Download as PDF, PPTX





















The document provides an overview of Apache Flink, emphasizing its capabilities for real-time stream processing and analytics. Key features include support for various programming languages, high performance and scalability, and fault tolerance through checkpointing mechanisms. Flink is geared towards enabling real-time data pipelines and event-driven applications that can efficiently handle both bounded and unbounded streams.
Introduction to Apache Flink, presented by David Anderson, Software Practice Lead at Confluent, highlighting its significance.
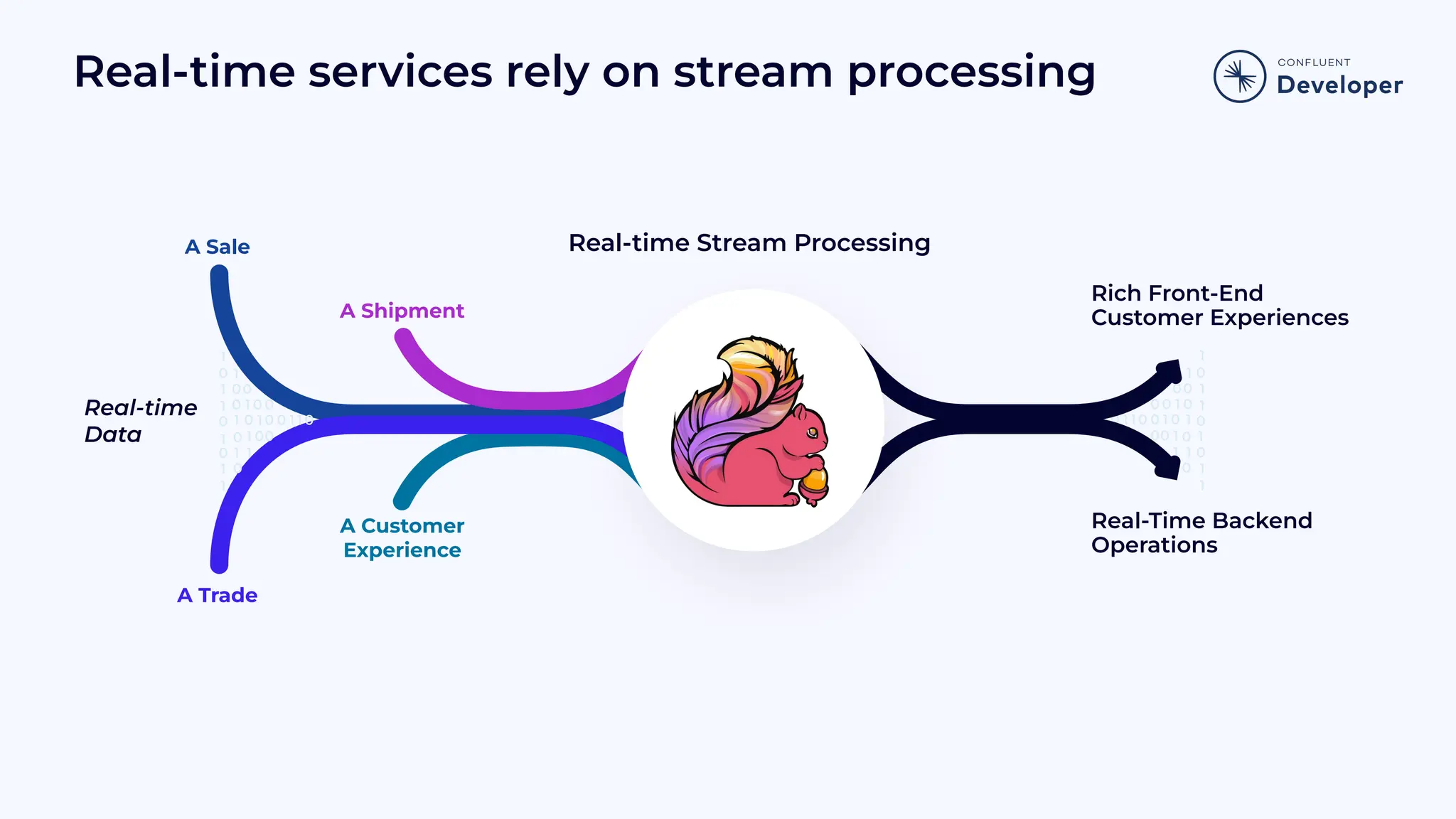
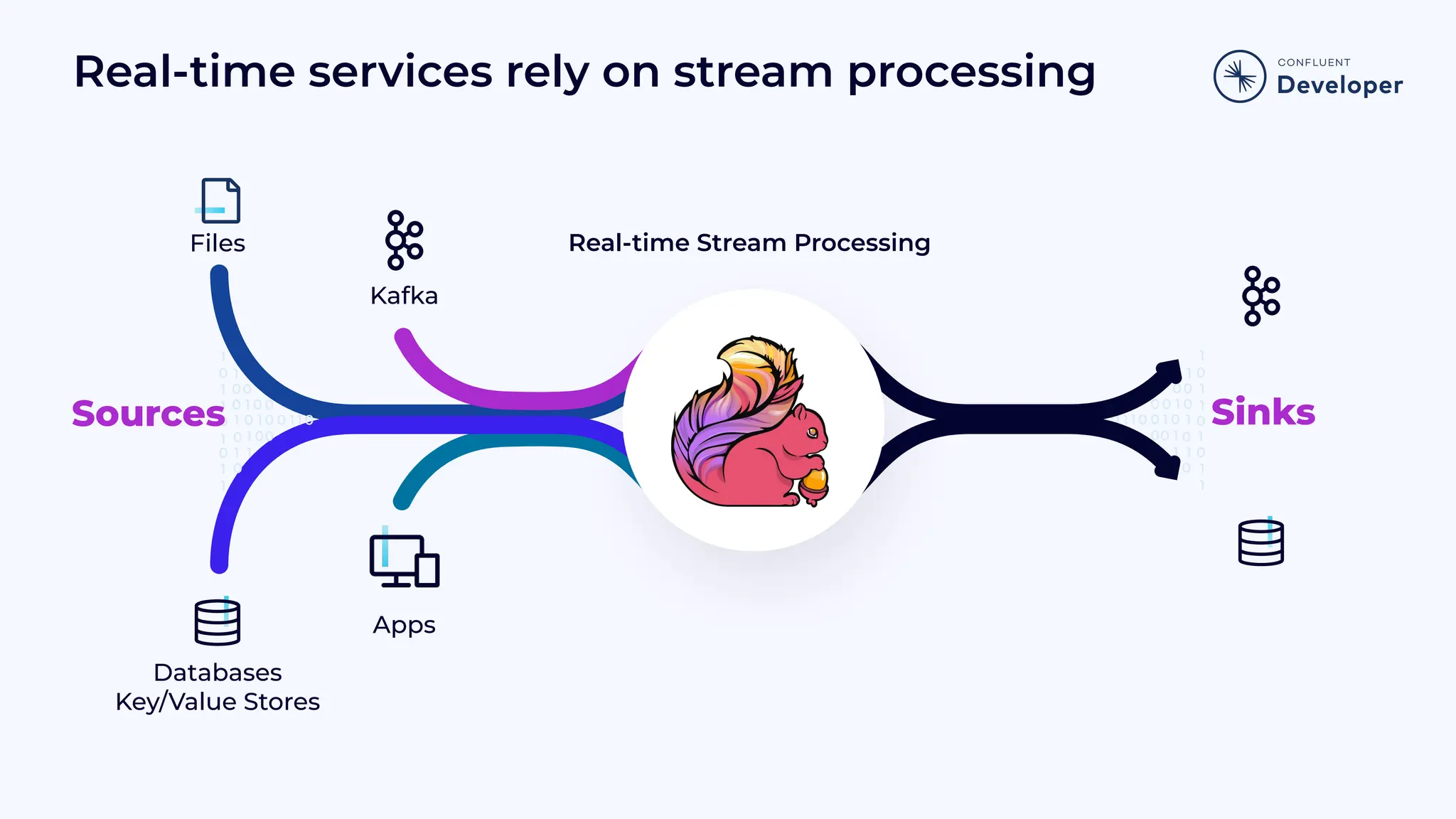
Discusses consumer demand for real-time services and highlights the application of real-time stream processing in various business operations.
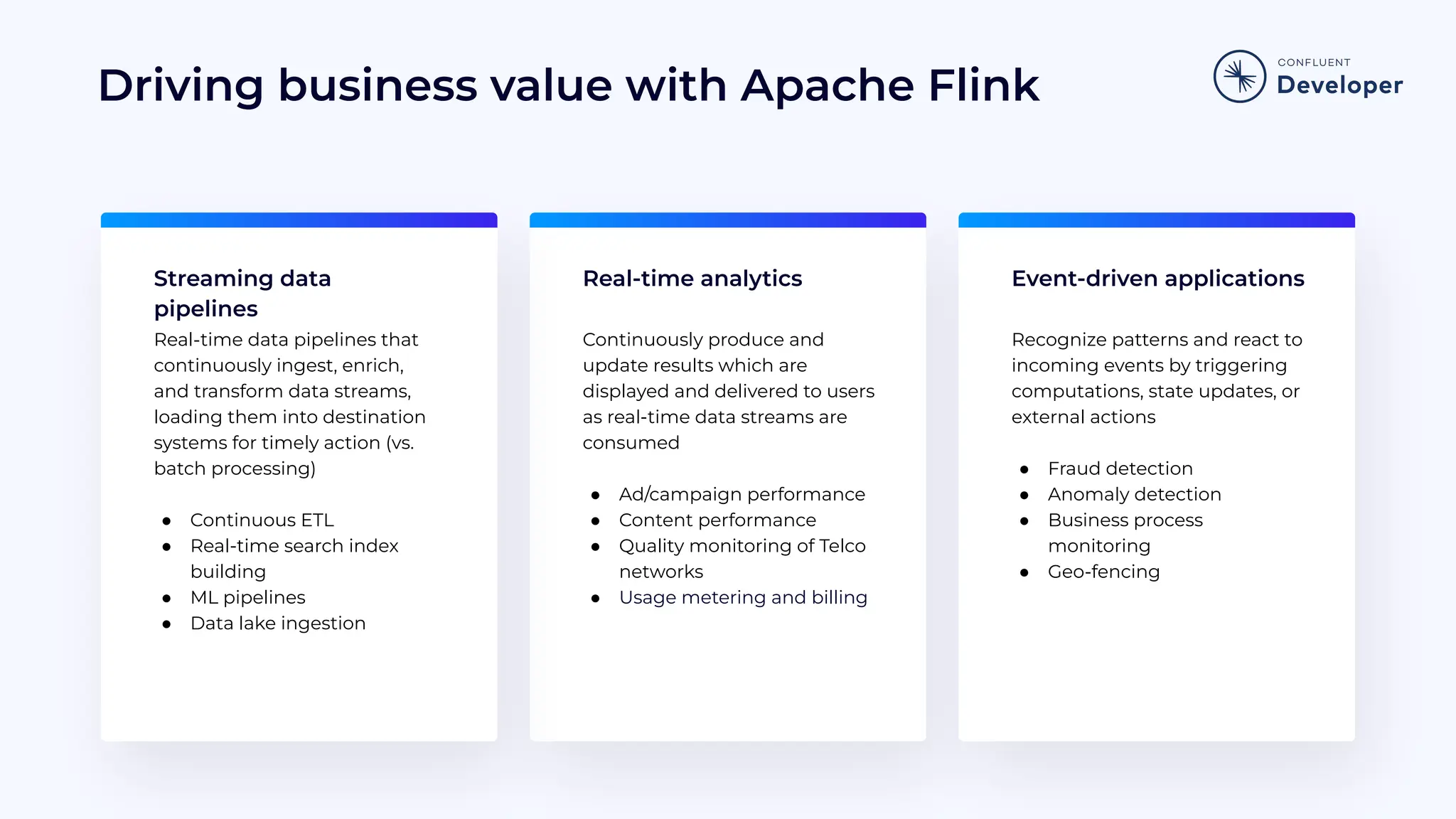
Explains how Flink drives business value through real-time analytics, event-driven applications, and streaming data pipelines.
Describes Flink’s performance, scalability, fault tolerance, and language flexibility, reinforcing its appeal among developers.
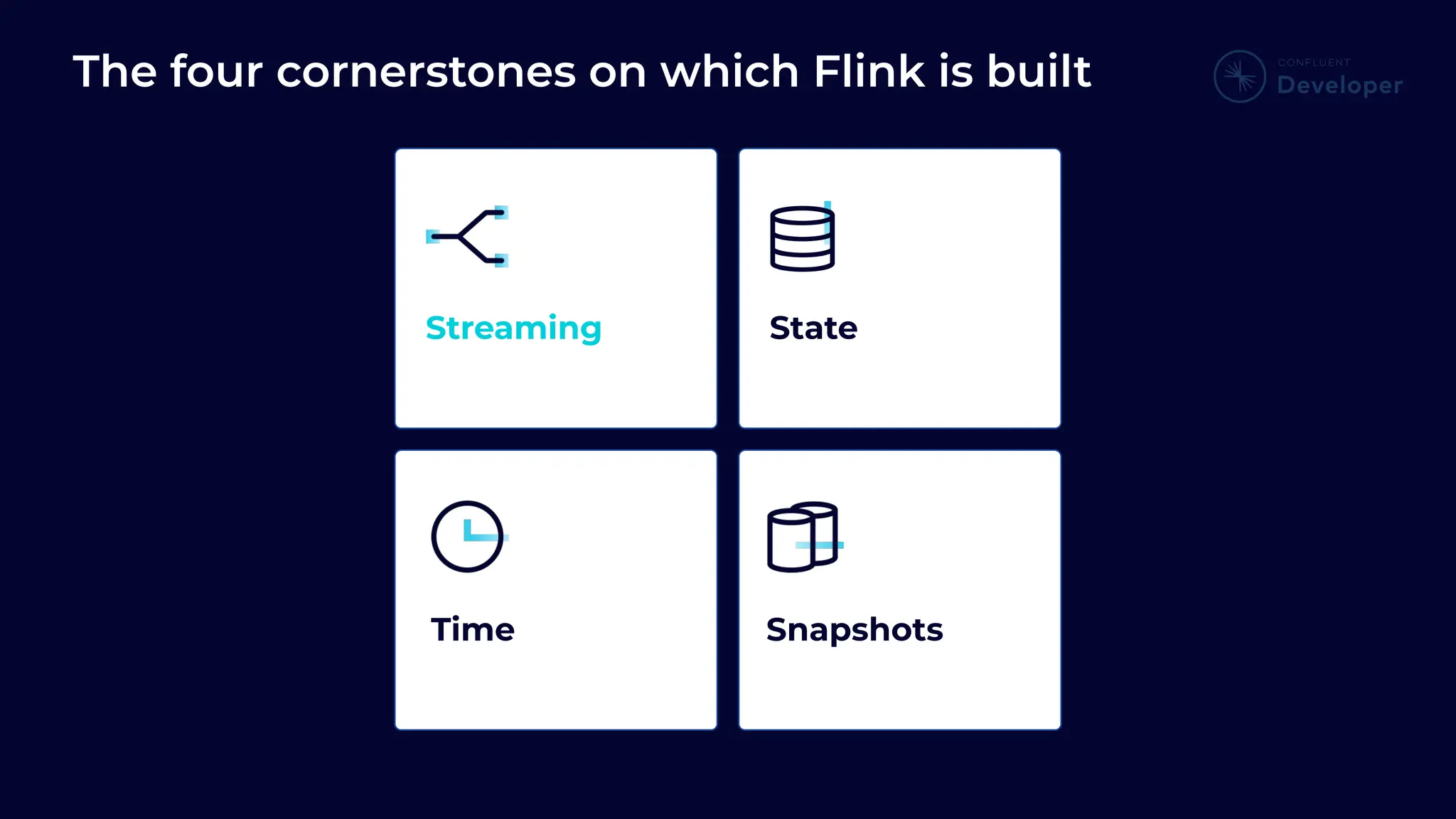
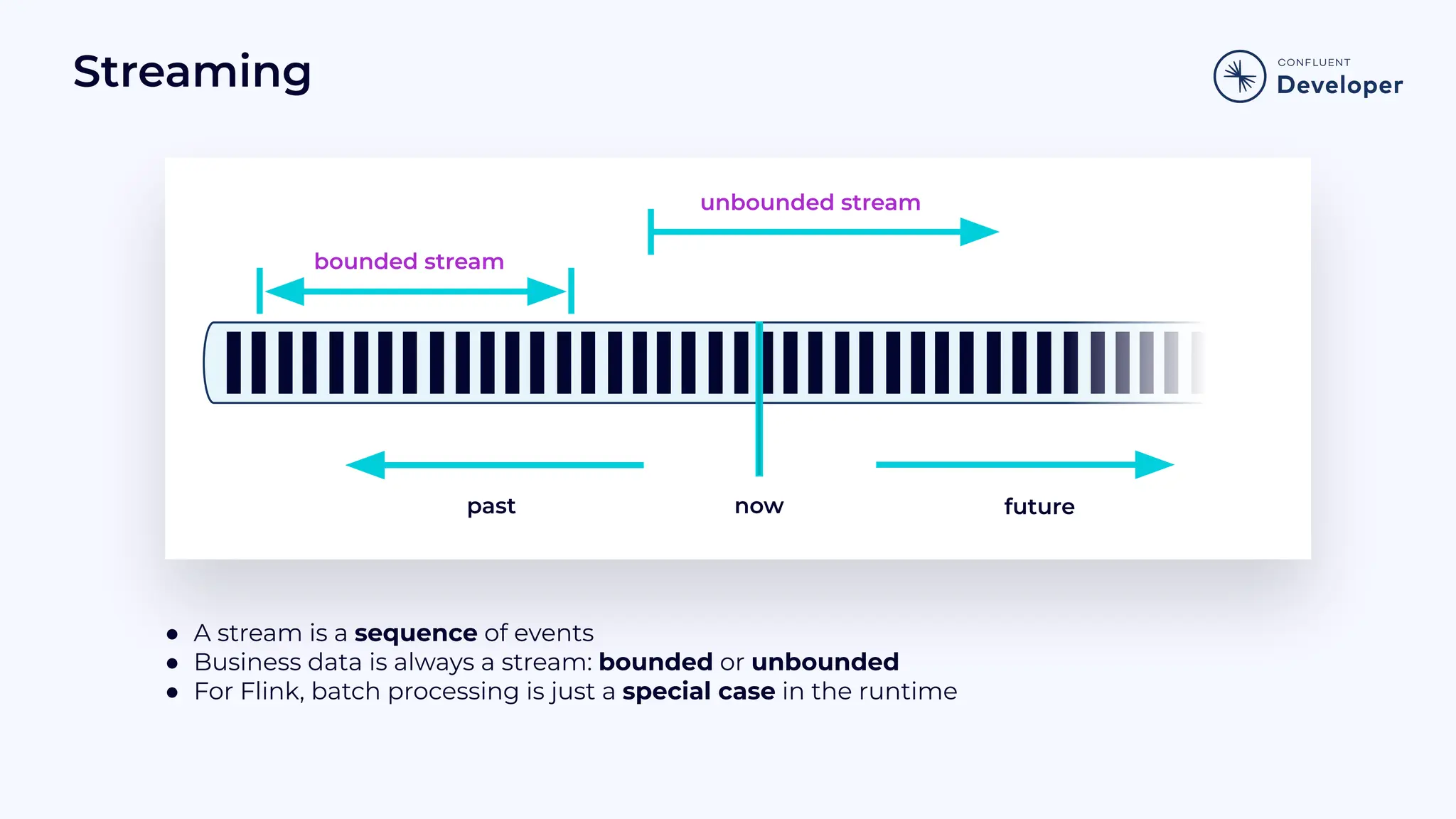
Outlines the four cornerstones of Flink, establishing the importance of streams in business data processing and real-time services.
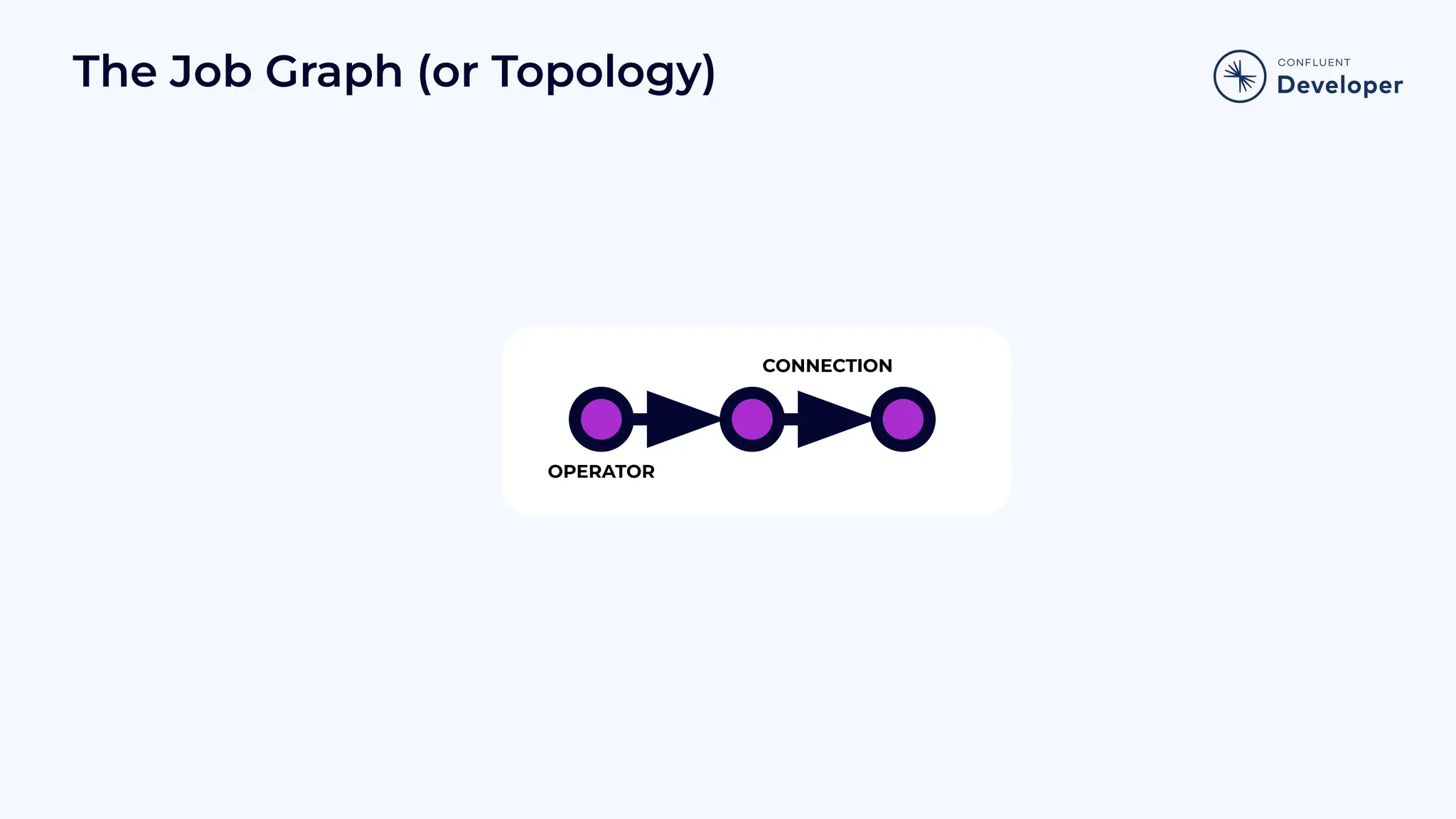
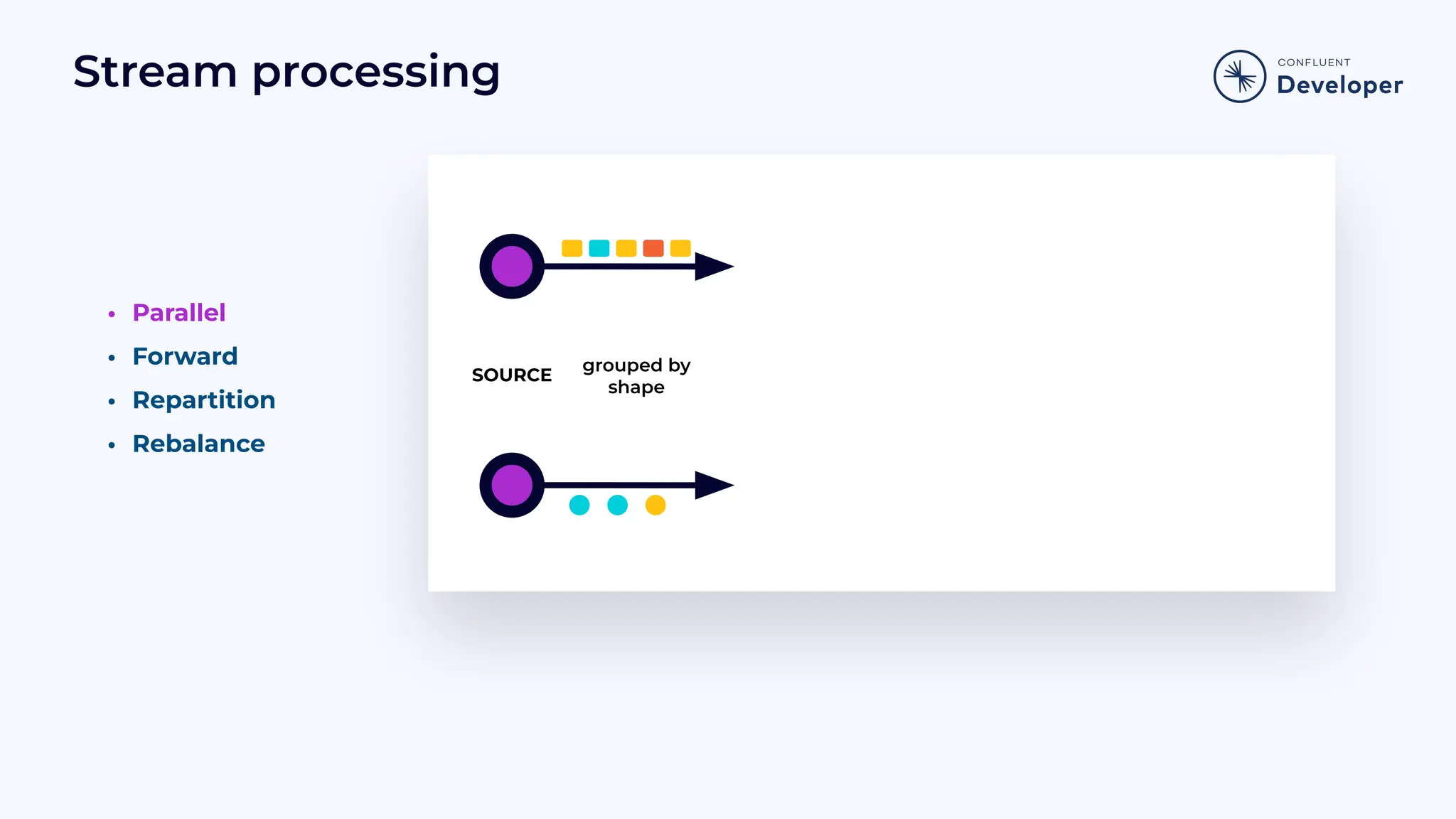
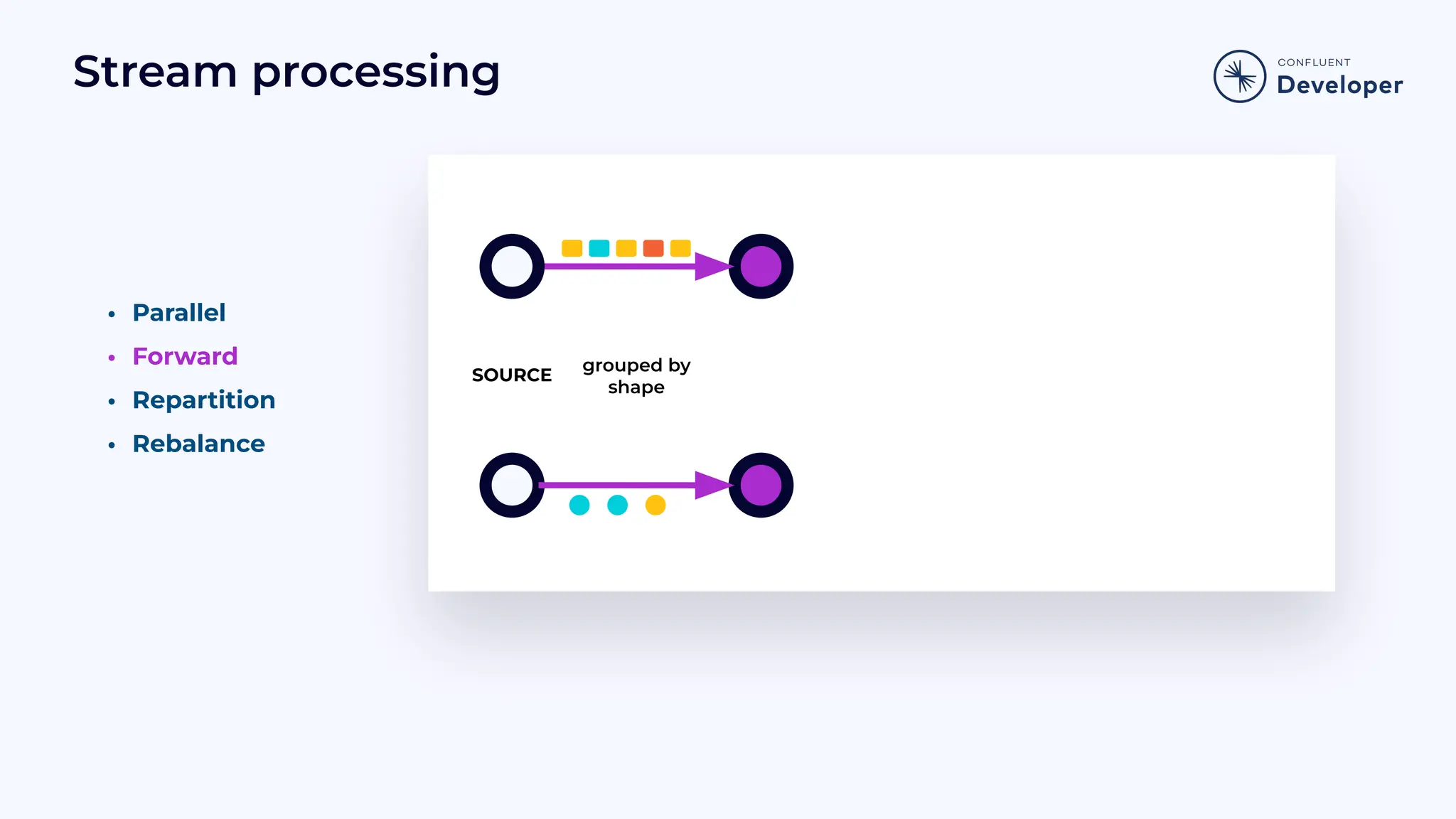
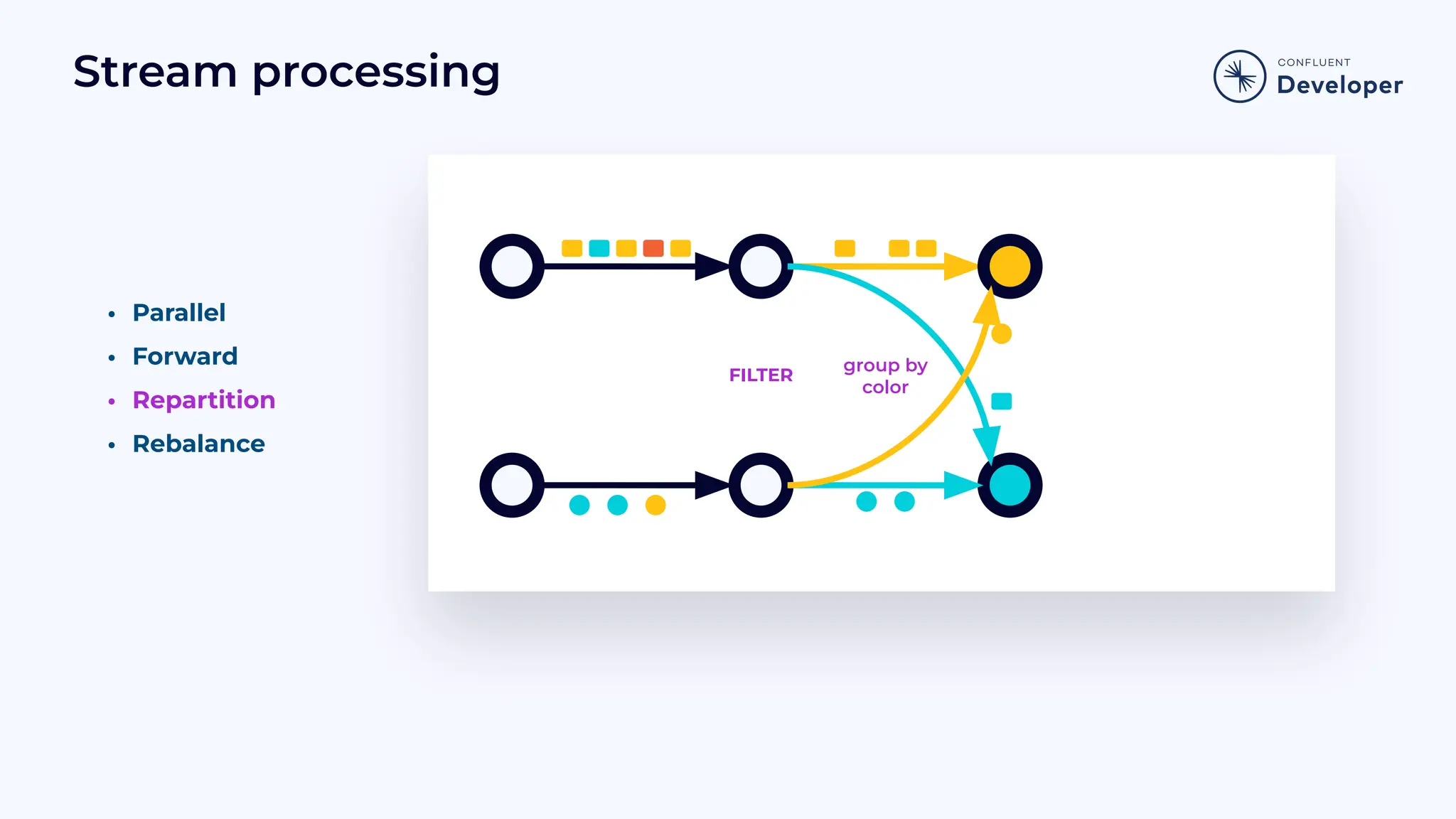
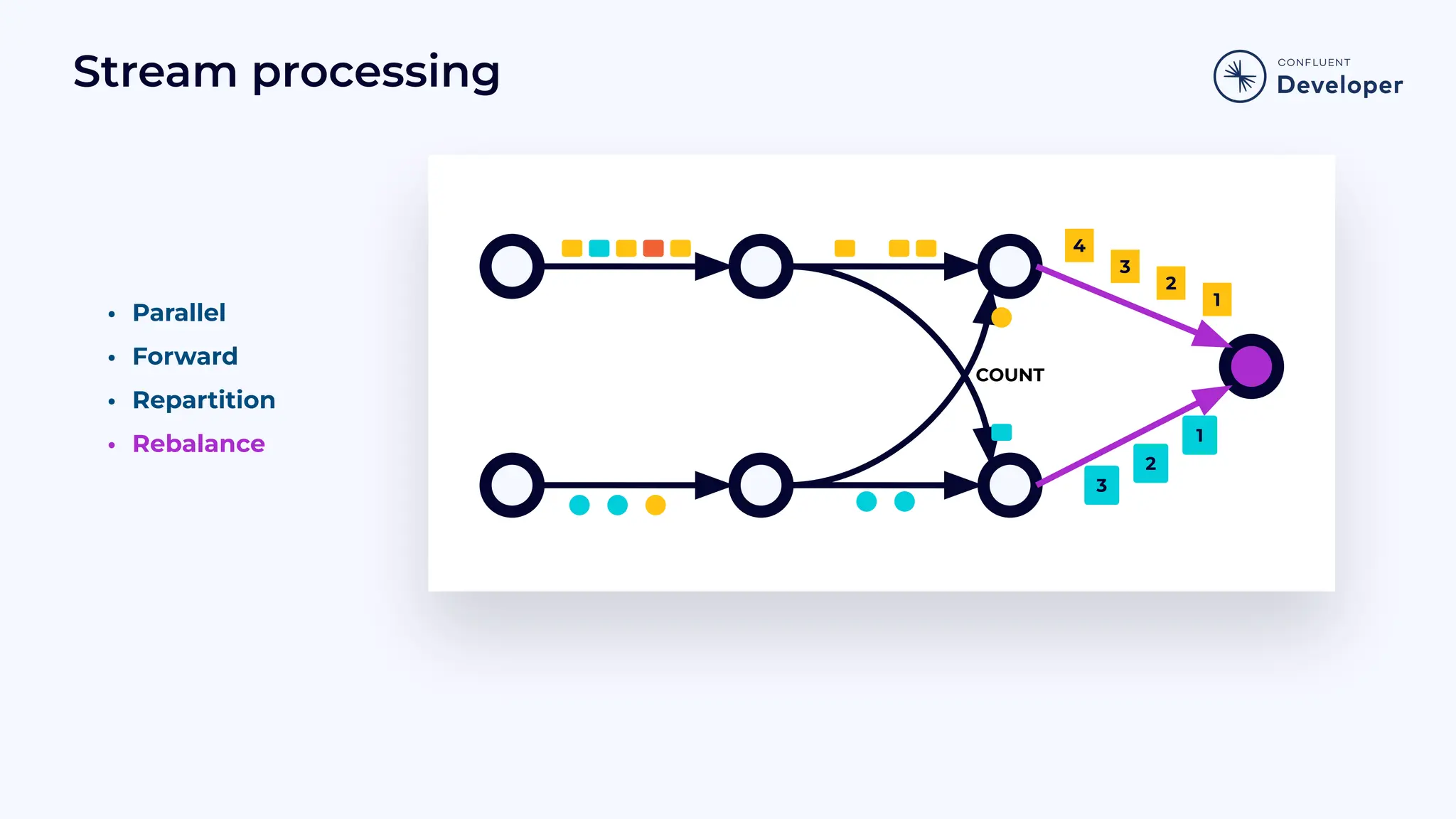
Introduces the Job Graph or topology, focusing on its structure, operators, and how it functions in stream processing.
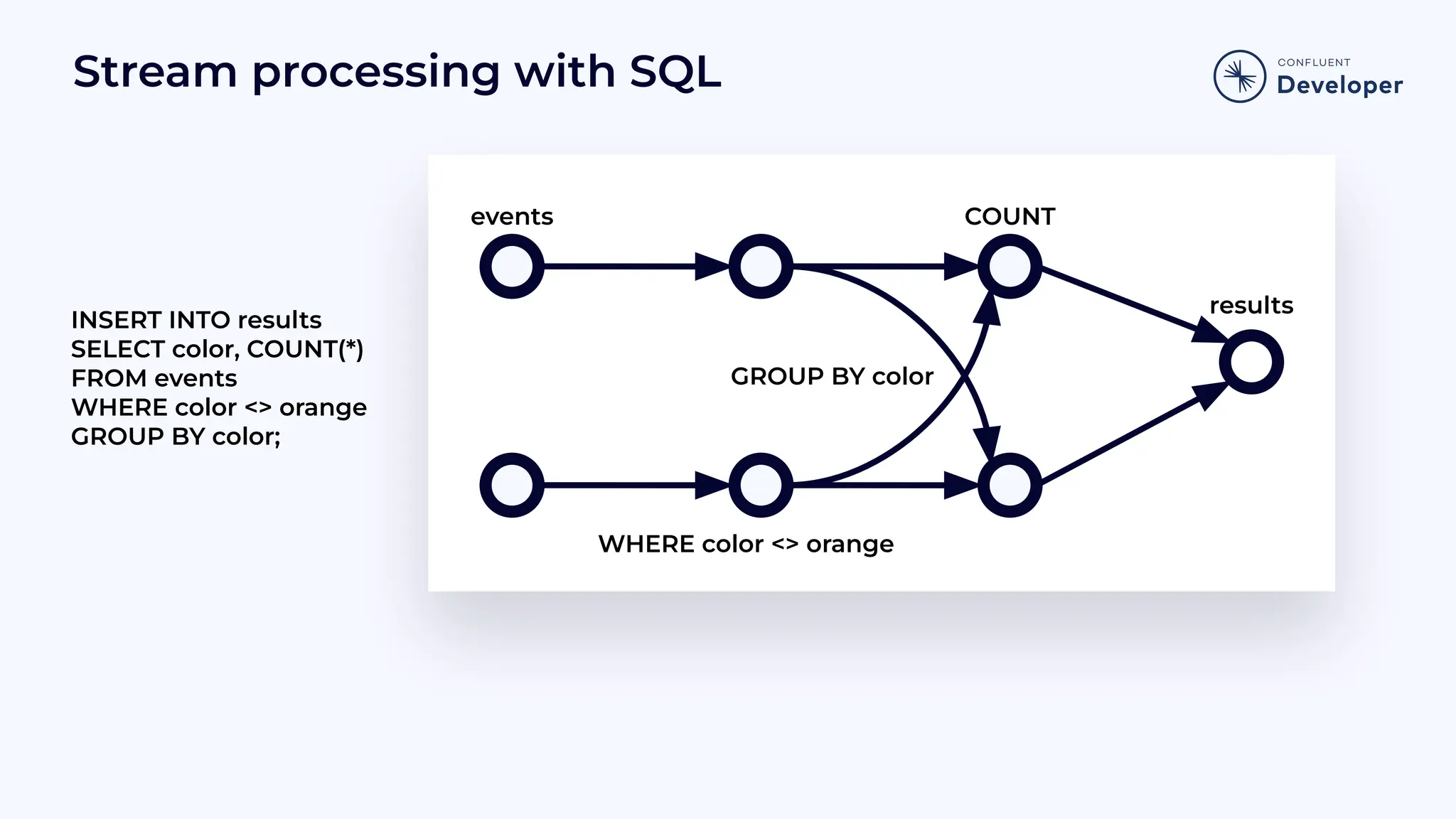
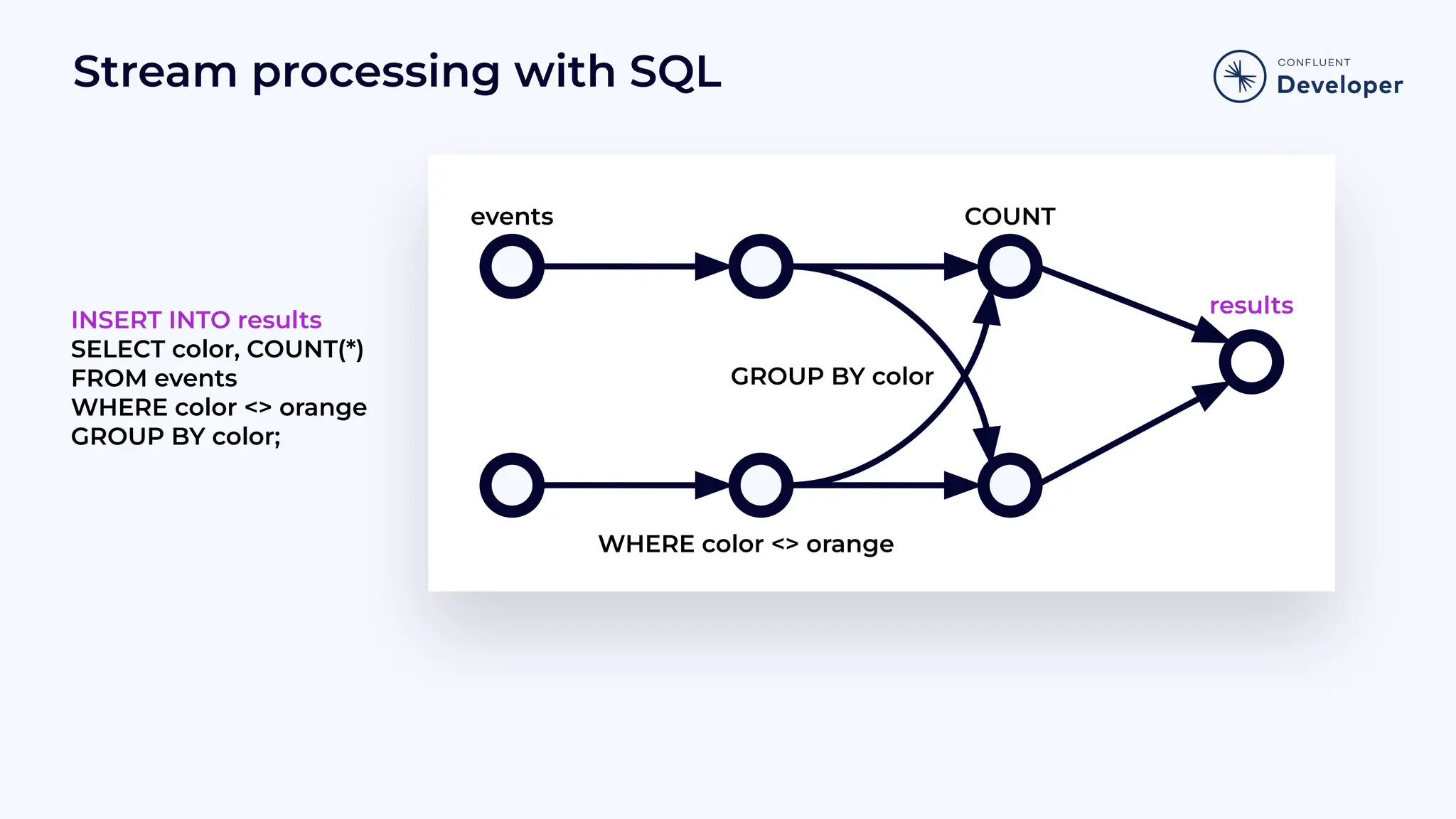
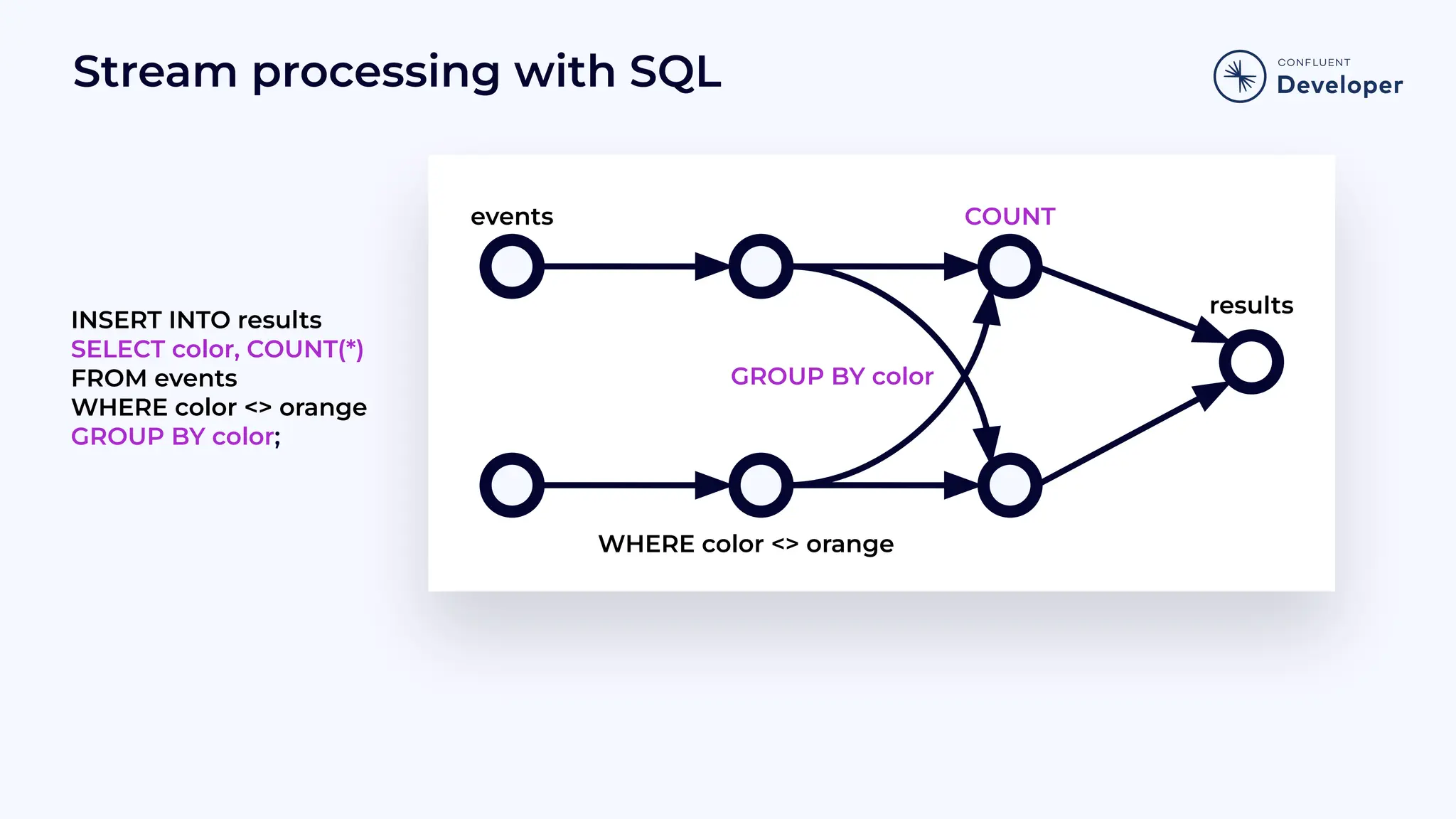
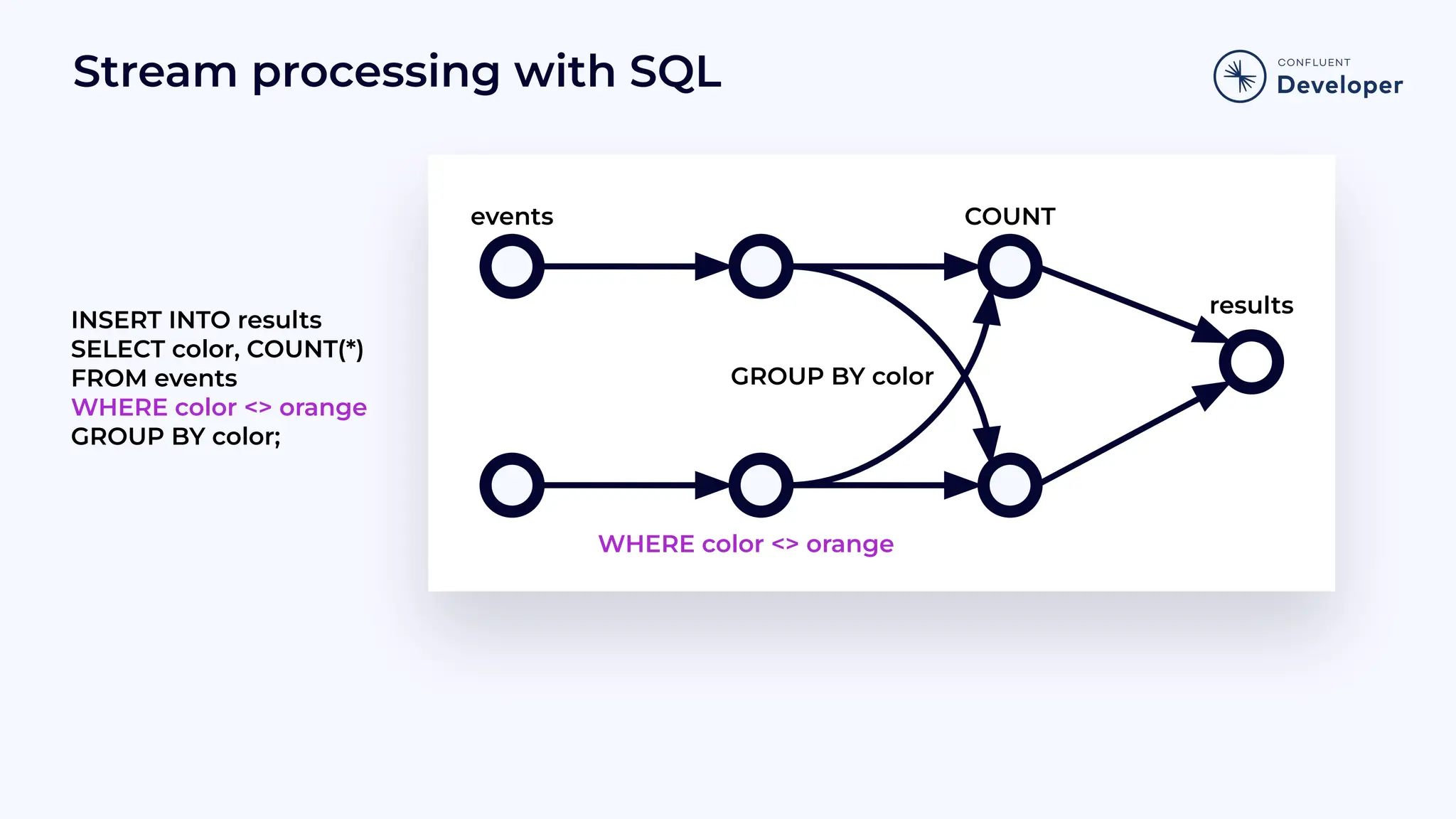
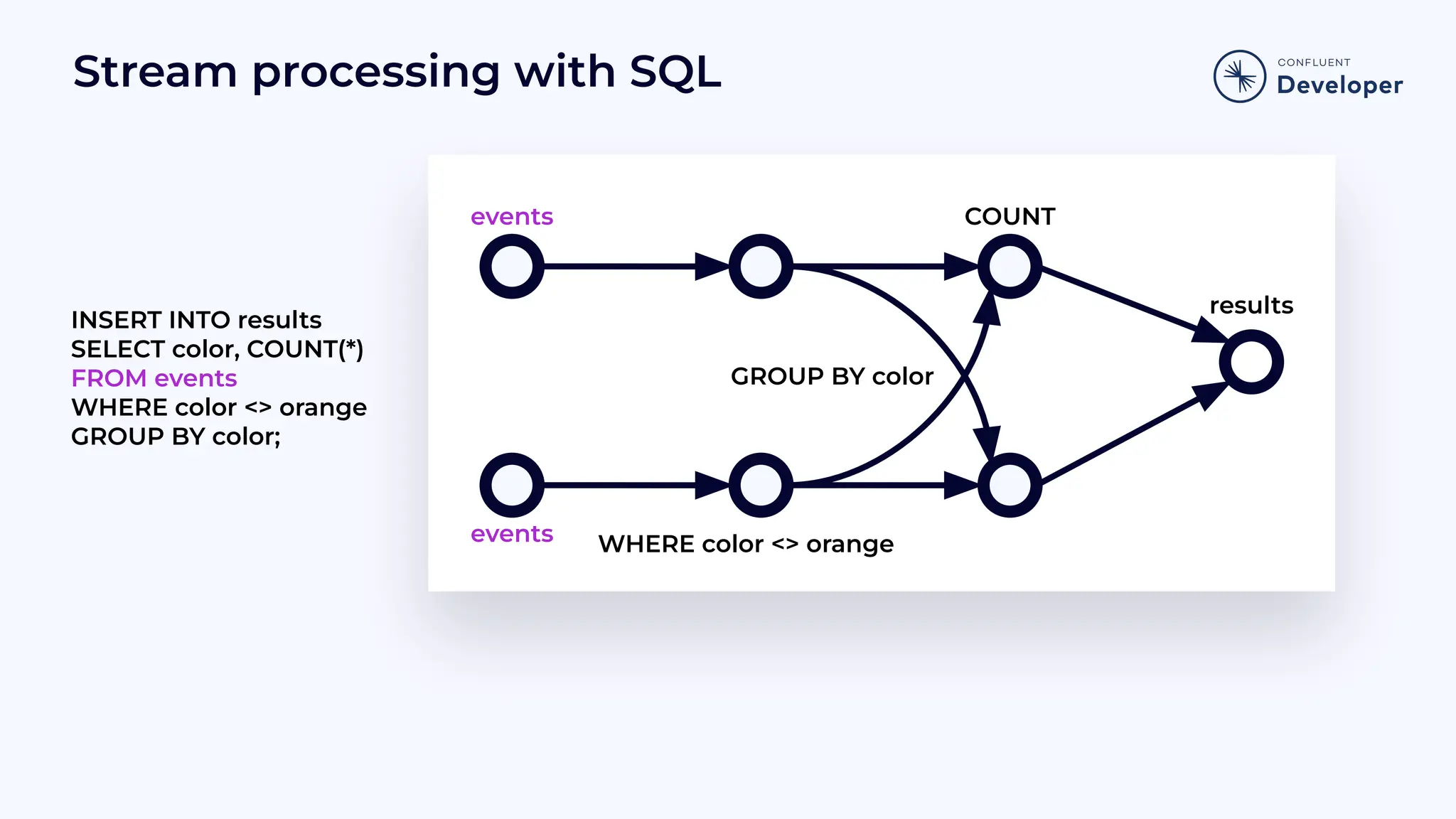
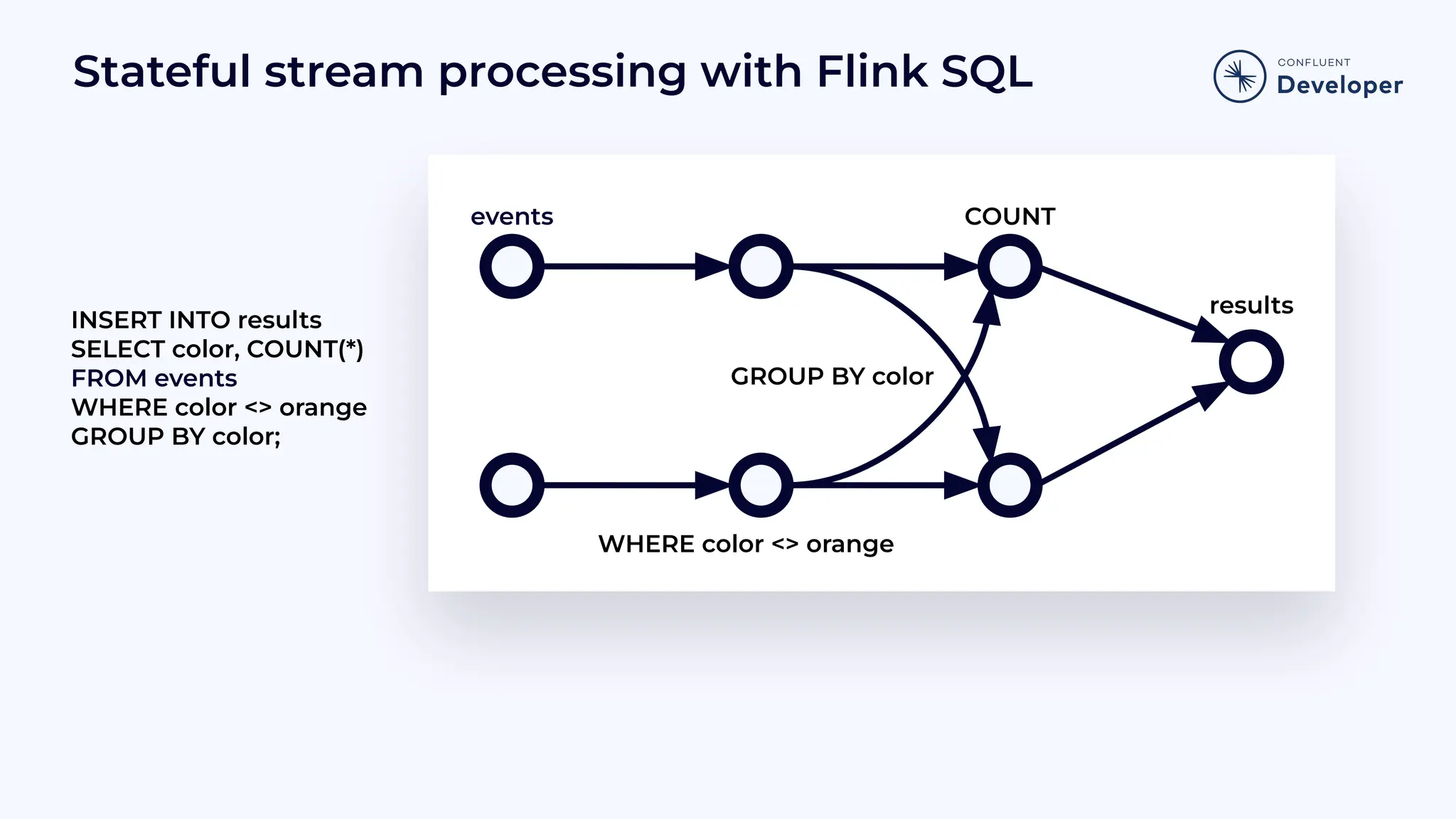
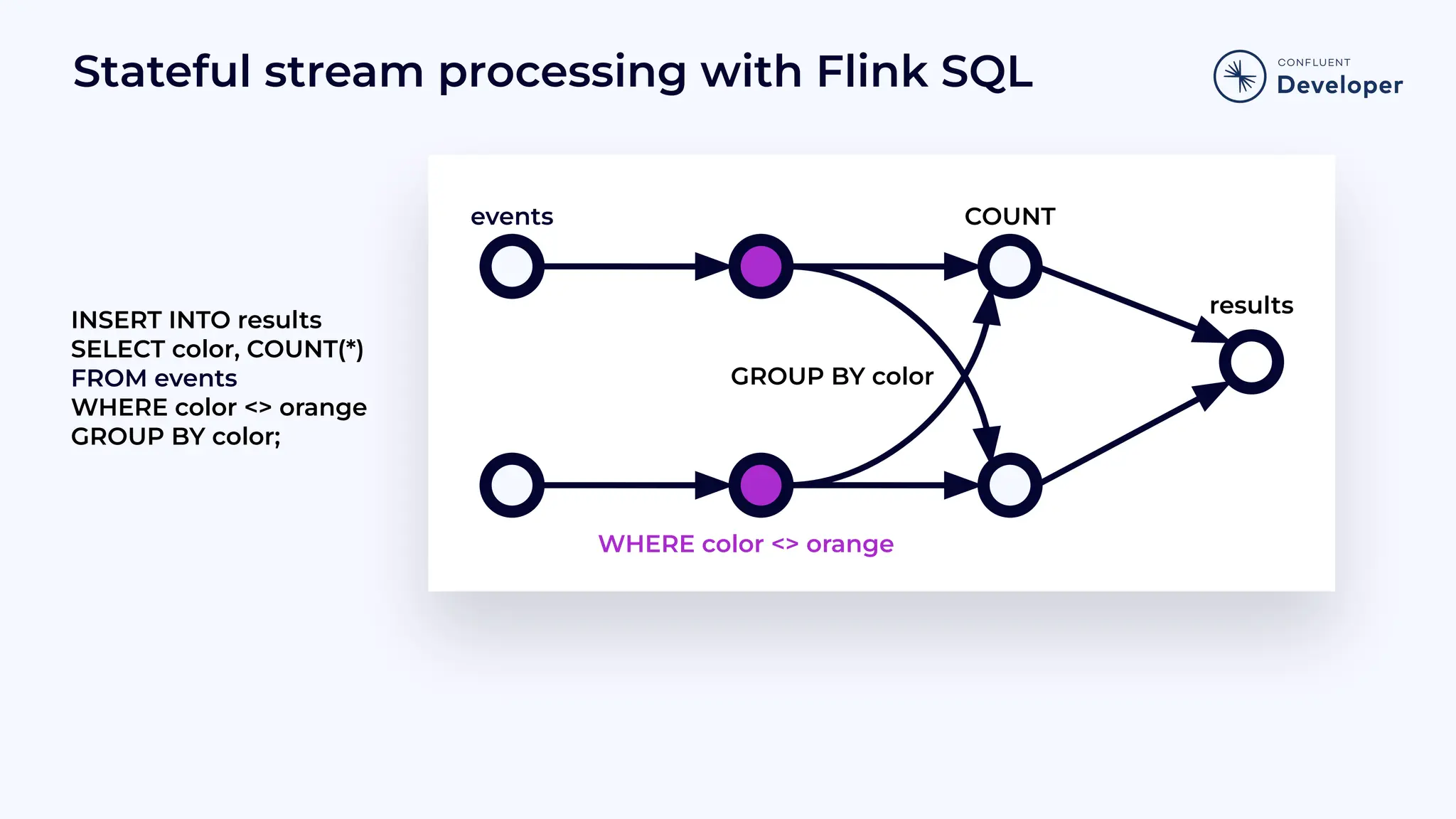
Demonstrates how SQL can be used in stream processing, showing insertion and selection operations with examples.
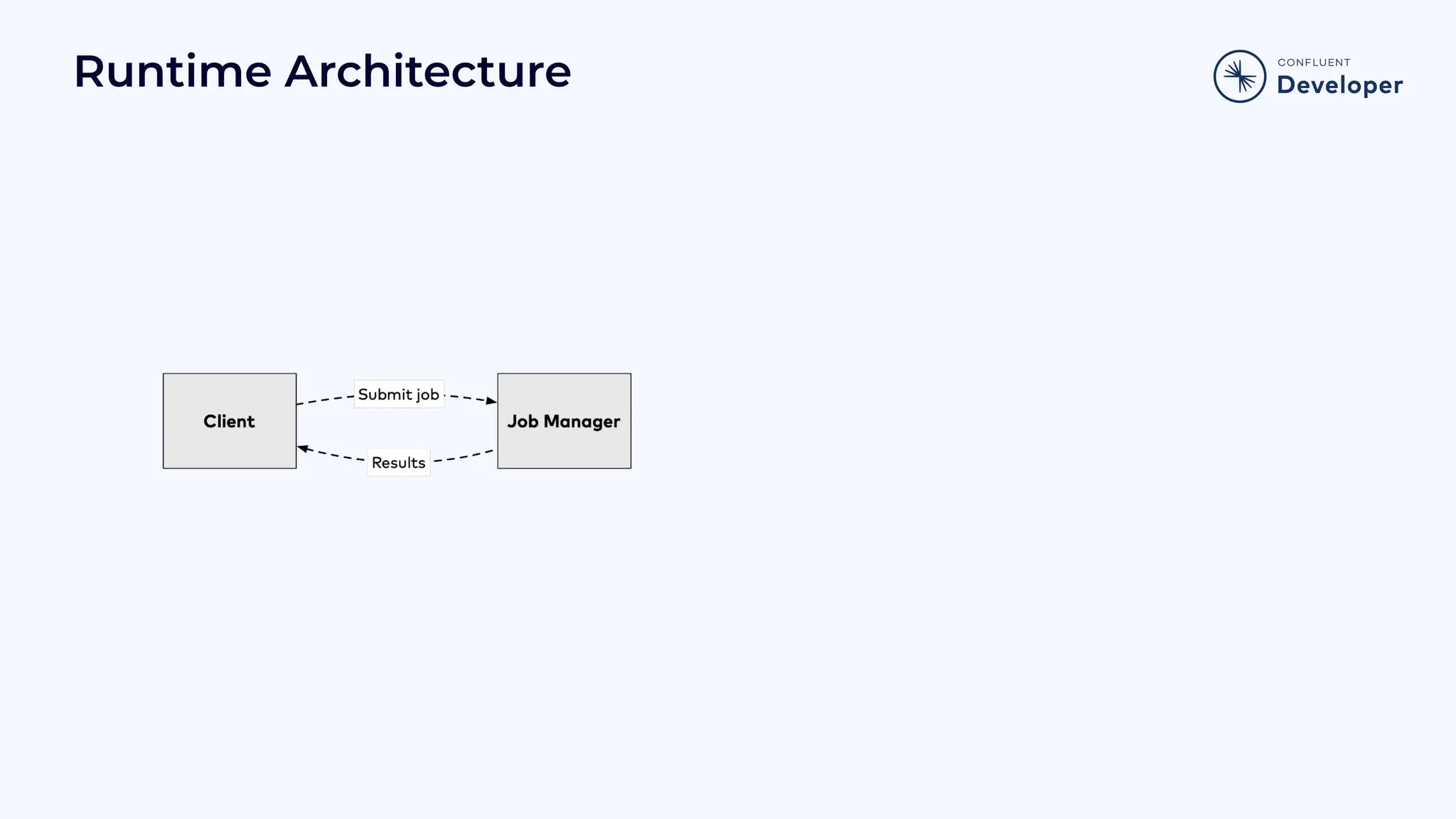
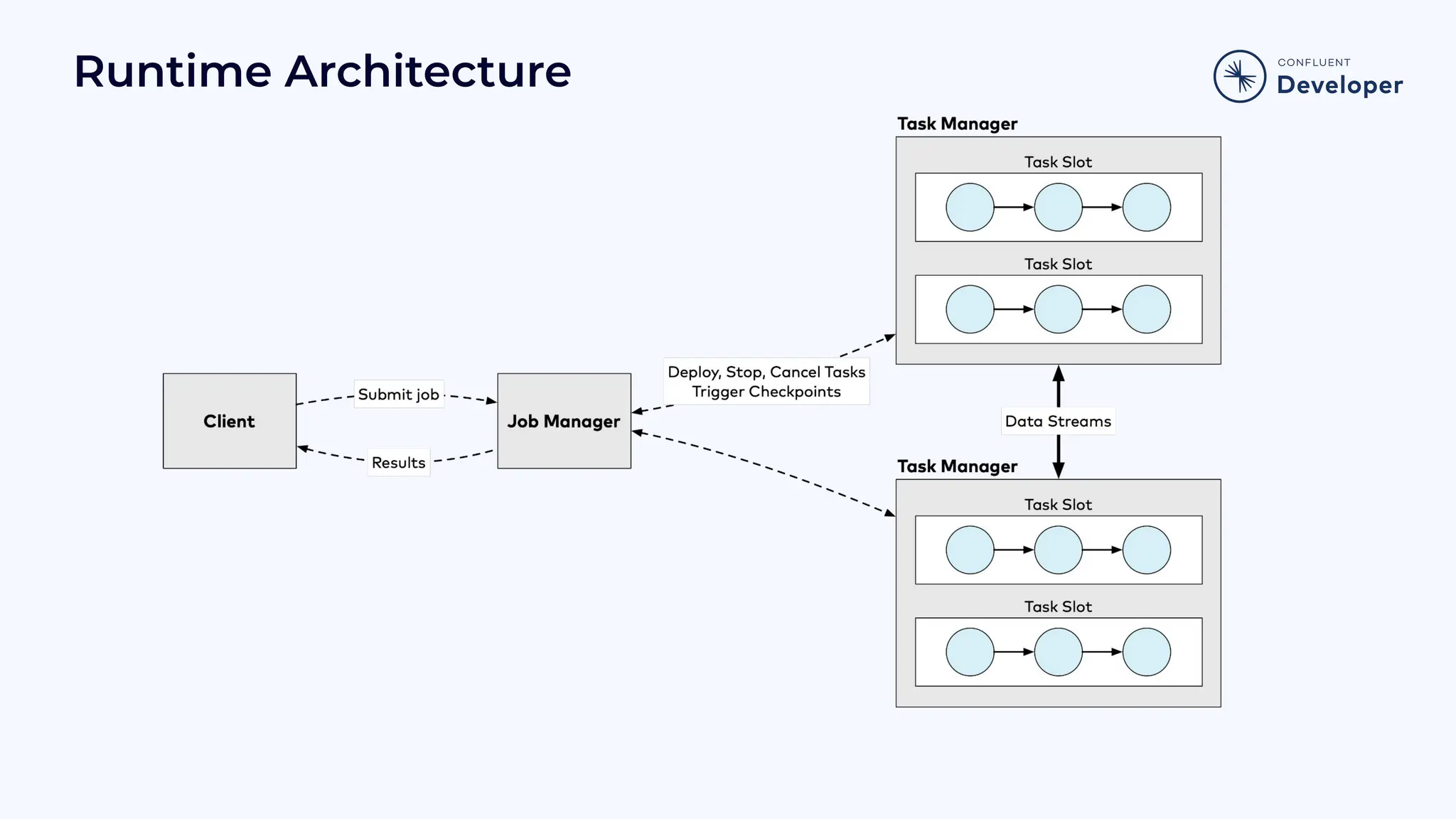
Explains Flink’s runtime architecture, including bounded/unbounded stream management and system guarantees.
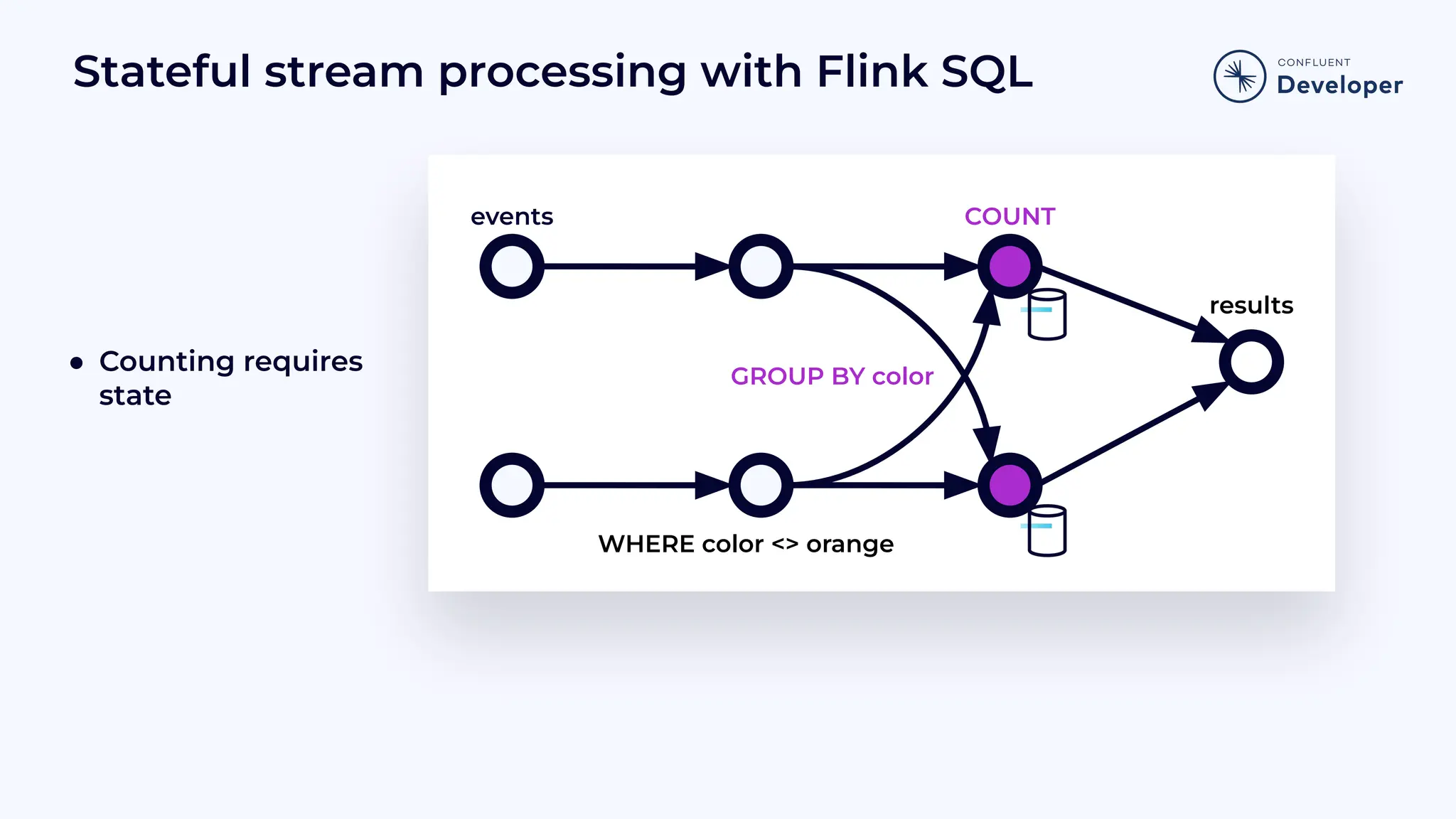
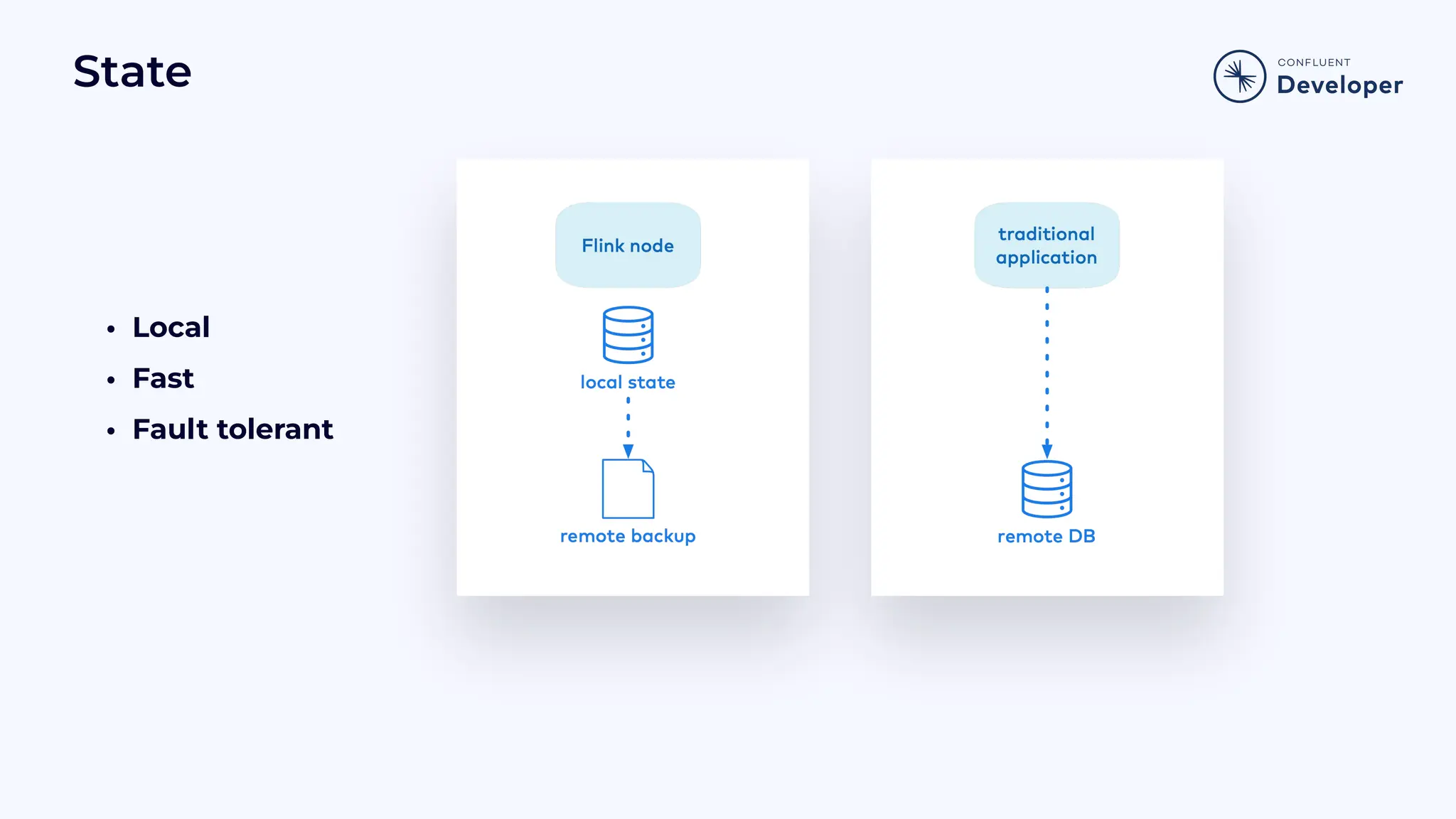
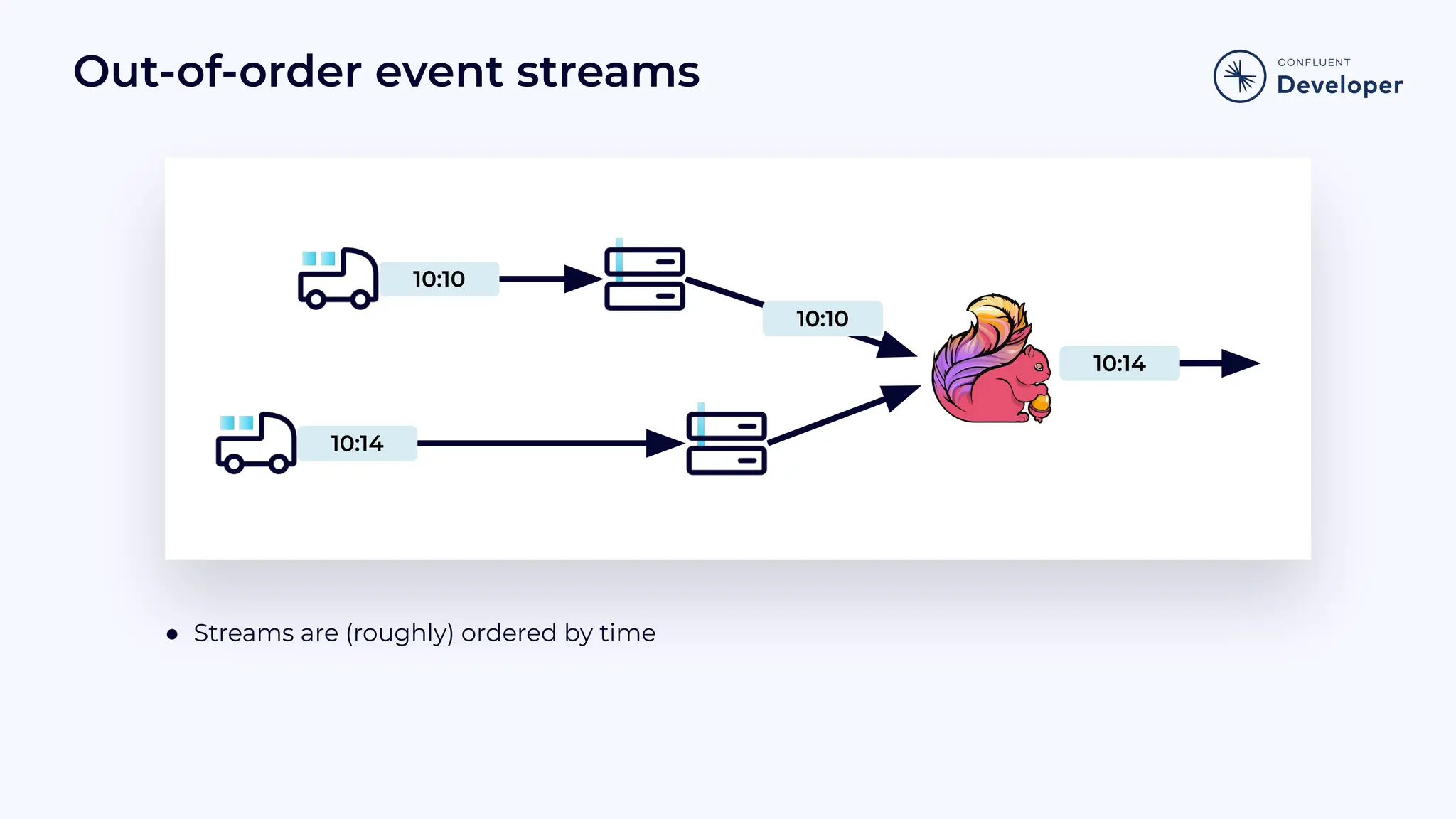
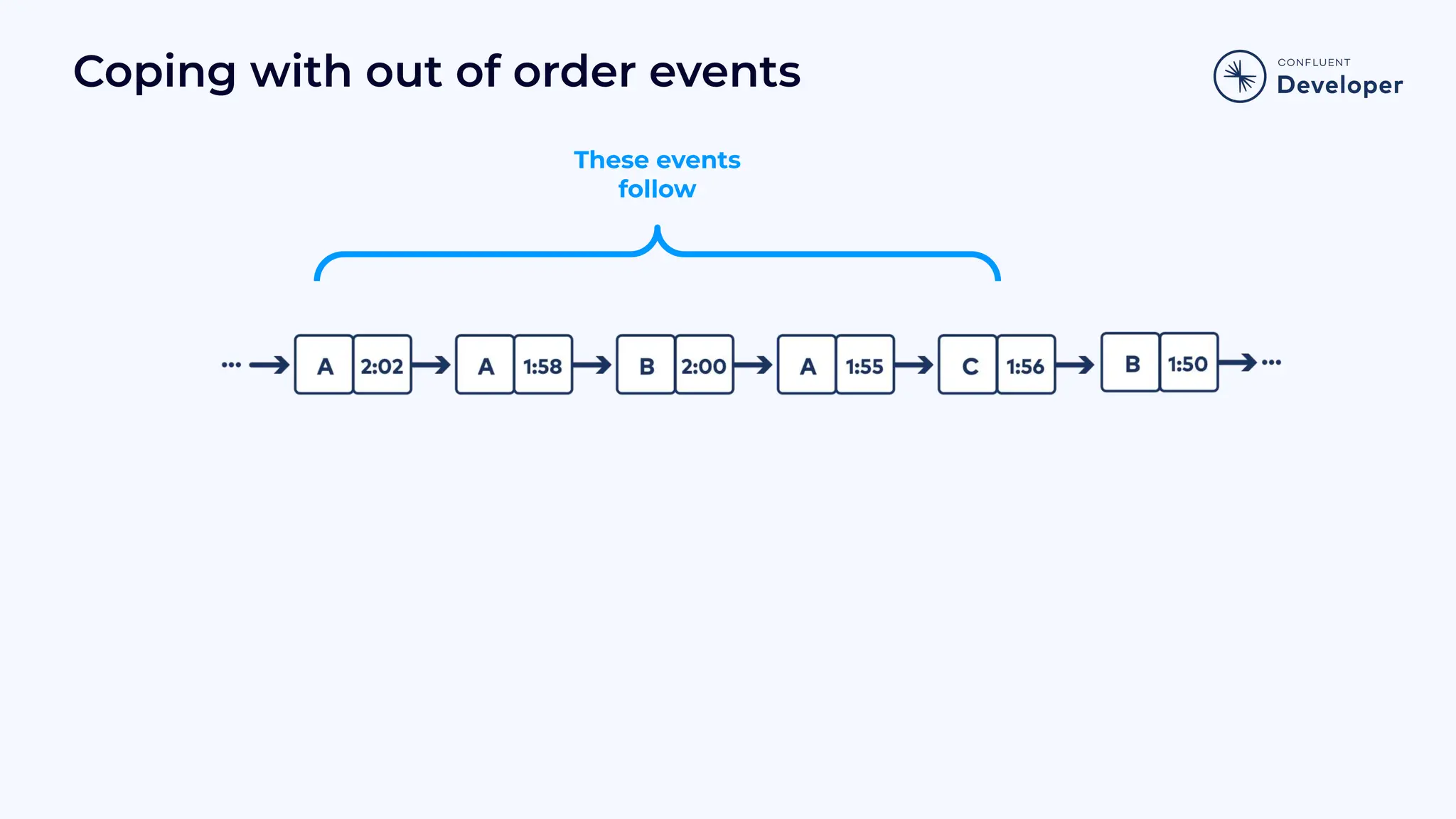
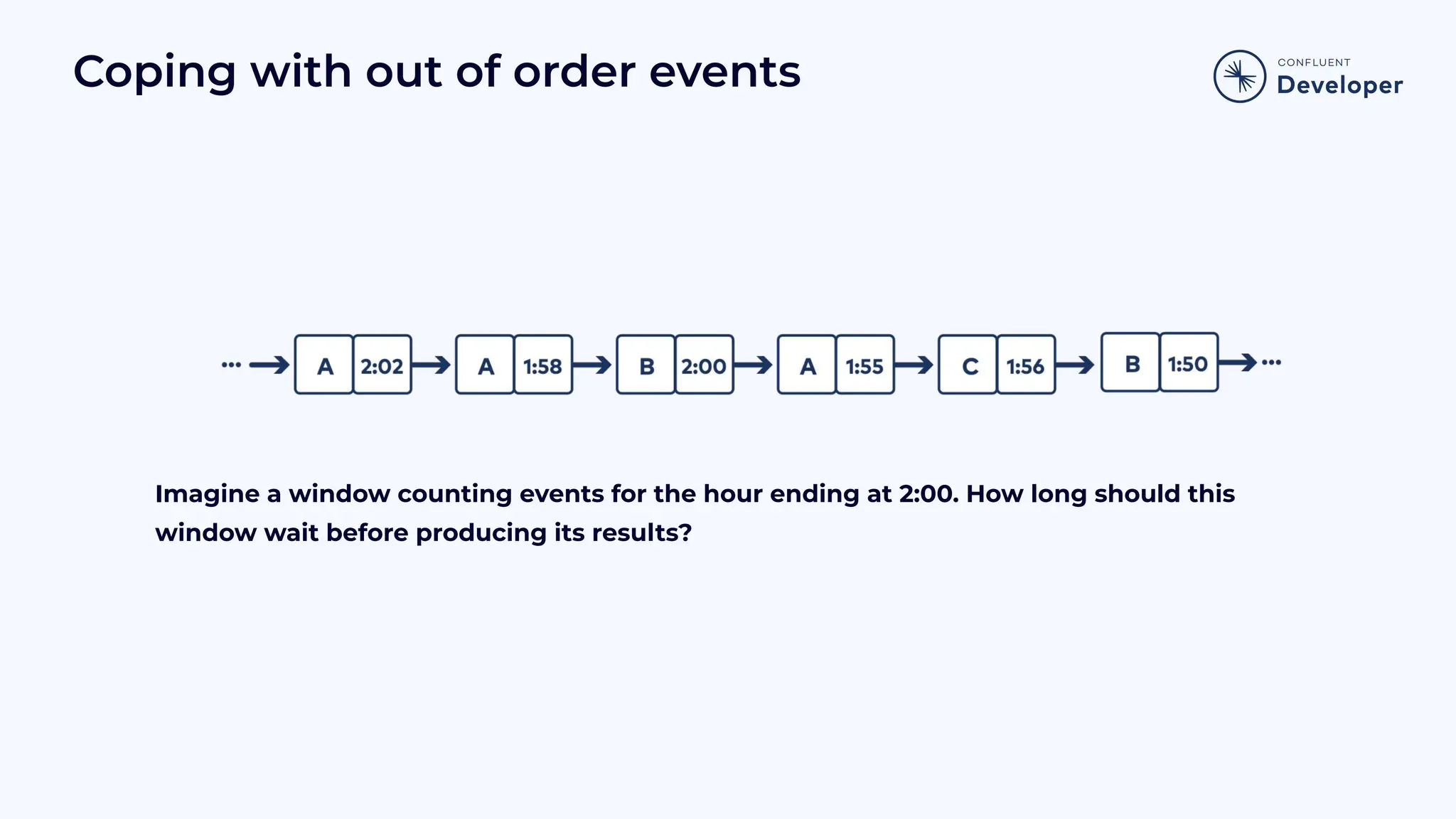
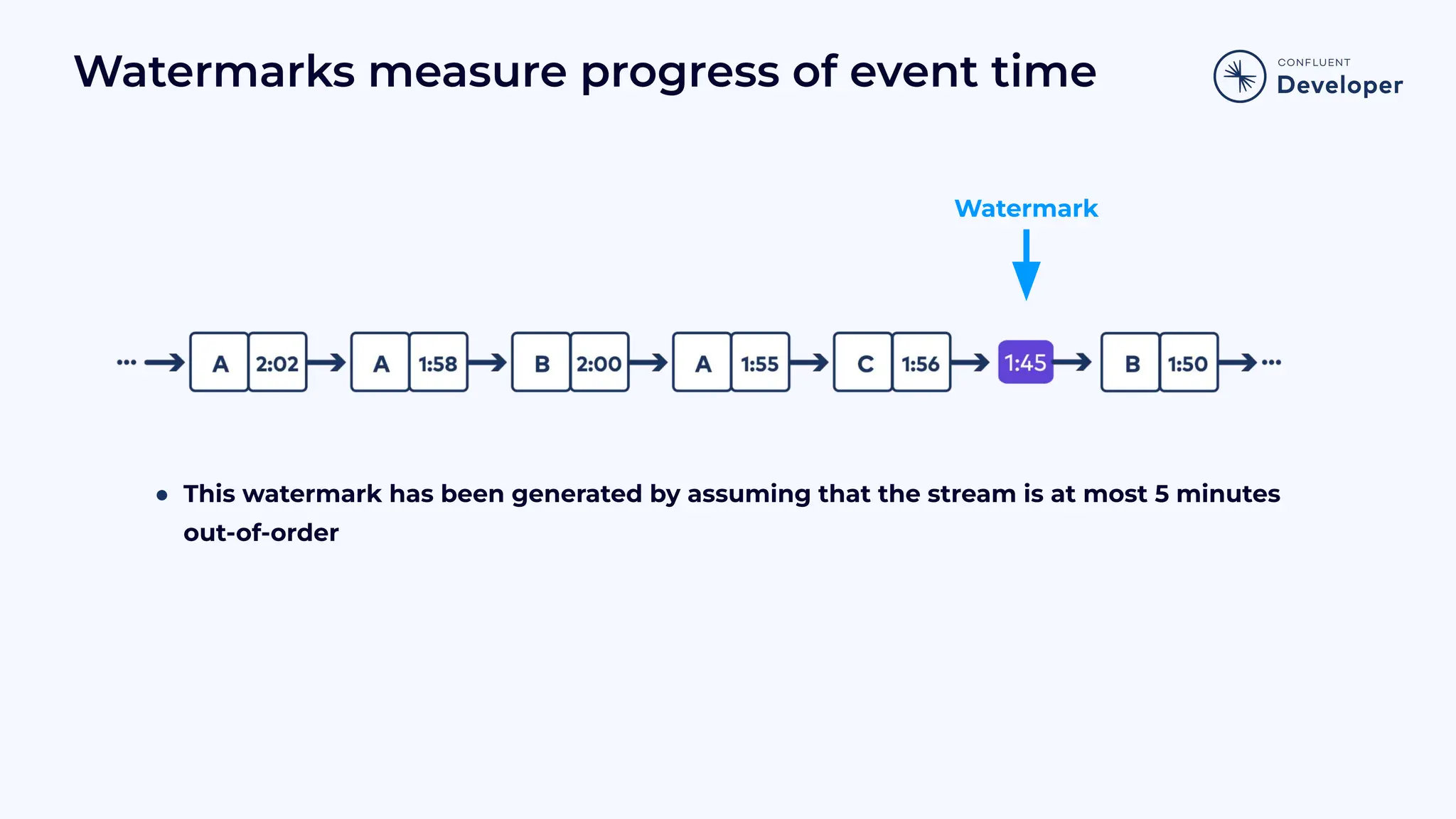
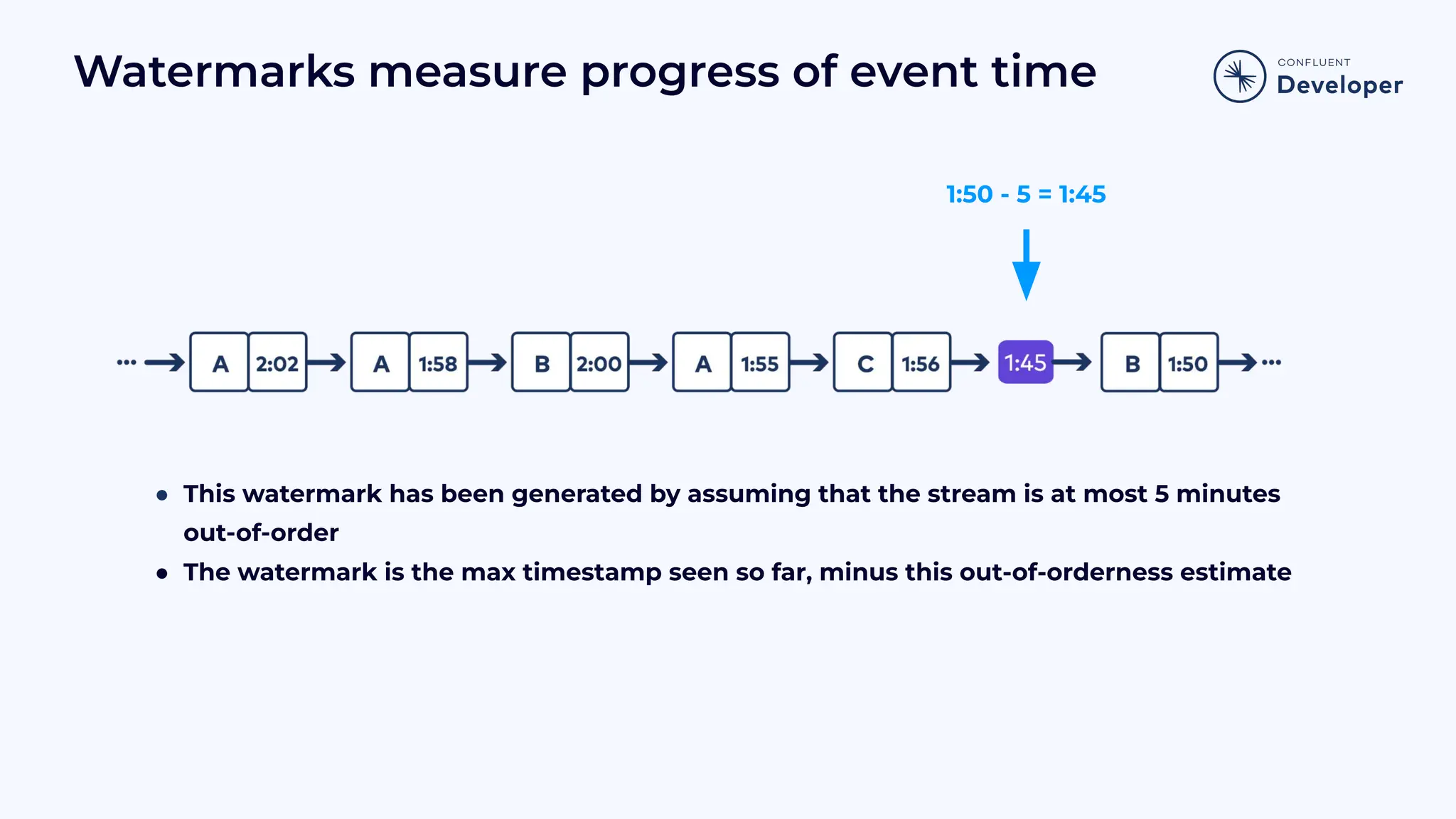
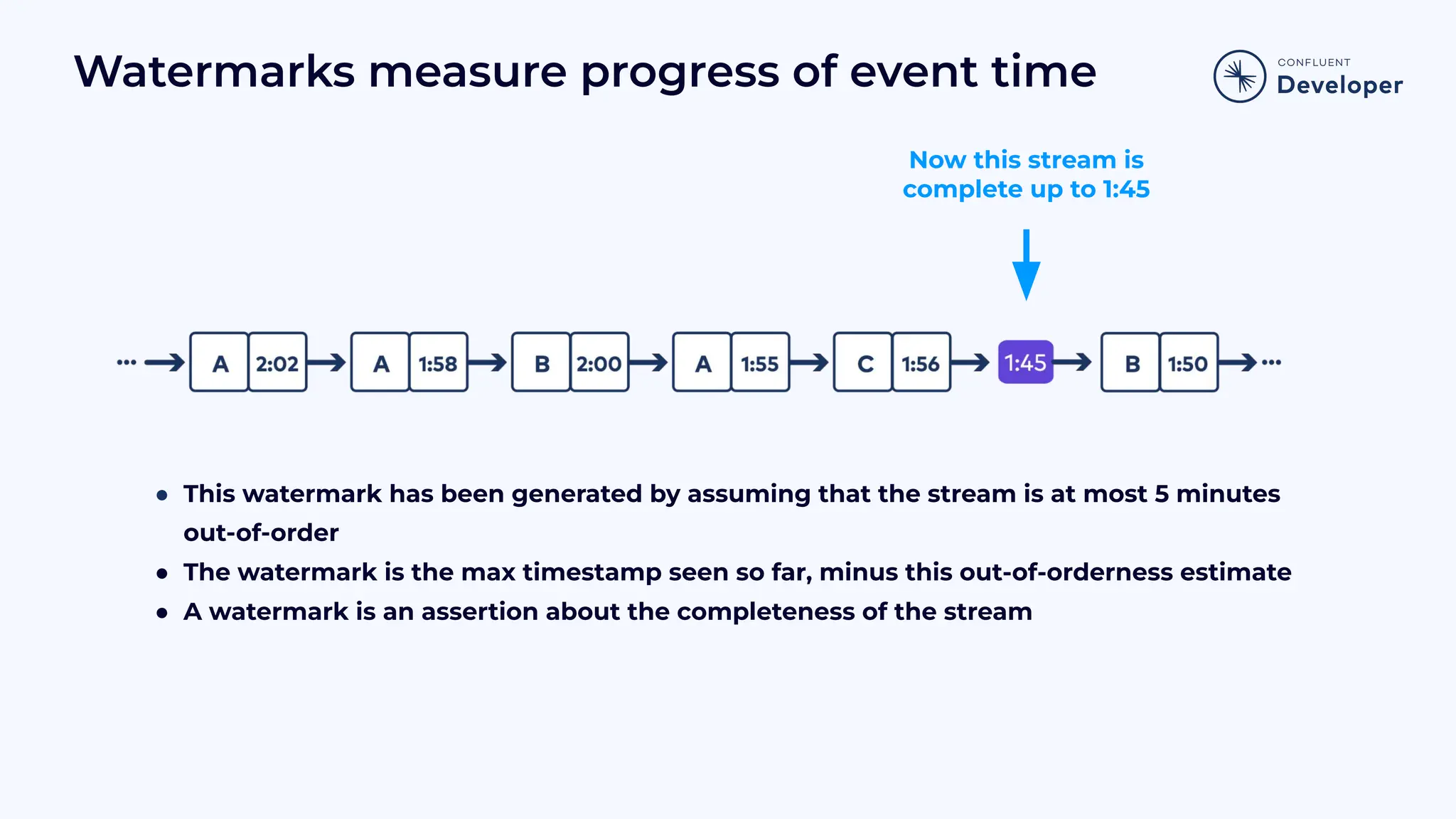
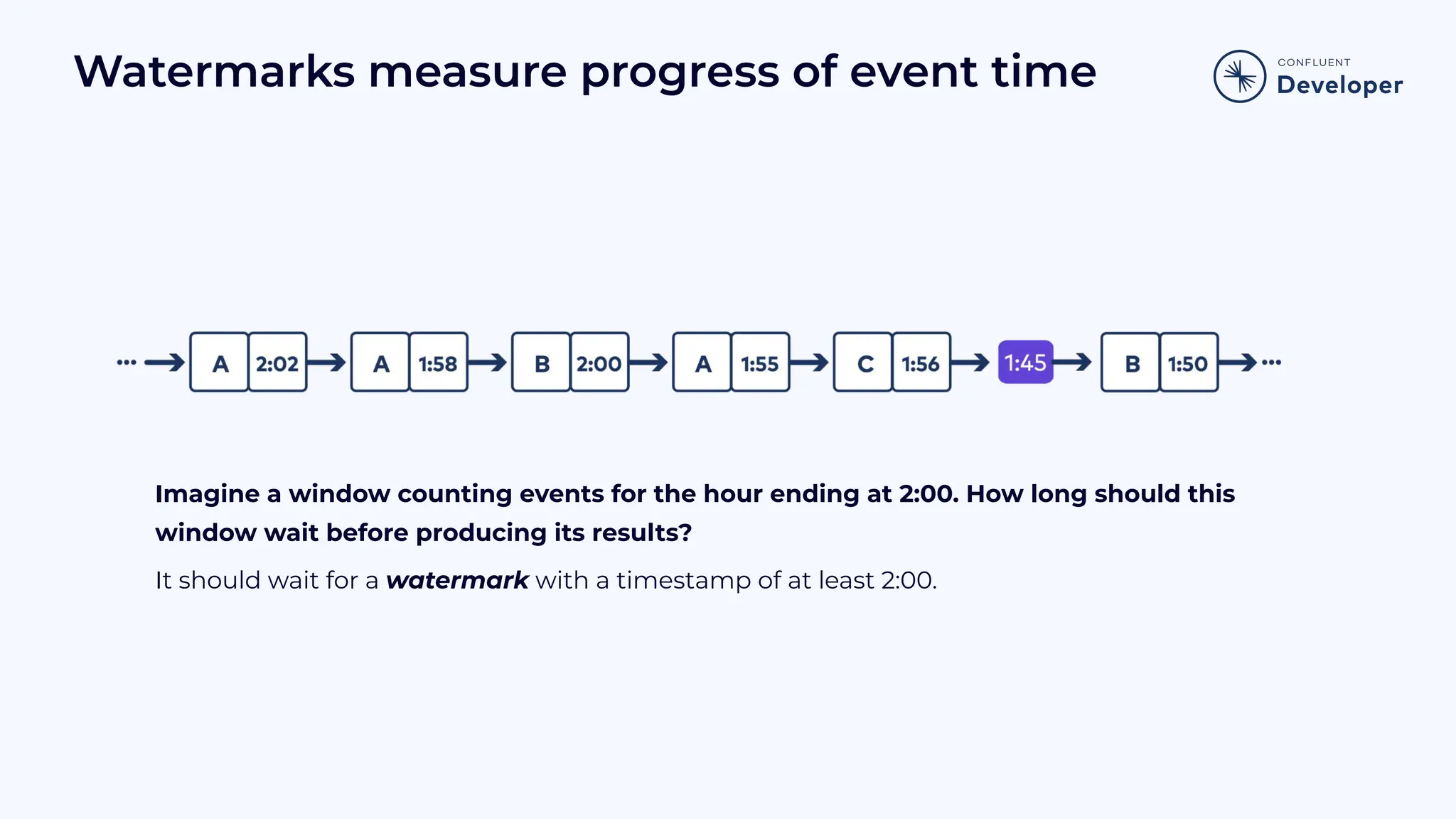
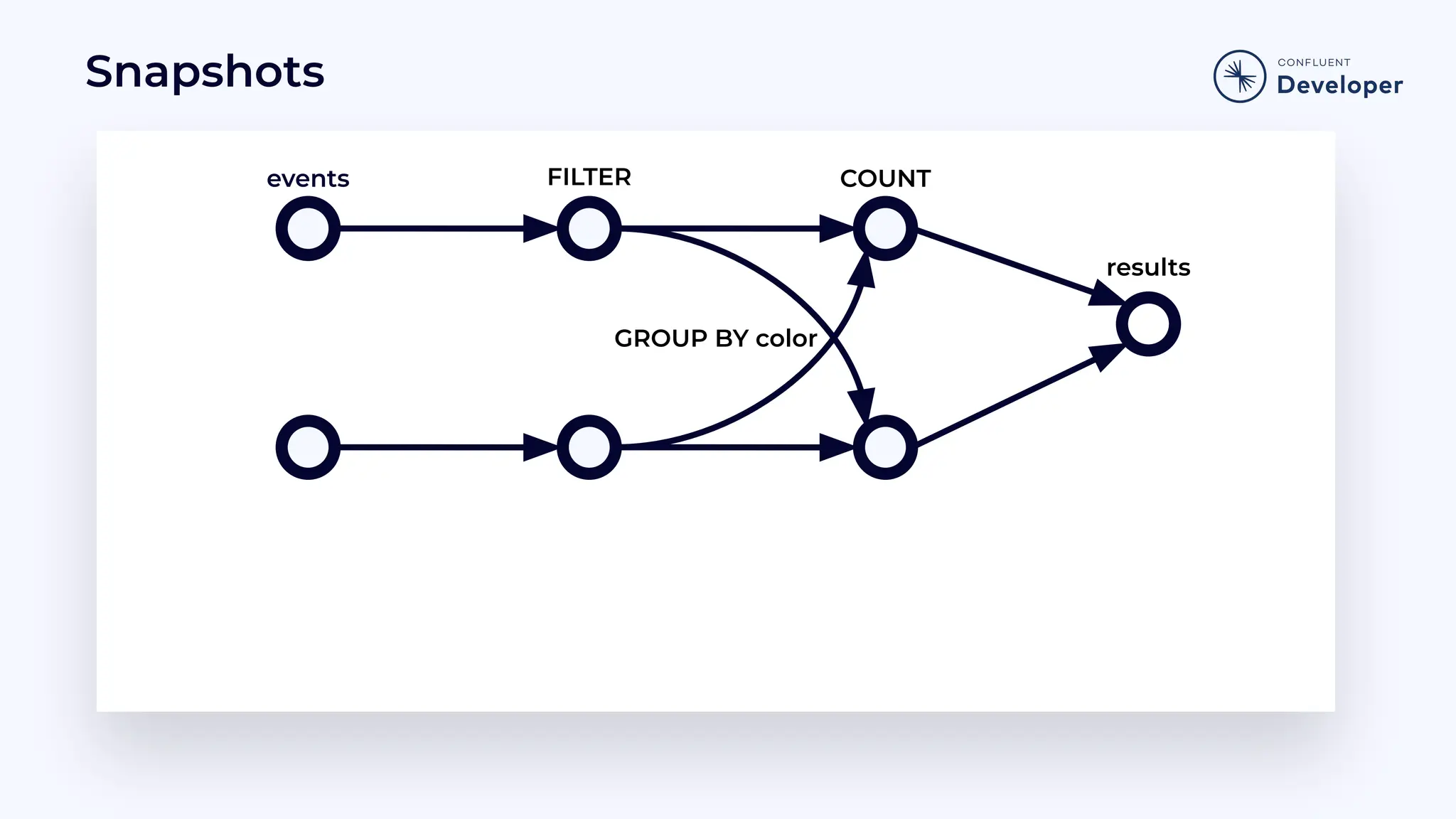
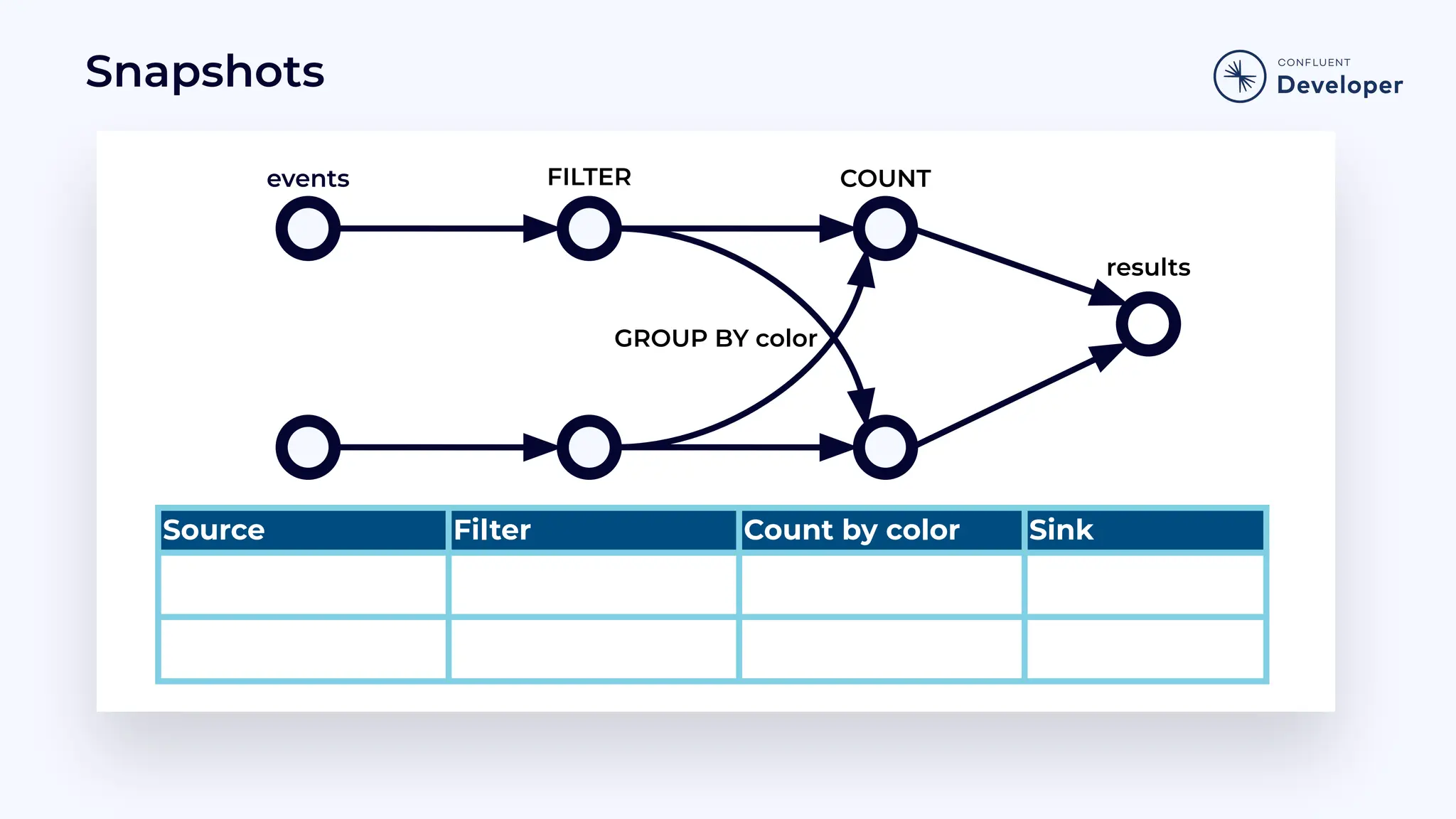
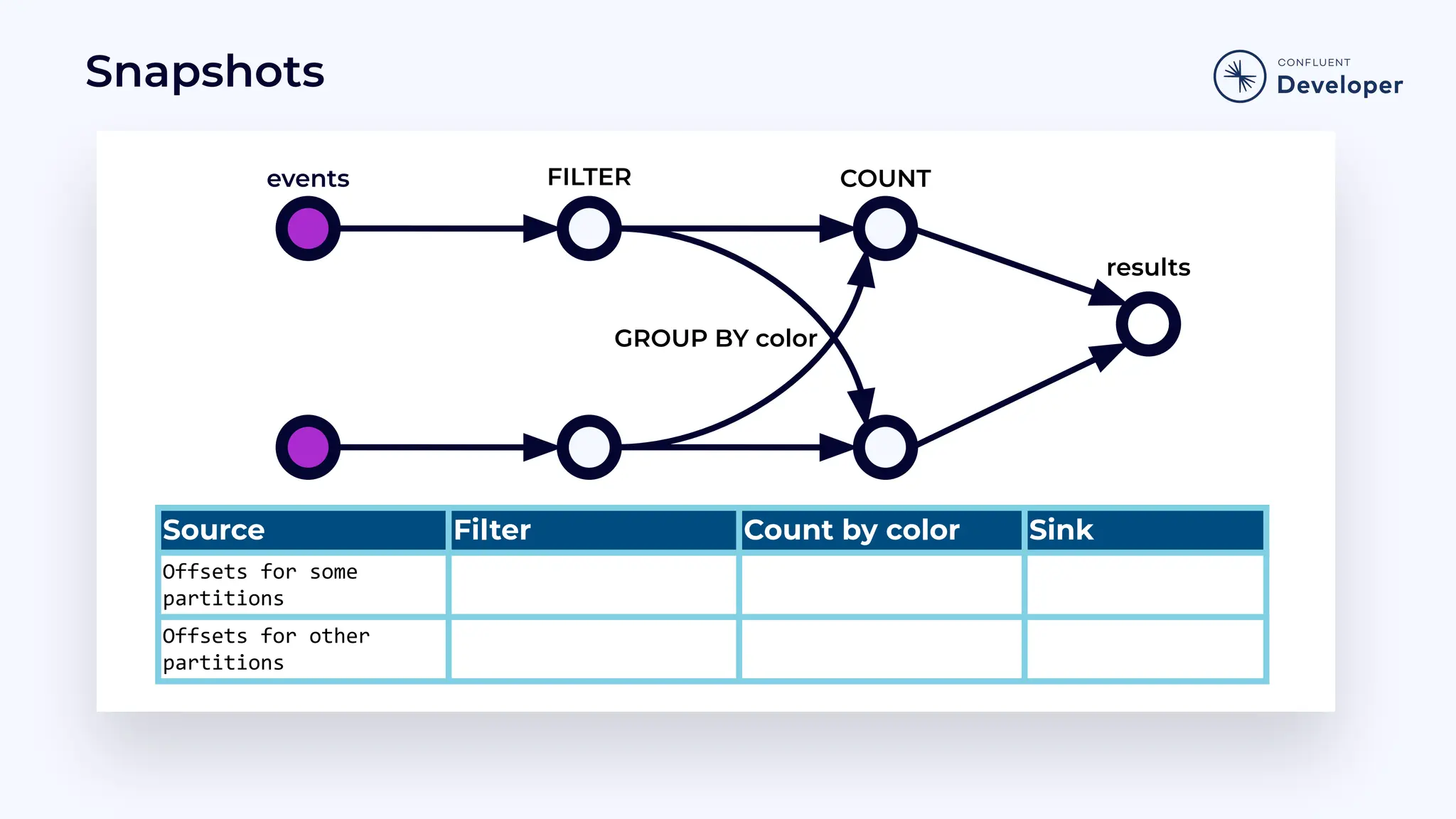
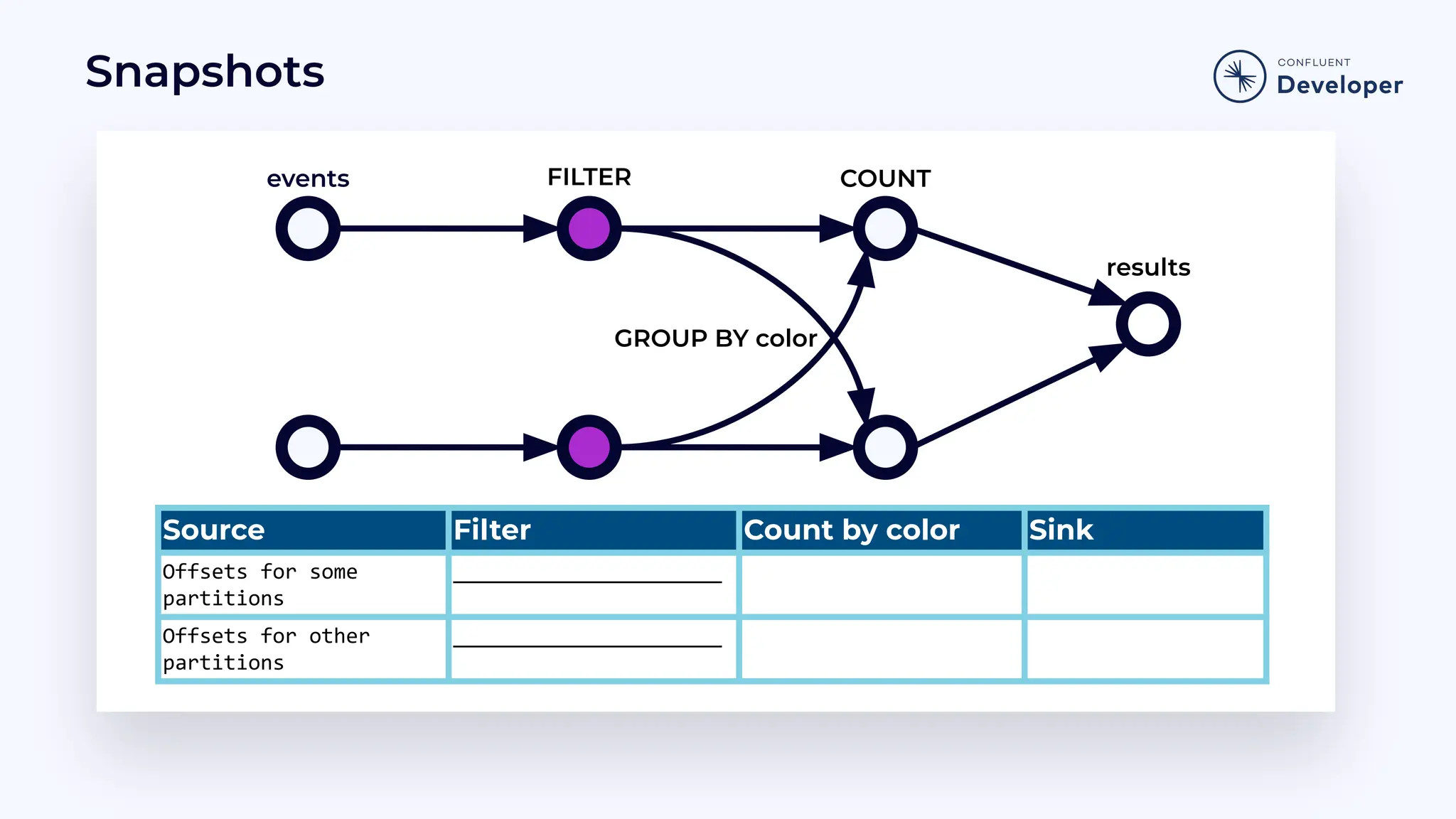
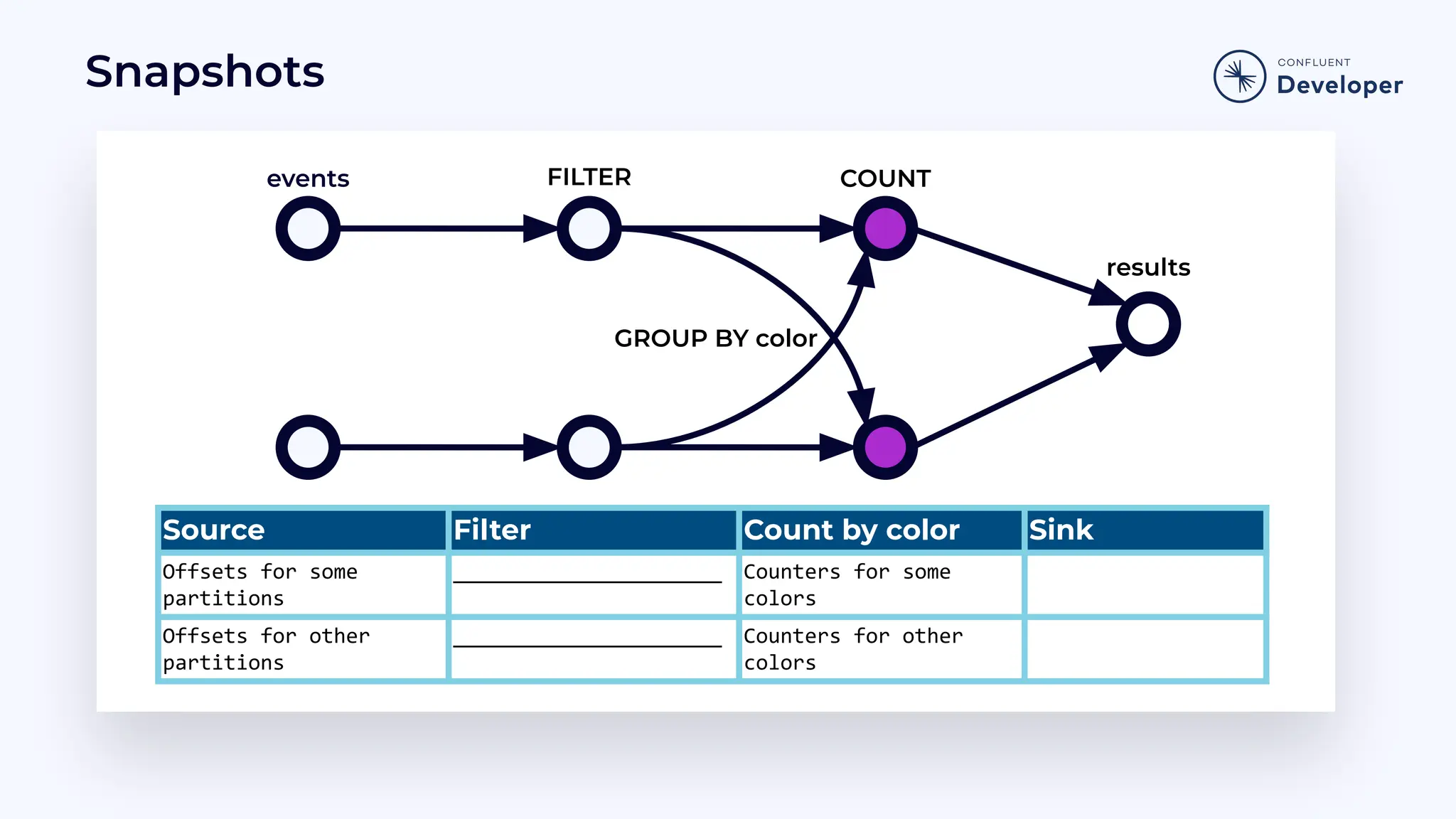
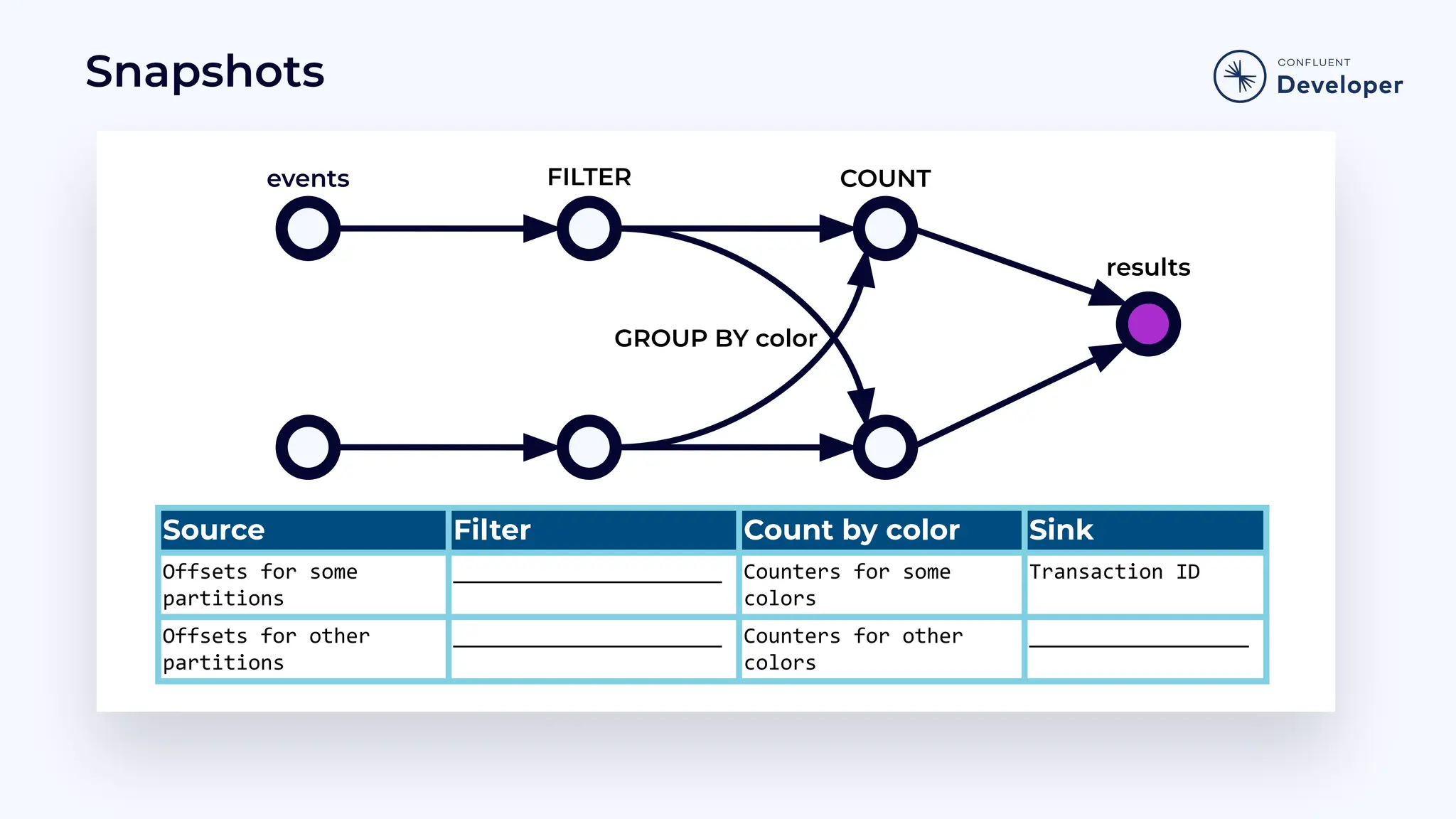
Discusses stateful processing, the use of snapshots for recovery, and the handling of out-of-order events and watermarks.
Concludes the presentation, emphasizing the simplicity of stream processing with Flink and fostering community engagement opportunities.
Encourages new users to start their journey with Apache Flink through available resources and communities.