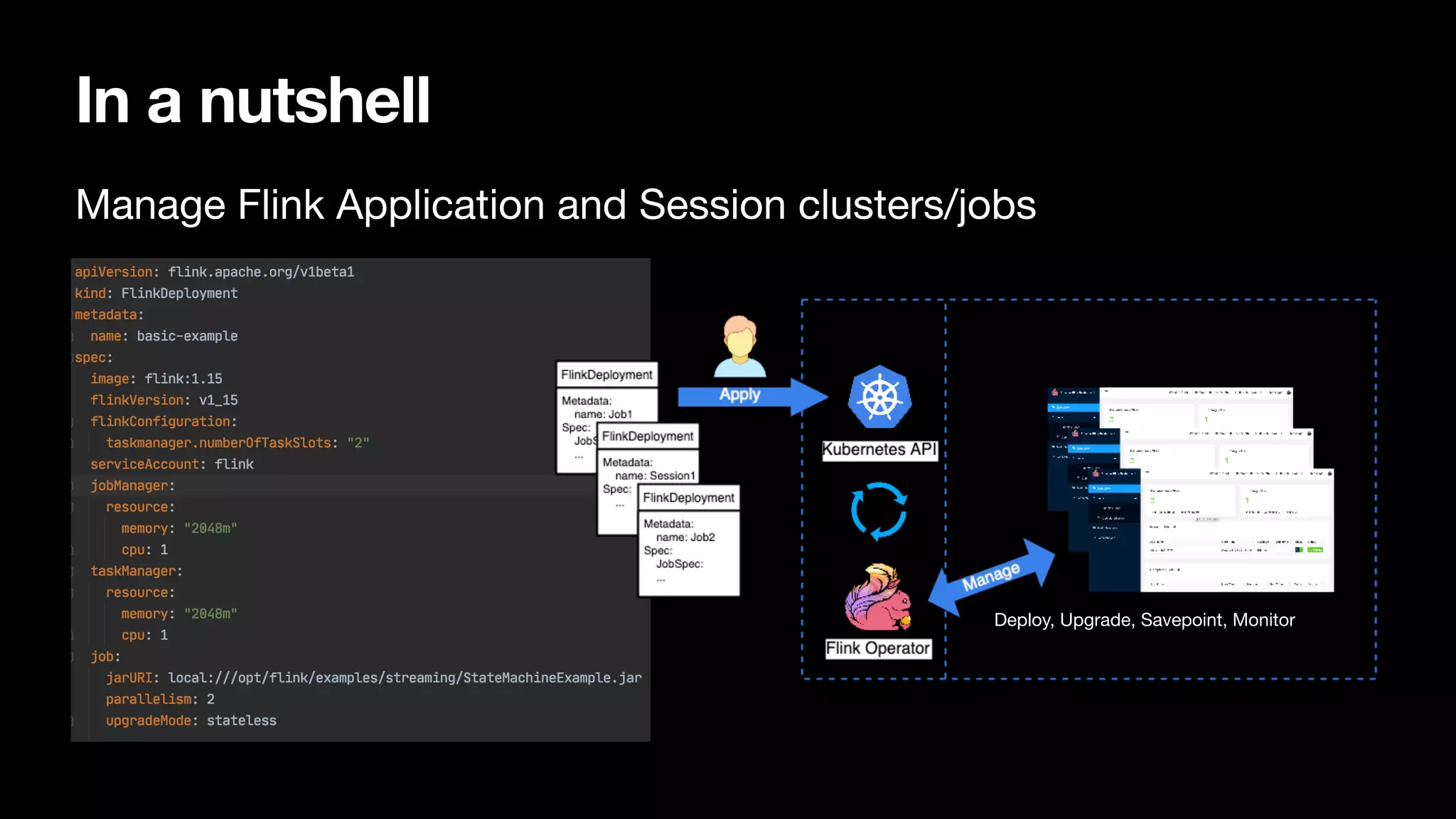
Introduction to Apache Flink Kubernetes Operator for managing Flink applications and providing features like deployment, monitoring, and job management.
Explains the rationale for introducing a new Flink Kubernetes Operator, addressing existing solutions' limitations such as fragmentation and maintenance issues.
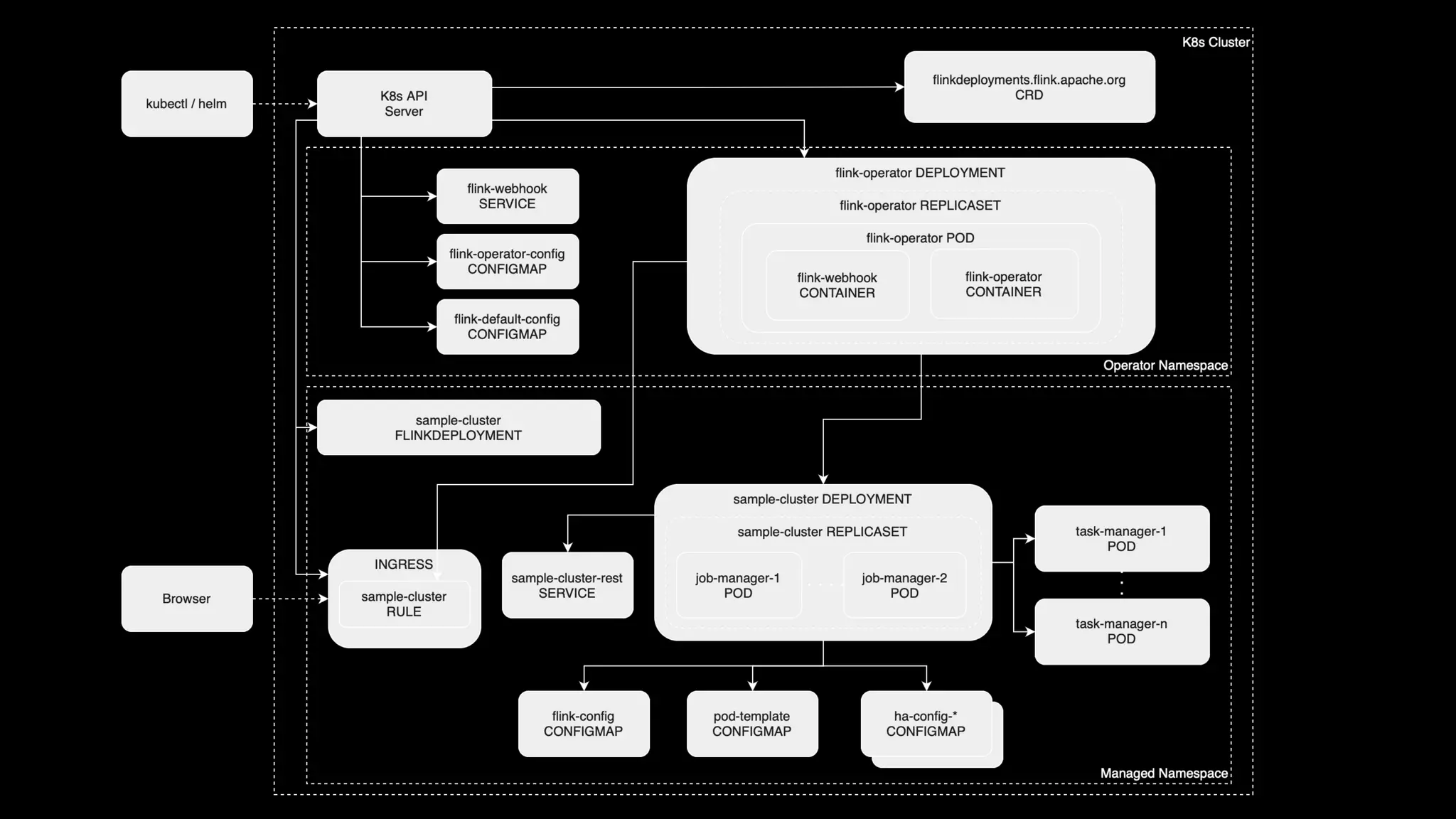
Describes supported deployment modes including application/session modes, managed through FlinkDeployment and session job management.
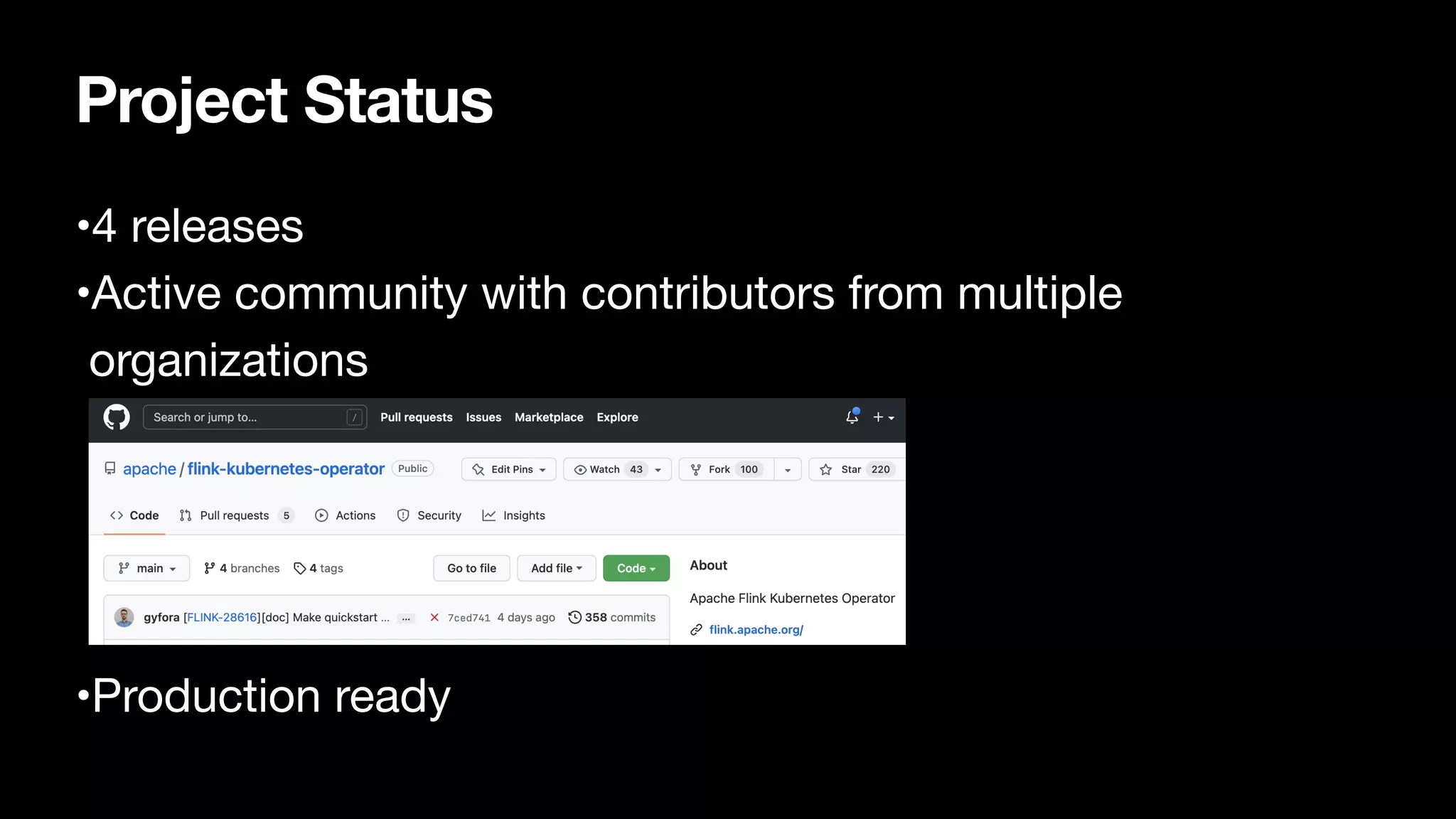
Project status indicating production readiness with active community contributions and a total of 27 contributors.
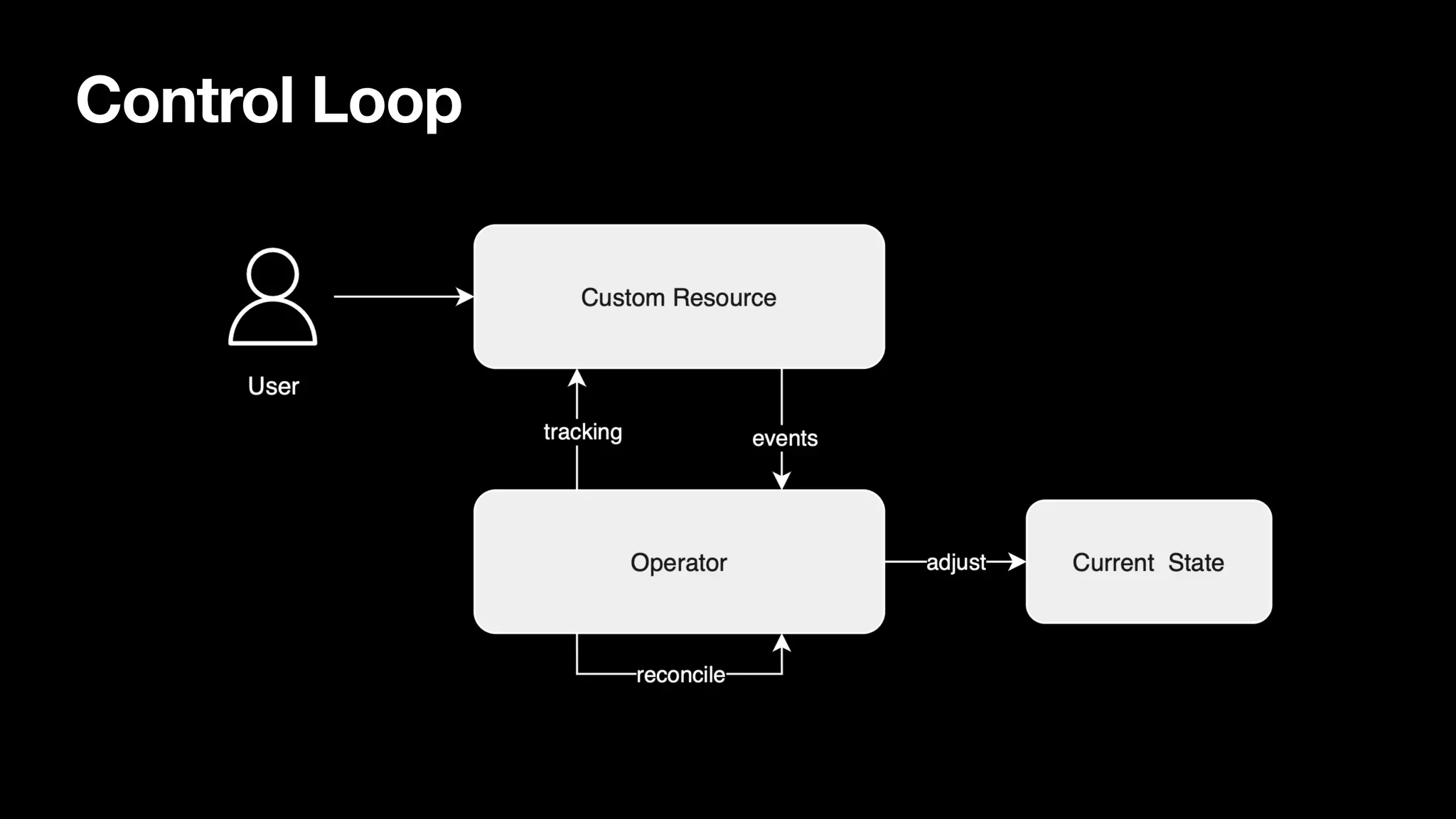
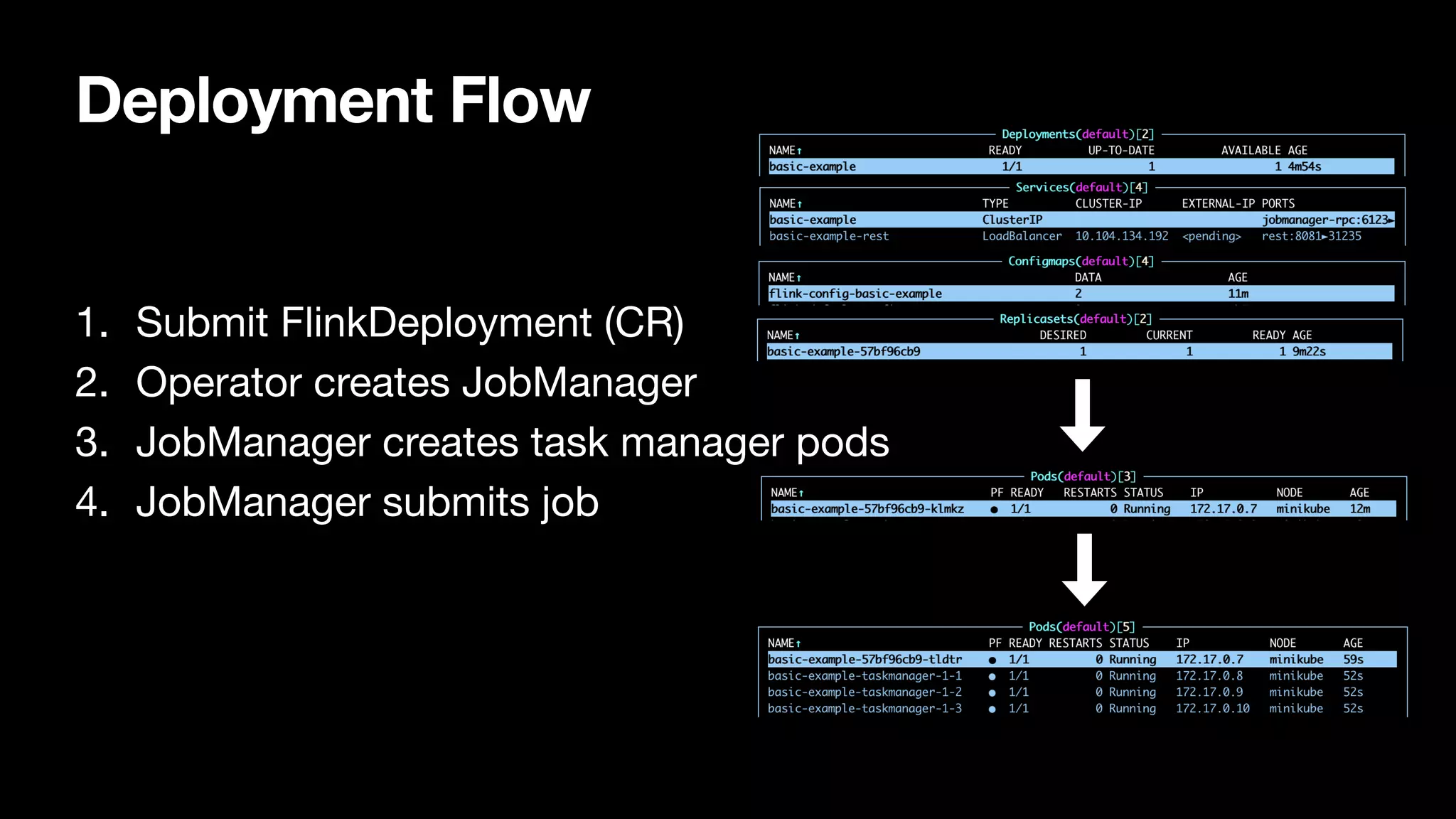
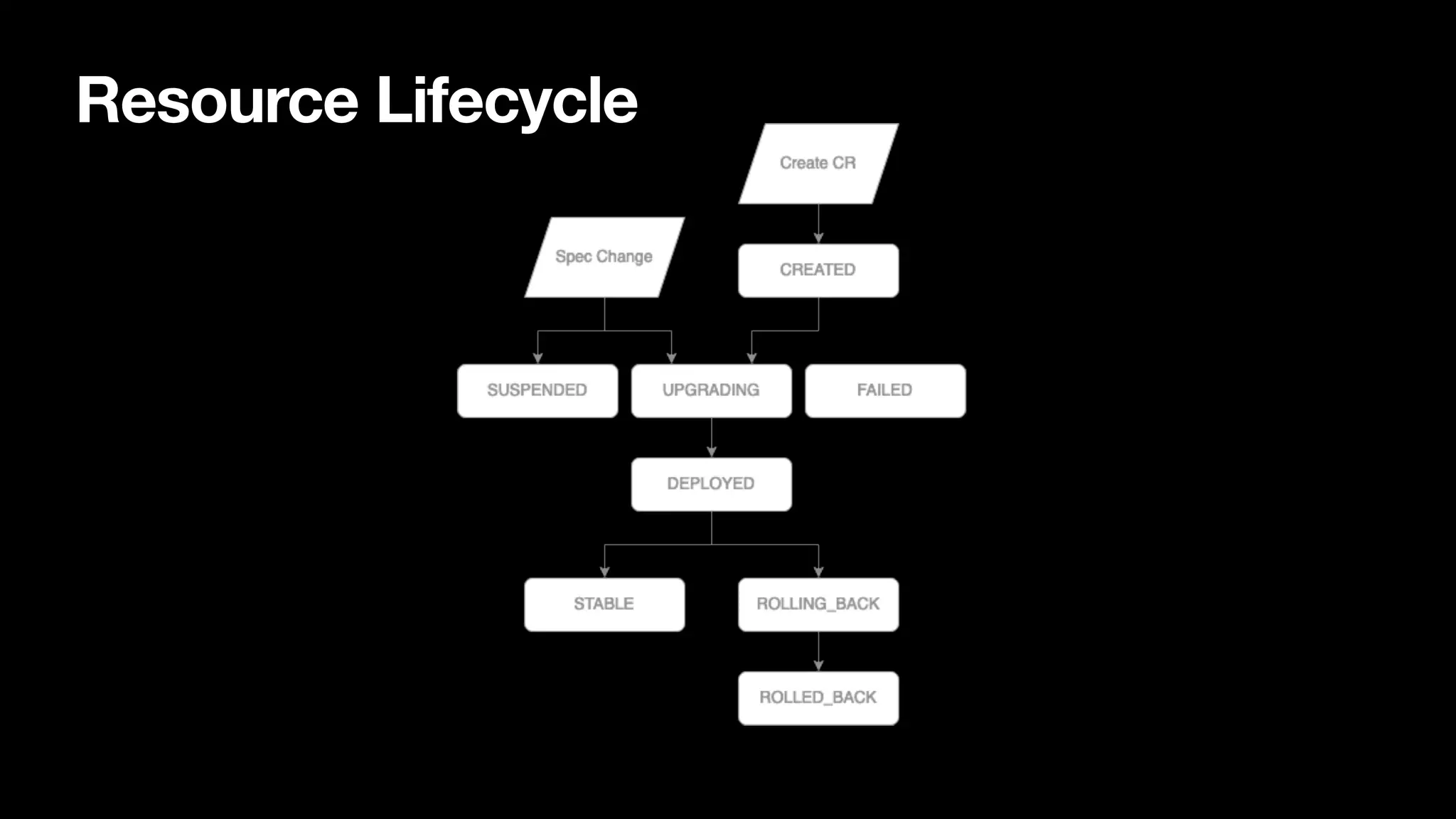
Fundamental concepts like the control loop, deployment flow, FlinkDeployment status, and observing deployment statuses effectively.
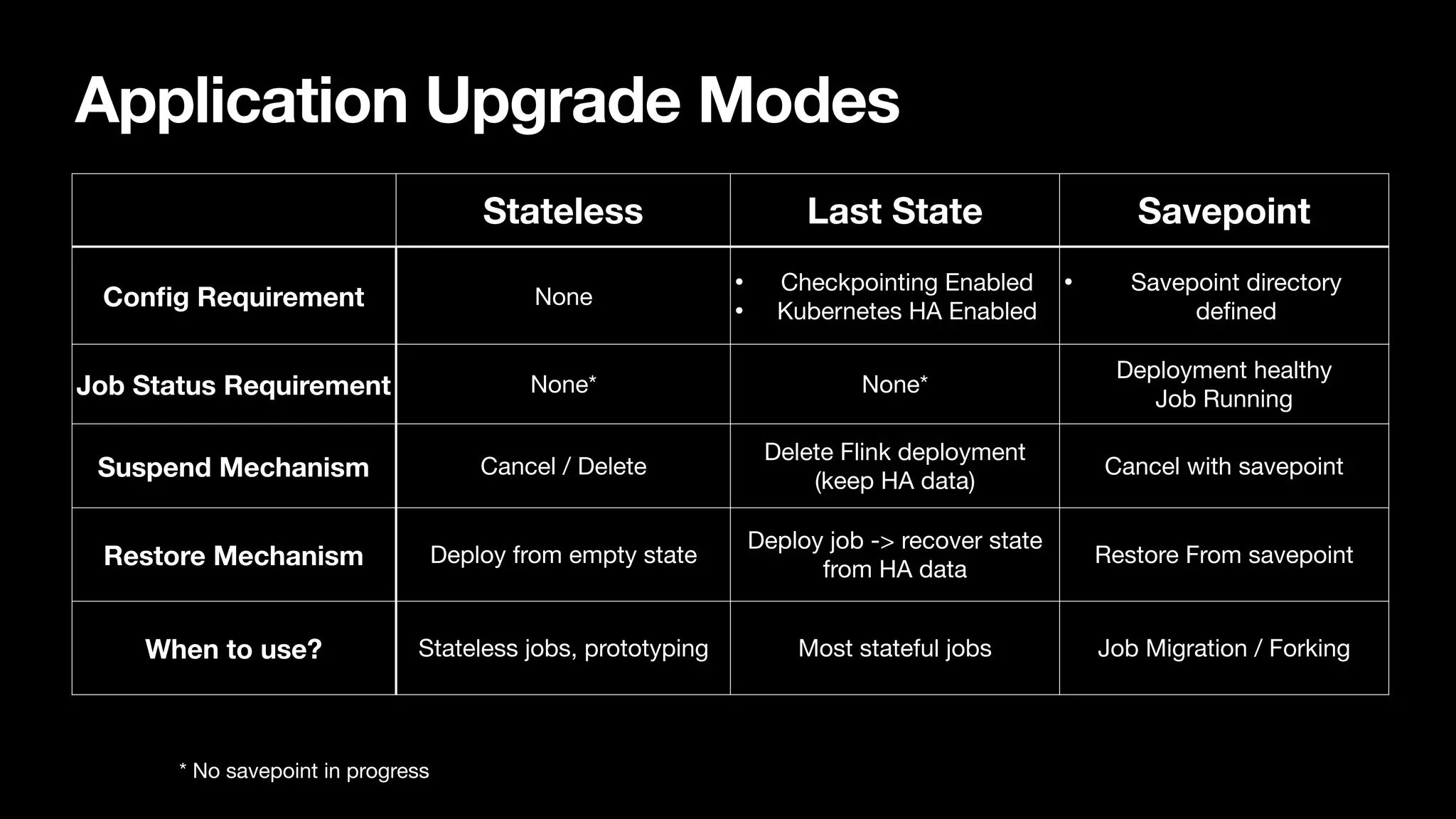
Discusses lifecycle management, resource management, job upgrades, and savepoint handling, focusing on upgrade modes and manual/automatic savepoints.
Details on configuring zero downtime changes, operator-level settings, and resource-specific configurations for optimal performance.
Discusses metrics, logging, and events in Kubernetes for observing Flink operator performance and system health.
Common error scenarios, their typical causes, and guidance on where to investigate when issues arise in Flink deployments.
Roadmap for future versions, highlighting planned features like dynamic namespace changes, enhanced savepoint management, and scaling support.
Open floor for questions, allowing for clarification and deeper understanding of the Apache Flink Kubernetes Operator.