Downloaded 64 times


![1. Dataset Loading: Pandas Hichem Felouat - hichemfel@gmail.com 3 import pandas as pd df = pd.DataFrame( {“a” : [4, 5, 6], “b” : [7, 8, 9], “c” : [10, 11, 12]}, index = [1, 2, 3]) a b c 1 4 7 10 2 5 8 11 3 6 9 12](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-3-2048.jpg)
![1. Dataset Loading: Pandas Read data from file 'filename.csv' import pandas as pd data = pd.read_csv("filename.csv") print (data) Select only the feature_1 and feature_2 columns df = pd.DataFrame(data, columns= ['feature_1',' feature_2 ']) print (df) Hichem Felouat - hichemfel@gmail.com 4 Data Exploration # Using head() method with an argument which helps us to restrict the number of initial records that should be displayed data.head(n=2) # Using .tail() method with an argument which helps us to restrict the number of initial records that should be displayed data.tail(n=2)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-4-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 5 1. Dataset Loading: Pandas Training Set & Test Set columns = [' ', ... , ' '] # n -1 my_data = data[columns ] # assigning the 'col_i ' column as target target = data['col_i ' ] data.head(n=2) Read and Write to CSV & Excel df = pd.read_csv('file.csv') df.to_csv('myDataFrame.csv') df = pd.read_excel('file.xlsx') df.to_excel('myDataFrame.xlsx')](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-5-2048.jpg)





![Hichem Felouat - hichemfel@gmail.com 11 1. Dataset Loading: Scikit Learn Downloading datasets from the openml.org repository >>> from sklearn.datasets import fetch_openml >>> mice = fetch_openml(name='miceprotein', version=4) >>> mice.data.shape (1080, 77) >>> mice.target.shape (1080,) >>> np.unique(mice.target) array(['c-CS-m', 'c-CS-s', 'c-SC-m', 'c-SC-s', 't-CS-m', 't-CS-s', 't-SC-m', 't-SC-s'], dtype=object) >>> mice.url 'https://www.openml.org/d/40966' >>> mice.details['version'] '1'](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-11-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 12 1. Dataset Loading: Numpy Saving & Loading Text Files import numpy as np In [1]: a = np.array([1, 2, 3, 4]) In [2]: np.savetxt('test1.txt', a, fmt='%d') In [3]: b = np.loadtxt('test1.txt', dtype=int) In [4]: a == b Out[4]: array([ True, True, True, True], dtype=bool) # write and read binary files In [5]: a.tofile('test2.dat') In [6]: c = np.fromfile('test2.dat', dtype=int) In [7]: c == a Out[7]: array([ True, True, True, True], dtype=bool)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-12-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 13 1. Dataset Loading: Numpy Saving & Loading On Disk import numpy as np # .npy extension is added if not given In [8]: np.save('test3.npy', a) In [9]: d = np.load('test3.npy') In [10]: a == d Out[10]: array([ True, True, True, True], dtype=bool)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-13-2048.jpg)
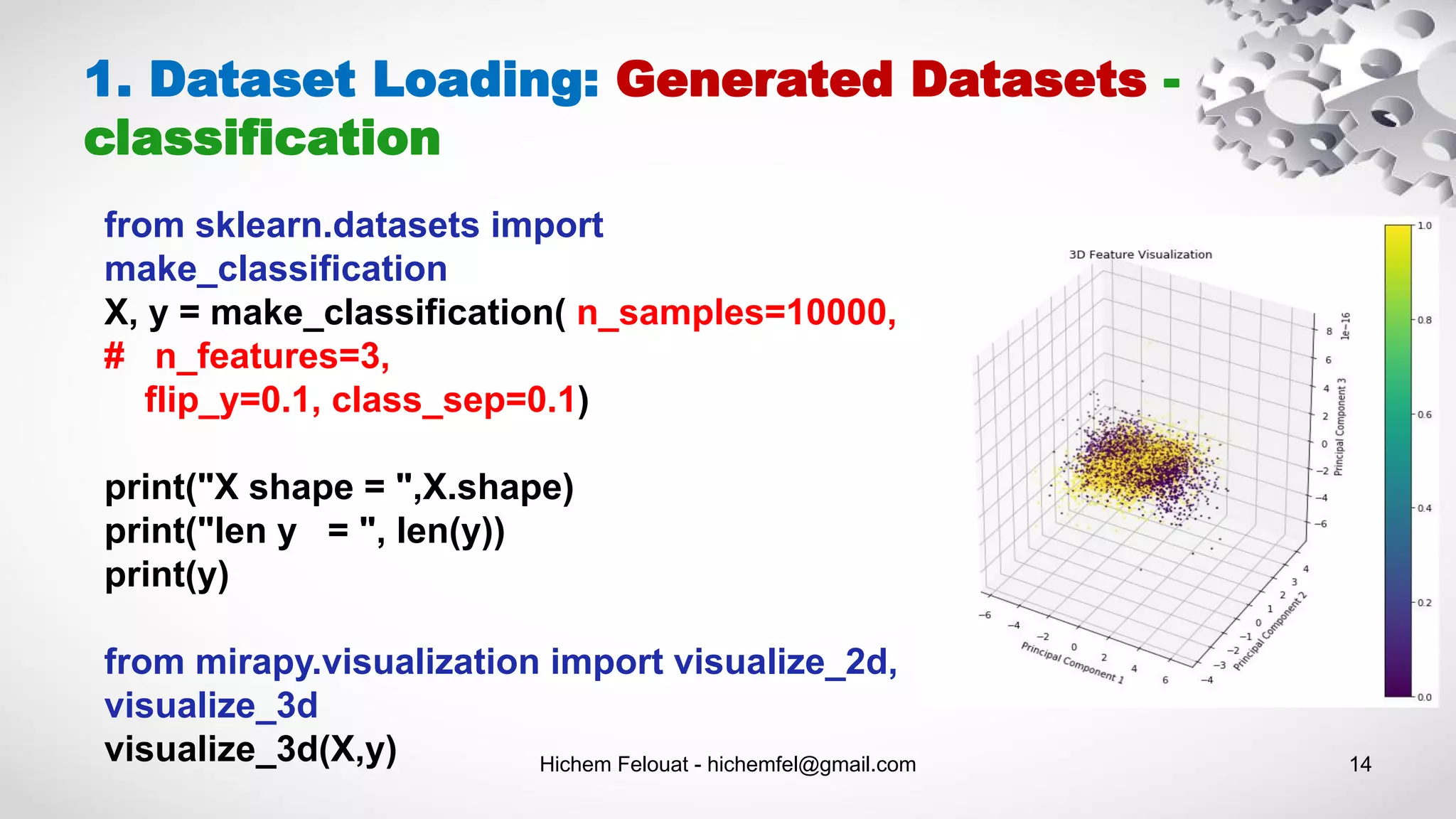
![Hichem Felouat - hichemfel@gmail.com 16 1. Dataset Loading: Generated Datasets - Clustering from sklearn.datasets.samples_generator import make_blobs from matplotlib import pyplot as plt import pandas as pd X, y = make_blobs(n_samples=200, centers=4, n_features=2) Xy = pd.DataFrame(dict(x1=X[:,0], x2=X[:,1], label=y)) groups = Xy.groupby('label') fig, ax = plt.subplots() colors = ["blue", "red", "green", "purple"] for idx, classification in groups: classification.plot(ax=ax, kind='scatter', x='x1', y='x2', label=idx, color=colors[idx]) plt.show()](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-16-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 17 2. Preprocessing Data: missing values Dealing with missing values : df = df.fillna('*') df[‘Test Score’] = df[‘Test Score’].fillna('*') df[‘Test Score’] = df[‘Test Score'].fillna(df['Test Score'].mean()) df['Test Score'] = df['Test Score'].fillna(df['Test Score'].interpolate()) df= df.dropna() #delete the missing rows of data df[‘Height(m)']= df[‘Height(m)’].dropna()](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-17-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 18 2. Preprocessing Data: missing values # Dealing with Non-standard missing values: # dictionary of lists dictionary = {'Name’:[‘Alex’, ‘Mike’, ‘John’, ‘Dave’, ’Joey’], ‘Height(m)’: [1.75, 1.65, ‘-‘, ‘na’, 1.82], 'Test Score':[70, np.nan, 8, 62, 73]} # creating a dataframe from list df = pd.DataFrame(dictionary) df.isnull() df = df.replace(['-','na'], np.nan)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-18-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 19 2. Preprocessing Data: missing values import numpy as np from sklearn.impute import SimpleImputer X = [[np.nan, 2], [6, np.nan], [7, 6]] # mean, median, most_frequent, constant(fill_value = ) imp = SimpleImputer(missing_values = np.nan, strategy='mean') data = imp.fit_transform(X) print(data) Multivariate feature imputation : IterativeImputer Nearest neighbors imputation : KNNImputer Marking imputed values : MissingIndicator](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-19-2048.jpg)
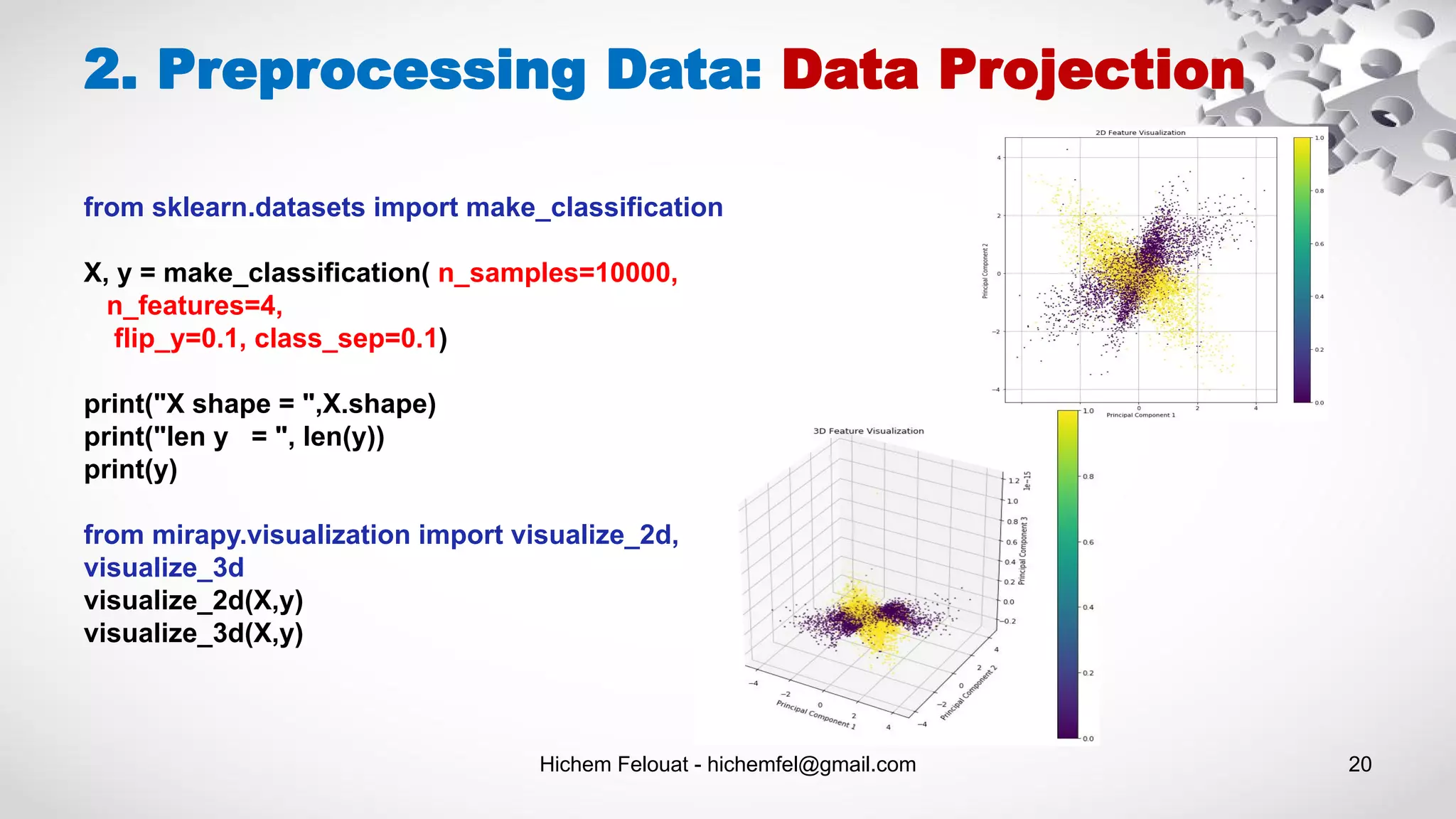


![Hichem Felouat - hichemfel@gmail.com 23 3. Feature Selection: 1. Standardization - StandardScaler from sklearn.preprocessing import StandardScaler import numpy as np X_train = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]) scaler = StandardScaler().fit_transform(X_train) print(scaler) Out: [[ 0. -1.22474487 1.33630621] [ 1.22474487 0. -0.26726124] [-1.22474487 1.22474487 -1.06904497]]](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-23-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 24 3. Feature Selection: 1. Standardization - Scaling Features to a Range import numpy as np from sklearn import preprocessing X_train = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]) # Here is an example to scale a data matrix to the [0, 1] range: min_max_scaler = preprocessing.MinMaxScaler() X_train_minmax = min_max_scaler.fit_transform(X_train) print(X_train_minmax) # between a given minimum and maximum value min_max_scaler = preprocessing.MinMaxScaler(feature_range=(0, 10)) # scaling in a way that the training data lies within the range [-1, 1] max_abs_scaler = preprocessing.MaxAbsScaler()](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-24-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 25 3. Feature Selection: 1. Standardization - Scaling Data with Outliers If your data contains many outliers, scaling using the mean and variance of the data is likely to not work very well. In these cases, you can use robust_scale and RobustScaler as drop-in replacements instead. They use more robust estimates for the center and range of your data. import numpy as np from sklearn import preprocessing X_train = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]) scaler = preprocessing.RobustScaler() X_train_rob_scal = scaler.fit_transform(X_train) print(X_train_rob_scal)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-25-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 26 3. Feature Selection: 2. Non-linear Transformation - Mapping to a Uniform Distribution QuantileTransformer and quantile_transform provide a non-parametric transformation to map the data to a uniform distribution with values between 0 and 1: from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn import preprocessing import numpy as np X, y = load_iris(return_X_y=True) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) print(X_train) quantile_transformer = preprocessing.QuantileTransformer(random_state=0) X_train_trans = quantile_transformer.fit_transform(X_train) print(X_train_trans) X_test_trans = quantile_transformer.transform(X_test) # Compute the q-th percentile of the data along the specified axis. np.percentile(X_train[:, 0], [0, 25, 50, 75, 100])](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-26-2048.jpg)

![Hichem Felouat - hichemfel@gmail.com 28 3. Feature Selection: 3. Normalization Normalization is the process of scaling individual samples to have unit norm. This process can be useful if you plan to use a quadratic form such as the dot-product or any other kernel to quantify the similarity of any pair of samples. from sklearn import preprocessing import numpy as np X = [[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]] X_normalized = preprocessing.normalize(X, norm='l2') print(X_normalized)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-28-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 29 3. Feature Selection: 4. Encoding Categorical Features To convert categorical features to such integer codes, we can use the OrdinalEncoder. This estimator transforms each categorical feature to one new feature of integers (0 to n_categories - 1). from sklearn import preprocessing #genders = ['female', 'male'] #locations = ['from Africa', 'from Asia', 'from Europe', 'from US'] #browsers = ['uses Chrome', 'uses Firefox', 'uses IE', 'uses Safari'] X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Safari'], ['female', 'from Asia', 'uses Firefox'], ['male', 'from Africa', 'uses Chrome']] enc = preprocessing.OrdinalEncoder() X_enc = enc.fit_transform(X) print(X_enc)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-29-2048.jpg)
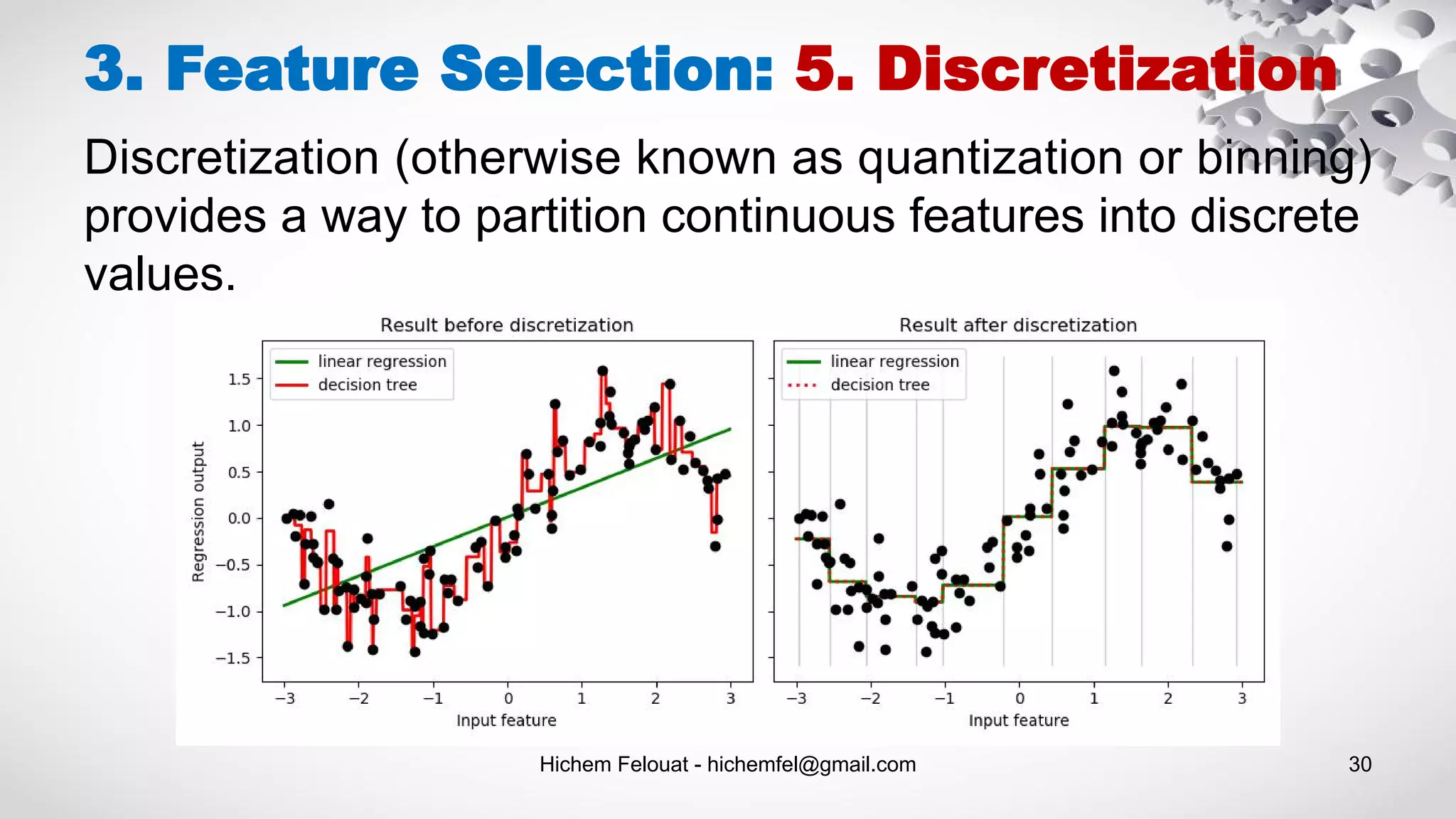
![Hichem Felouat - hichemfel@gmail.com 31 3. Feature Selection: 5. Discretization from sklearn import preprocessing import numpy as np X = np.array([[ -3., 5., 15 ], [ 0., 6., 14 ], [ 6., 3., 11 ]]) # 'onehot’, ‘onehot-dense’, ‘ordinal’ kbd = preprocessing.KBinsDiscretizer(n_bins=[3, 2, 2], encode='ordinal') X_kbd = kbd.fit_transform(X) print(X_kbd)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-31-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 32 3. Feature Selection: 5.1 Feature Binarization from sklearn import preprocessing import numpy as np X = [[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]] binarizer = preprocessing.Binarizer() X_bin = binarizer.fit_transform(X) print(X_bin) # It is possible to adjust the threshold of the binarizer: binarizer_1 = preprocessing.Binarizer(threshold=1.1) X_bin_1 = binarizer_1.fit_transform(X) print(X_bin_1)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-32-2048.jpg)


![Hichem Felouat - hichemfel@gmail.com 35 3. Feature Selection: 7. Custom Transformers Often, you will want to convert an existing Python function into a transformer to assist in data cleaning or processing. You can implement a transformer from an arbitrary function with FunctionTransformer. For example, to build a transformer that applies a log transformation in a pipeline, do: from sklearn import preprocessing import numpy as np transformer = preprocessing.FunctionTransformer(np.log1p, validate=True) X = np.array([[0, 1], [2, 3]]) X_tr = transformer.fit_transform(X) print(X_tr)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-35-2048.jpg)


![Hichem Felouat - hichemfel@gmail.com 38 from sklearn.feature_extraction.text import CountVectorizer texts = [ "blue car and blue window", "black crow in the window", "i see my reflection in the window" ] vec = CountVectorizer(binary=True) vec.fit(texts) print([w for w in sorted(vec.vocabulary_.keys())]) X = vec.transform(texts).toarray() print(X) import pandas as pd pd.DataFrame(vec.transform(texts).toarray(), columns=sorted(vec.vocabulary_.keys())) 3. Feature Selection: Text Feature](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-38-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 39 bigram_vectorizer = CountVectorizer(ngram_range=(1, 2), token_pattern=r'bw+b', min_df=1) analyze = bigram_vectorizer.build_analyzer() analyze('Bi-grams are cool!') == ( ['bi', 'grams', 'are', 'cool', 'bi grams', 'grams are', 'are cool']) 3. Feature Selection: Text Feature To preserve some of the local ordering information we can extract 2-grams of words in addition to the 1-grams (individual words):](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-39-2048.jpg)


![Hichem Felouat - hichemfel@gmail.com 42 3. Feature Selection: Text Feature from sklearn.feature_extraction.text import TfidfVectorizer texts = [ "blue car and blue window", "black crow in the window", "i see my reflection in the window" ] vec = TfidfVectorizer() vec.fit(texts) print([w for w in sorted(vec.vocabulary_.keys())]) X = vec.transform(texts).toarray() import pandas as pd pd.DataFrame(vec.transform(texts).toarray(), columns=sorted(vec.vocabulary_.keys()))](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-42-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 43 3. Feature Selection: Image Feature #image.extract_patches_2d from sklearn.feature_extraction import image from sklearn.datasets import fetch_olivetti_faces import matplotlib.pyplot as plt import matplotlib.image as img data = fetch_olivetti_faces() plt.imshow(data.images[0]) patches = image.extract_patches_2d(data.images[0], (2, 2), max_patches=2,random_state=0) print('Image shape: {}'.format(data.images[0].shape),' Patches shape: {}'.format(patches.shape)) print('Patches = ',patches)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-43-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 44 3. Feature Selection: Image Feature import cv2 def hu_moments(image): image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) feature = cv2.HuMoments(cv2.moments(image)).flatten() return feature def histogram(image,mask=None): image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) hist = cv2.calcHist([image],[0],None,[256],[0,256]) cv2.normalize(hist, hist) return hist.flatten()](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-44-2048.jpg)








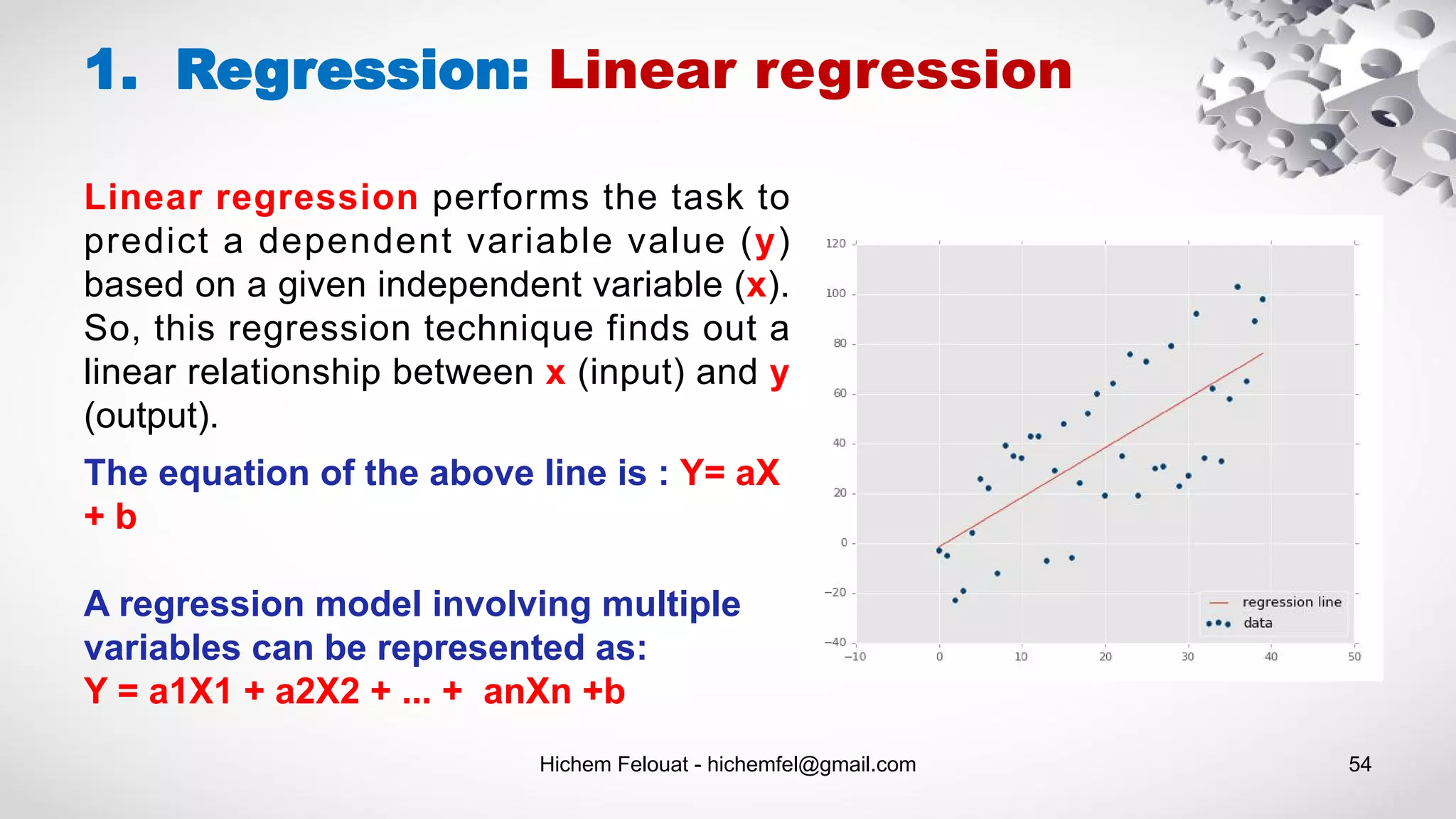
![Hichem Felouat - hichemfel@gmail.com 55 from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from sklearn import datasets, linear_model from sklearn import metrics import numpy as np dat = datasets.load_boston() X = dat.data Y = dat.target print("Examples = ",X.shape ," Labels = ", Y.shape) fig, ax = plt.subplots(figsize=(12,8)) ax.scatter(X[:,0], Y, edgecolors=(0, 0, 0)) ax.plot([Y.min(), Y.max()], [Y.min(), Y.max()], 'k--', lw=4) ax.set_xlabel('F') ax.set_ylabel('Y') plt.show() fig = plt.figure(figsize=(12, 8)) ax = fig.add_subplot(111, projection='3d') ax.scatter(X[:, 0], X[:, 1], Y, c='b', marker='o',cmap=plt.cm.Set1, edgecolor='k', s=40) ax.set_title("My Data") ax.set_xlabel("F1") ax.w_xaxis.set_ticklabels([]) ax.set_ylabel("F2") ax.w_yaxis.set_ticklabels([]) ax.set_zlabel("Y") ax.w_zaxis.set_ticklabels([]) plt.show() X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size= 0.20, random_state=100) print("X_train = ",X_train.shape ," Y_test = ", Y_test.shape) regressor = linear_model.LinearRegression() regressor.fit(X_train, Y_train) predicted = regressor.predict(X_test) import pandas as pd df = pd.DataFrame({'Actual': Y_test.flatten(), 'Predicted': predicted.flatten()}) print(df) df1 = df.head(25) df1.plot(kind='bar',figsize=(12,8)) plt.grid(which='major', linestyle='-', linewidth='0.5', color='green') plt.grid(which='minor', linestyle=':', linewidth='0.5', color='black') plt.show() predicted_all = regressor.predict(X) fig, ax = plt.subplots(figsize=(12,8)) ax.scatter(X[:,0], Y, edgecolors=(0, 0, 1)) ax.scatter(X[:,0], predicted_all, edgecolors=(1, 0, 0)) ax.set_xlabel('Measured') ax.set_ylabel('Predicted') plt.show() fig = plt.figure(figsize=(12, 8)) ax = fig.add_subplot(111, projection='3d') ax.scatter(X[:, 0], X[:, 1], Y, c='b', marker='o',cmap=plt.cm.Set1, edgecolor='k', s=40) ax.scatter(X[:, 0], X[:, 1], predicted_all, c='r', marker='o',cmap=plt.cm.Set1, edgecolor='k', s=40) ax.set_title("My Data") ax.set_xlabel("F1") ax.w_xaxis.set_ticklabels([]) ax.set_ylabel("F2") ax.w_yaxis.set_ticklabels([]) ax.set_zlabel("Y") ax.w_zaxis.set_ticklabels([]) plt.show() print('Mean Absolute Error : ', metrics.mean_absolute_error(Y_test, predicted)) print('Mean Squared Error : ', metrics.mean_squared_error(Y_test, predicted)) print('Root Mean Squared Error: ', np.sqrt(metrics.mean_squared_error(Y_test, predicted)))](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-55-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 56 1. Regression: Learning Curves def plot_learning_curves(model, X, y): from sklearn.metrics import mean_squared_error X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2) train_errors, val_errors = [], [] for m in range(1, len(X_train)): model.fit(X_train[:m], y_train[:m]) y_train_predict = model.predict(X_train[:m]) y_val_predict = model.predict(X_val) train_errors.append(mean_squared_error(y_train_predict, y_train[:m])) val_errors.append(mean_squared_error(y_val_predict, y_val)) fig, ax = plt.subplots(figsize=(12,8)) ax.plot(np.sqrt(train_errors), "r-+", linewidth=2, label="train") ax.plot(np.sqrt(val_errors), "b-", linewidth=3, label="val") ax.legend(loc='upper right', bbox_to_anchor=(0.5, 1.1),ncol=1, fancybox=True, shadow=True) ax.set_xlabel('Training set size') ax.set_ylabel('RMSE') plt.show()](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-56-2048.jpg)

![Hichem Felouat - hichemfel@gmail.com 58 1. Regression: Kernel Ridge regression from sklearn.kernel_ridge import KernelRidge # kernel = [linear,polynomial,rbf] regressor = KernelRidge(kernel ='rbf', alpha=1.0) regressor.fit(X_train, Y_train) predicted = regressor.predict(X_test) In order to explore nonlinear relations of the regression problem](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-58-2048.jpg)

![Hichem Felouat - hichemfel@gmail.com 60 1. Regression: Polynomial Regression # generate some nonlinear data import numpy as np m = 1000 X = 6 * np.random.rand(m, 1) - 3 Y = 0.5 * X**2 + X + 2 + np.random.randn(m, 1) print("Examples = ",X.shape ," Labels = ", Y.shape) import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D fig, ax = plt.subplots(figsize=(12,8)) ax.scatter(X[:,0], Y, edgecolors=(0, 0, 1)) ax.set_xlabel('F') ax.set_ylabel('Y') plt.show() from sklearn.preprocessing import PolynomialFeatures poly_features = PolynomialFeatures(degree=2, include_bias=False) X_poly = poly_features.fit_transform(X) print("Examples = ",X_poly.shape ," Labels = ", Y.shape) from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X_poly, Y, test_size= 0.20, random_state=100) from sklearn import linear_model regressor = linear_model.LinearRegression() regressor.fit(X_train, Y_train) predicted = regressor.predict(X_poly) fig, ax = plt.subplots(figsize=(12,8)) ax.scatter(X, Y, edgecolors=(0, 0, 1)) ax.scatter(X,predicted,edgecolors=(1, 0, 0)) ax.set_xlabel('F') ax.set_ylabel('Y') plt.show() B = regressor.intercept_ A = regressor.coef_ print(A) print(B) print("The model estimates : Y = ",B[0]," + ",A[0,0]," X + ",A[0,1]," X^2") from sklearn import metrics predicted = regressor.predict(X_test) print('Mean Absolute Error : ', metrics.mean_absolute_error(Y_test, predicted)) print('Mean Squared Error : ', metrics.mean_squared_error(Y_test, predicted)) print('Root Mean Squared Error: ', np.sqrt(metrics.mean_squared_error(Y_test, predicted)))](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-60-2048.jpg)

![Hichem Felouat - hichemfel@gmail.com 62 1. Regression: Support Vector Regression SVR import numpy as np from sklearn.svm import SVR import matplotlib.pyplot as plt # Generate sample data X = np.sort(5 * np.random.rand(40, 1), axis=0) Y = np.sin(X).ravel() # Add noise to targets Y[::5] += 3 * (0.5 - np.random.rand(8)) print("Examples = ",X.shape ," Y = ", Y.shape) # Fit regression model svr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=.1) svr_lin = SVR(kernel='linear', C=100, gamma='auto') svr_poly = SVR(kernel='poly', C=100, gamma='auto', degree=3, epsilon=.1, coef0=1) # Look at the results lw = 2 svrs = [svr_rbf, svr_lin, svr_poly] kernel_label = ['RBF', 'Linear', 'Polynomial'] model_color = ['m', 'c', 'g'] fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(15, 10), sharey=True) for ix, svr in enumerate(svrs): axes[ix].plot(X, svr.fit(X, Y).predict(X), color=model_color[ix], lw=lw, label='{} model'.format(kernel_label[ix])) axes[ix].scatter(X[svr.support_], Y[svr.support_], facecolor="none", edgecolor=model_color[ix], s=50, label='{} support vectors'.format(kernel_label[ix])) axes[ix].scatter(X[np.setdiff1d(np.arange(len(X)), svr.support_)], Y[np.setdiff1d(np.arange(len(X)), svr.support_)], facecolor="none", edgecolor="k", s=50, label='other training data') axes[ix].legend(loc='upper center', bbox_to_anchor=(0.5, 1.1), ncol=1, fancybox=True, shadow=True) fig.text(0.5, 0.04, 'data', ha='center', va='center') fig.text(0.06, 0.5, 'target', ha='center', va='center', rotation='vertical') fig.suptitle("Support Vector Regression", fontsize=14) plt.show()](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-62-2048.jpg)
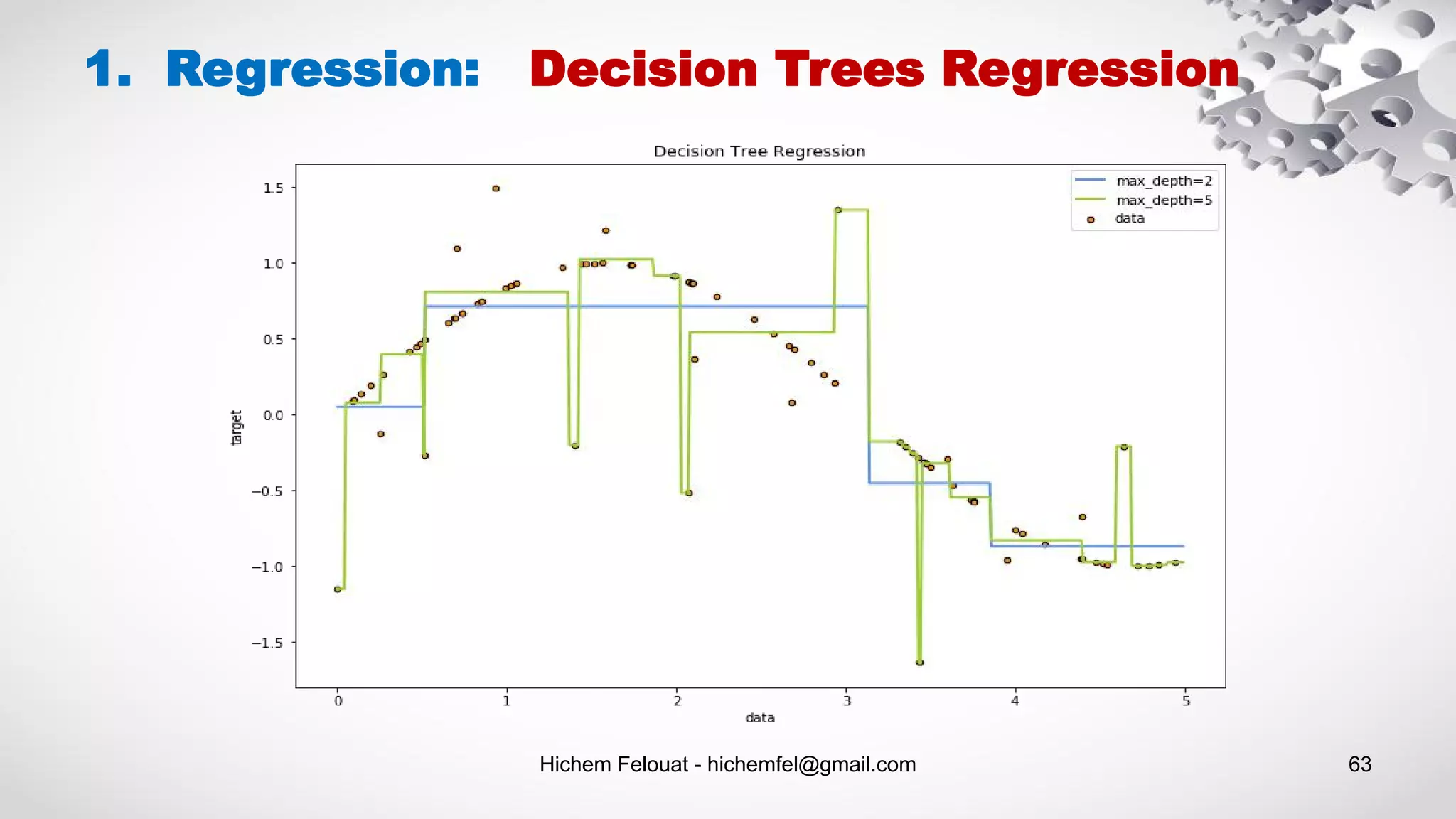
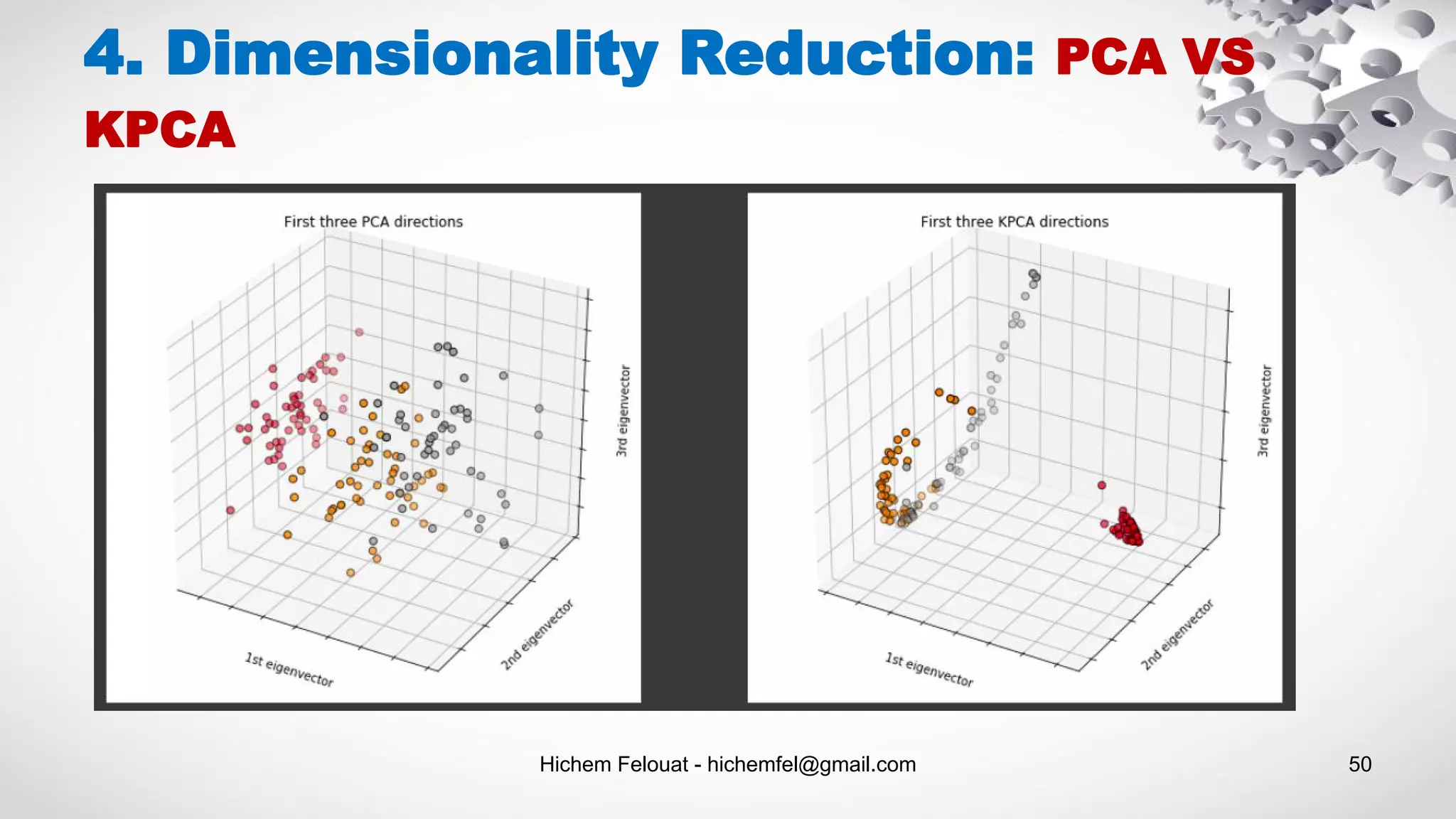
![Hichem Felouat - hichemfel@gmail.com 64 1. Regression: Decision Trees Regression import matplotlib.pyplot as plt import numpy as np from sklearn.tree import DecisionTreeRegressor rng = np.random.RandomState(1) X = np.sort(5 * rng.rand(80, 1), axis=0) Y = np.sin(X).ravel() Y[::5] += 3 * (0.5 - rng.rand(16)) print("Examples = ",X.shape ," Labels = ", Y.shape) X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis] regressor1 = DecisionTreeRegressor(max_depth=2) regressor2 = DecisionTreeRegressor(max_depth=5) regressor1.fit(X, Y) regressor2.fit(X, Y) predicted1 = regressor1.predict(X_test) predicted2 = regressor2.predict(X_test) plt.figure(figsize=(12,8)) plt.scatter(X, Y, s=20, edgecolor="black",c="darkorange", label="data") plt.plot(X_test, predicted1, color="cornflowerblue",label="max_depth=2", linewidth=2) plt.plot(X_test, predicted2, color="yellowgreen", label="max_depth=5", linewidth=2) plt.xlabel("data") plt.ylabel("target") plt.title("Decision Tree Regression") plt.legend() plt.show()](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-64-2048.jpg)





![Hichem Felouat - hichemfel@gmail.com 70 2. Classification: Support Vector Machines -Kernel + Tuning Hyperparameters import matplotlib.pyplot as plt from sklearn import datasets, svm, metrics from sklearn.model_selection import train_test_split digits = datasets.load_digits() _, axes = plt.subplots(2, 4) images_and_labels = list(zip(digits.images, digits.target)) for ax, (image, label) in zip(axes[0, :], images_and_labels[:4]): ax.set_axis_off() ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest') ax.set_title('Training: %i' % label) # To apply a classifier on this data, we need to flatten the image, to # turn the data in a (samples, feature) matrix: n_samples = len(digits.images) data = digits.images.reshape((n_samples, -1)) # Create a classifier: a support vector classifier classifier = svm.SVC(gamma=0.001) # Split data into train and test subsets X_train, X_test, y_train, y_test = train_test_split( data, digits.target, test_size=0.5, shuffle=False) # We learn the digits on the first half of the digits classifier.fit(X_train, y_train) # Now predict the value of the digit on the second half: predicted = classifier.predict(X_test) images_and_predictions = list(zip(digits.images[n_samples // 2:], predicted)) for ax, (image, prediction) in zip(axes[1, :], images_and_predictions[:4]): ax.set_axis_off() ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest') ax.set_title('Prediction: %i' % prediction) print("Classification report : n", classifier,"n", metrics.classification_report(y_test, predicted)) disp = metrics.plot_confusion_matrix(classifier, X_test, y_test) disp.figure_.suptitle("Confusion Matrix") print("Confusion matrix: n", disp.confusion_matrix) plt.show()](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-70-2048.jpg)





![Hichem Felouat - hichemfel@gmail.com 76 2. Classification: Stochastic Gradient Descent from sklearn.linear_model import SGDClassifier X = [[0., 0.], [1., 1.]] y = [0, 1] # loss : hinge, log, modified_huber, squared_hinge, perceptron clf = SGDClassifier(loss="hinge", penalty="l2", max_iter=5) clf.fit(X, y) predicted = clf.predict(X_test)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-76-2048.jpg)

![Hichem Felouat - hichemfel@gmail.com 78 from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris from sklearn.metrics import classification_report, confusion_matrix import numpy as np import matplotlib.pyplot as plt # Loading data irisData = load_iris() # Create feature and target arrays X = irisData.data y = irisData.target # Split into training and test set X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.2, random_state=42) knn = KNeighborsClassifier(n_neighbors = 7) knn.fit(X_train, y_train) predicted = knn.predict(X_test) print(confusion_matrix(y_test, predicted)) print(classification_report(y_test, predicted)) 2. Classification: K-Nearest Neighbors KNN neighbors = np.arange(1, 25) train_accuracy = np.empty(len(neighbors)) test_accuracy = np.empty(len(neighbors)) # Loop over K values for i, k in enumerate(neighbors): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) # Compute traning and test data accuracy train_accuracy[i] = knn.score(X_train, y_train) test_accuracy[i] = knn.score(X_test, y_test) # Generate plot plt.plot(neighbors, test_accuracy, label = 'Testing dataset Accuracy') plt.plot(neighbors, train_accuracy, label = 'Training dataset Accuracy') plt.legend() plt.xlabel('n_neighbors') plt.ylabel('Accuracy') plt.show()](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-78-2048.jpg)




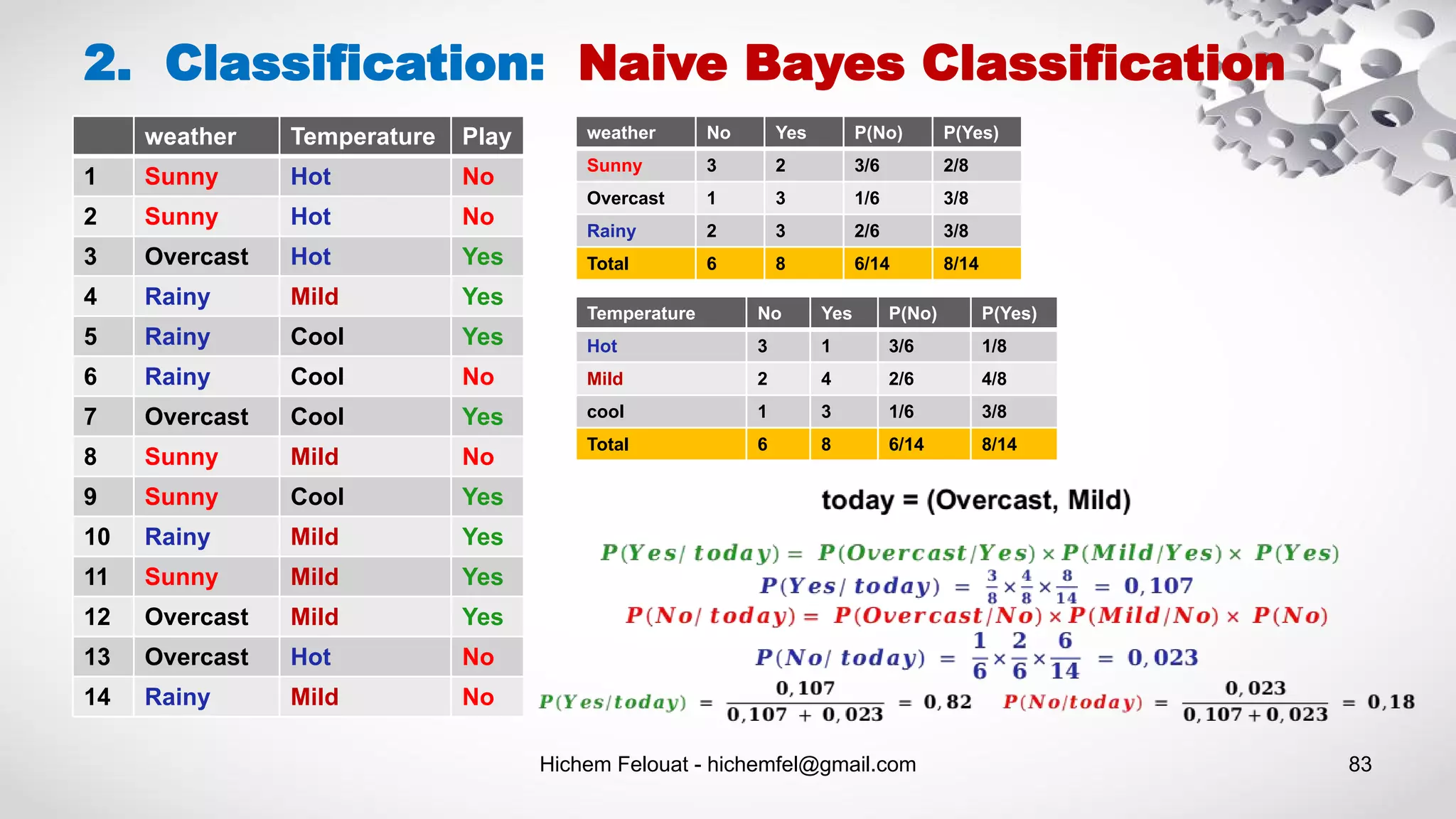
![Hichem Felouat - hichemfel@gmail.com 84 2. Classification: Naive Bayes Classification # Assigning features and label variables weather=['Sunny','Sunny','Overcast','Rainy','Rainy','R ainy','Overcast','Sunny','Sunny', 'Rainy','Sunny','Overcast','Overcast','Rainy'] temp=['Hot','Hot','Hot','Mild','Cool','Cool','Cool','Mild',' Cool','Mild','Mild','Mild','Hot','Mild'] play=['No','No','Yes','Yes','Yes','No','Yes','No','Yes','Ye s','Yes','Yes','No','No'] # Import LabelEncoder from sklearn import preprocessing # creating labelEncoder le = preprocessing.LabelEncoder() # Converting string labels into numbers. weather_encoded=le.fit_transform(weather) print("weather:",wheather_encoded) # Converting string labels into numbers temp_encoded=le.fit_transform(temp) label=le.fit_transform(play) print("Temp: ",temp_encoded) print("Play: ",label) # Combinig weather and temp into single listof tuples features = zip(weather_encoded,temp_encoded) import numpy as np features = np.asarray(list(features)) print("features : ",features) #Import Gaussian Naive Bayes model from sklearn.naive_bayes import GaussianNB #Create a Gaussian Classifier model = GaussianNB() # Train the model using the training sets model.fit(features,label) # Predict Output predicted= model.predict([[0,2]]) # 0:Overcast, 2:Mild print ("Predicted Value (No = 0, Yes = 1):", predicted)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-84-2048.jpg)

![Hichem Felouat - hichemfel@gmail.com 86 2. Classification: Gaussian Naive Bayes Classification # load the iris dataset from sklearn.datasets import load_iris iris = load_iris() # store the feature matrix (X) and response vector (y) X = iris.data y = iris.target # splitting X and y into training and testing sets from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=100) # training the model on training set from sklearn.naive_bayes import GaussianNB gnb = GaussianNB() gnb.fit(X_train, y_train) # making predictions on the testing set y_pred = gnb.predict(X_test) # comparing actual response values (y_test) with predicted response values (y_pred) from sklearn import metrics print("Gaussian Naive Bayes model accuracy(in %):", metrics.accuracy_score(y_test, y_pred)*100) print("Number of mislabeled points out of a total %d points : %d" % (X_test.shape[0], (y_test != y_pred).sum()))](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-86-2048.jpg)

![Hichem Felouat - hichemfel@gmail.com 88 2. Classification: Multinomial Naive Bayes Classification from sklearn.datasets import fetch_20newsgroups data = fetch_20newsgroups() print(data.target_names) # For simplicity here, we will select just a few of these categories categories = ['talk.religion.misc', 'soc.religion.christian', 'sci.space', 'comp.graphics'] sub_data = fetch_20newsgroups(subset='train', categories=categories) X, Y = sub_data.data, sub_data.target print("Examples = ",len(X)," Labels = ", len(Y)) # Here is a representative entry from the data: print(X[5]) # In order to use this data for machine learning, we need to be able to convert the content of each string into a vector of numbers. # For this we will use the TF-IDF vectorizer from sklearn.feature_extraction.text import TfidfVectorizer vec = TfidfVectorizer() vec.fit(X) texts = vec.transform(X).toarray() print(" texts shape = ",texts.shape) # split the dataset into training data and test data from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(texts, Y, test_size= 0.20, random_state=100, stratify=Y) # training the model on training set from sklearn.naive_bayes import MultinomialNB clf = MultinomialNB() clf.fit(X_train, Y_train) # making predictions on the testing set predicted = clf.predict(X_test) from sklearn import metrics print("Classification report : n", clf,"n", metrics.classification_report(Y_test, predicted)) disp = metrics.plot_confusion_matrix(clf, X_test, Y_test) disp.figure_.suptitle("Confusion Matrix") print("Confusion matrix: n", disp.confusion_matrix)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-88-2048.jpg)

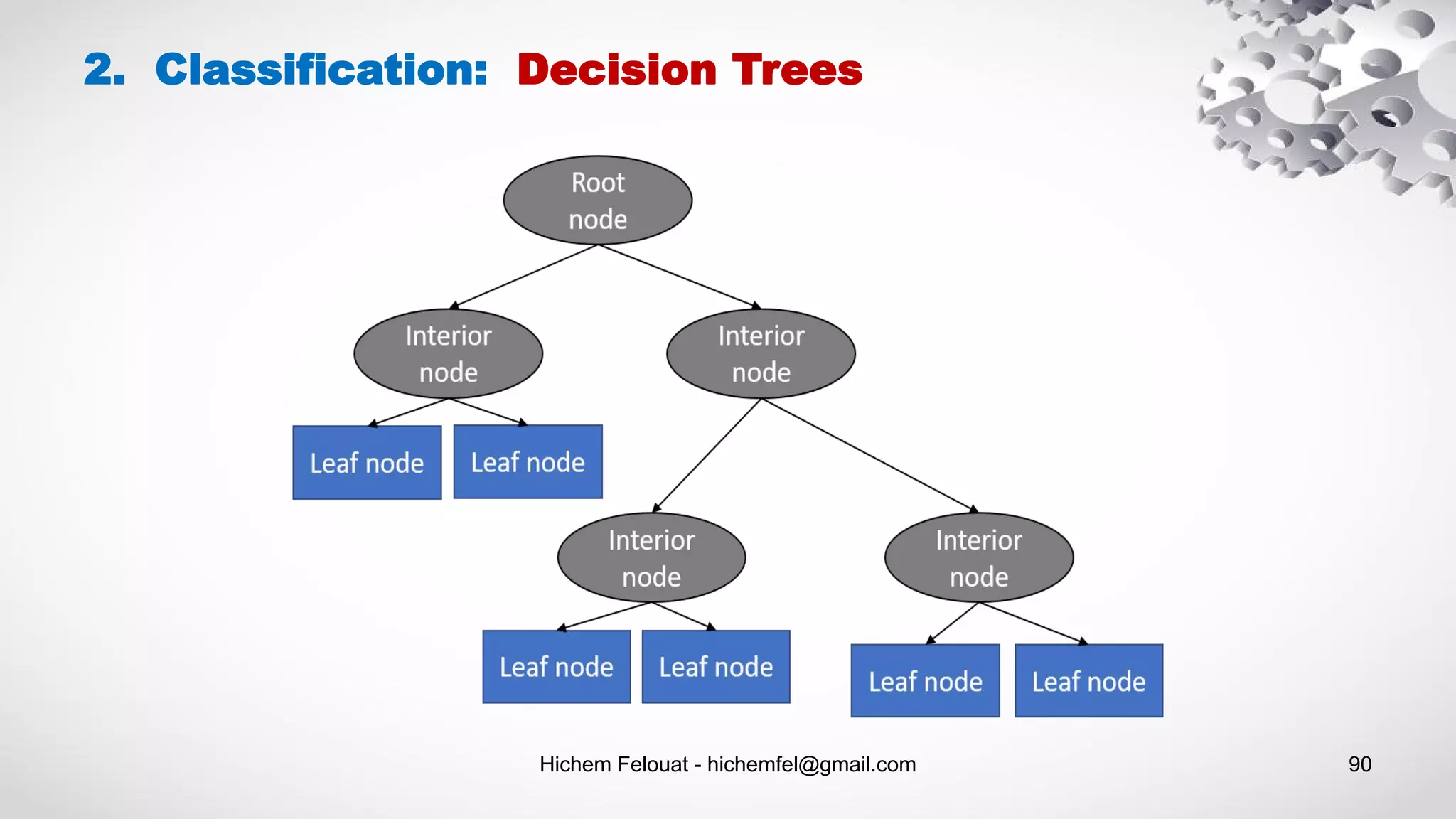
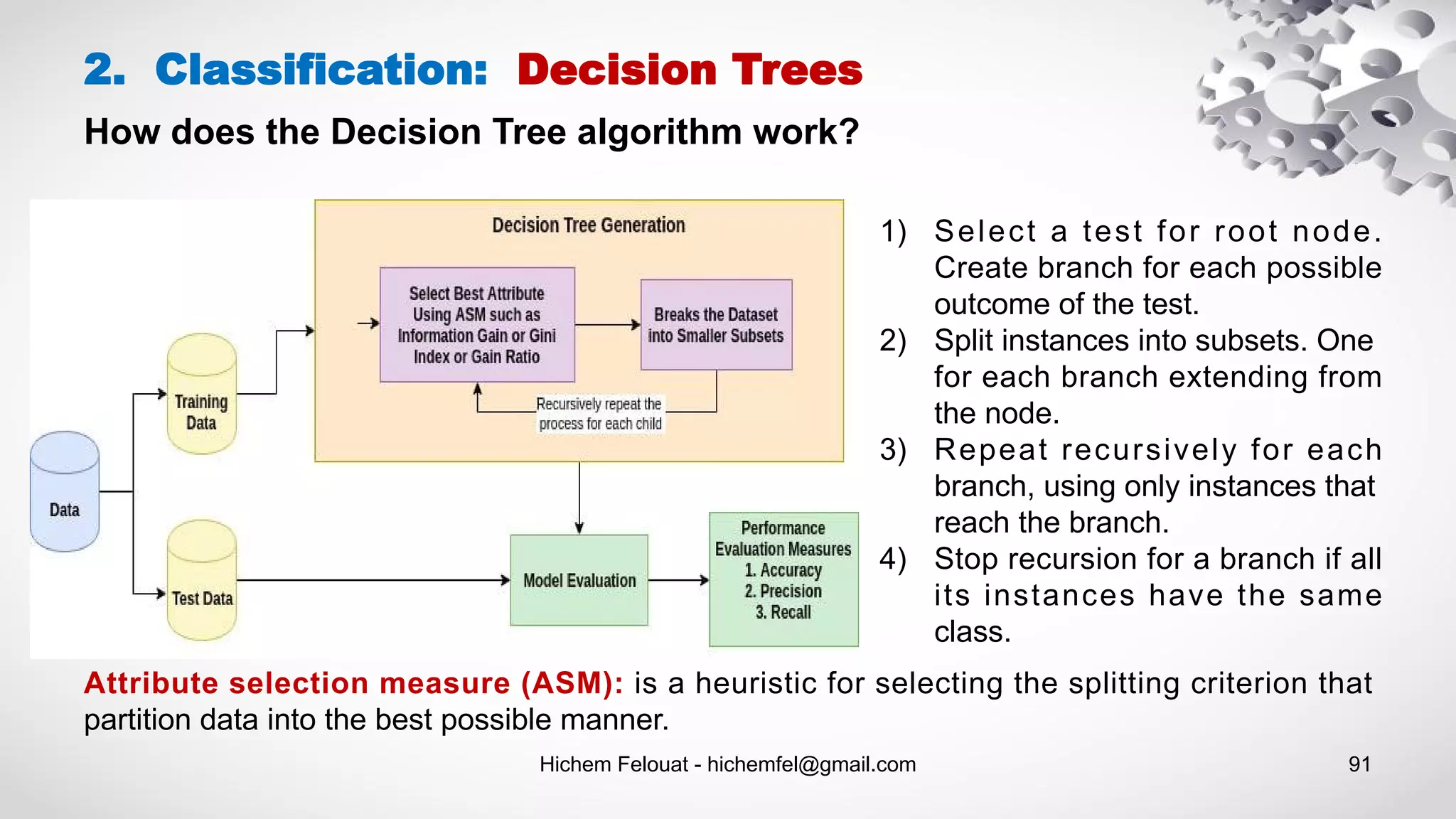
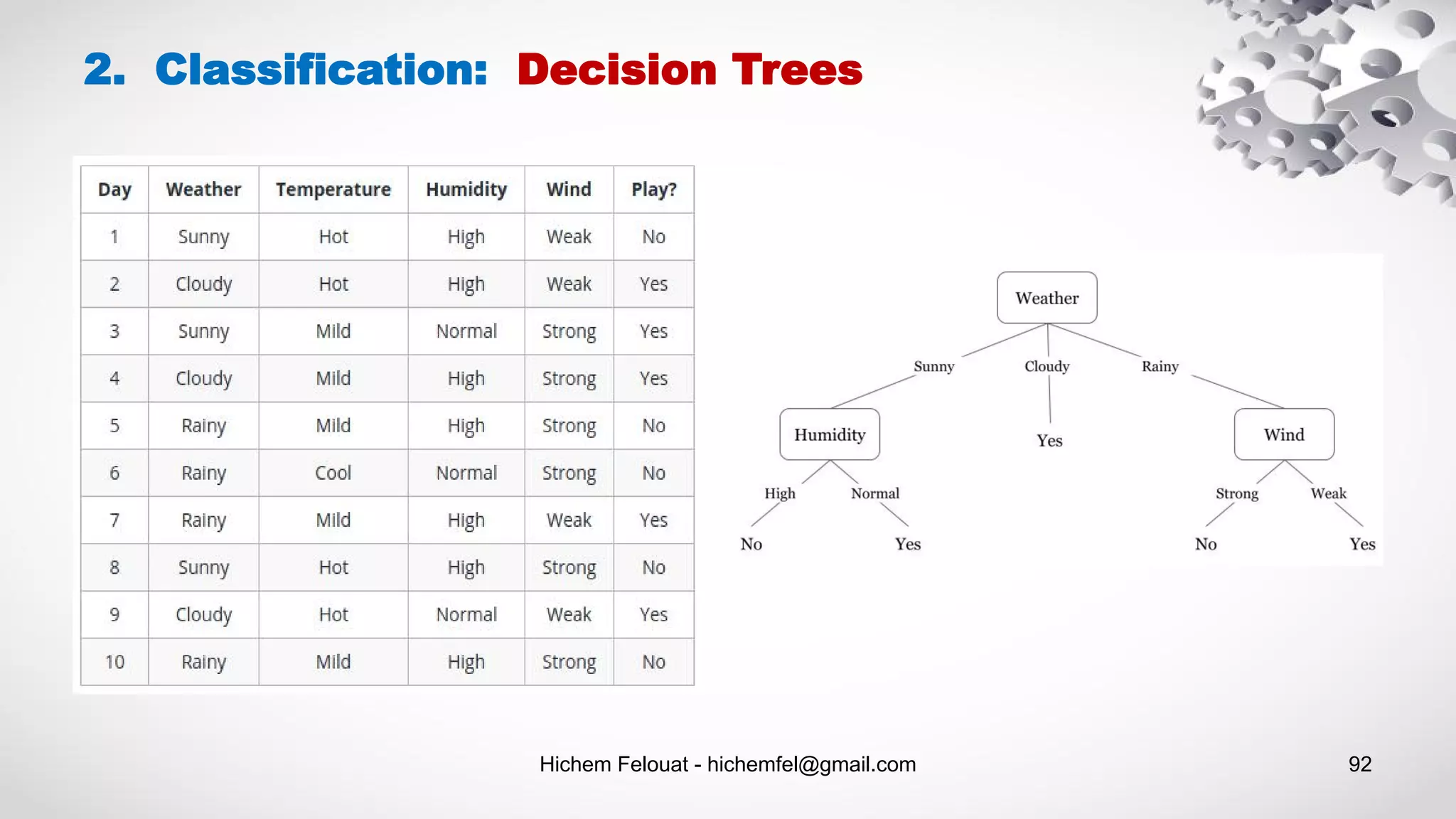

![Hichem Felouat - hichemfel@gmail.com 94 2. Classification: Decision Trees - Example # Visualize data import collections import pydotplus dot_data = tree.export_graphviz(tree_clf, feature_names=dat.feature_names, out_file=None, filled=True, rounded=True) graph = pydotplus.graph_from_dot_data(dot_data) colors = ('turquoise', 'orange') edges = collections.defaultdict(list) for edge in graph.get_edge_list(): edges[edge.get_source()].append(int(edge.get_destination())) for edge in edges: edges[edge].sort() for i in range(2): dest = graph.get_node(str(edges[edge][i]))[0] dest.set_fillcolor(colors[i]) graph.write_png('tree1.png') #pdf import graphviz dot_data = tree.export_graphviz(tree_clf, out_file=None) graph = graphviz.Source(dot_data) graph.render("iris") dot_data = tree.export_graphviz(tree_clf, out_file=None, feature_names=dat.feature_names, class_names=dat.target_names, filled=True, rounded=True, special_characters=True) graph = graphviz.Source(dot_data) graph.view('tree2.pdf')](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-94-2048.jpg)
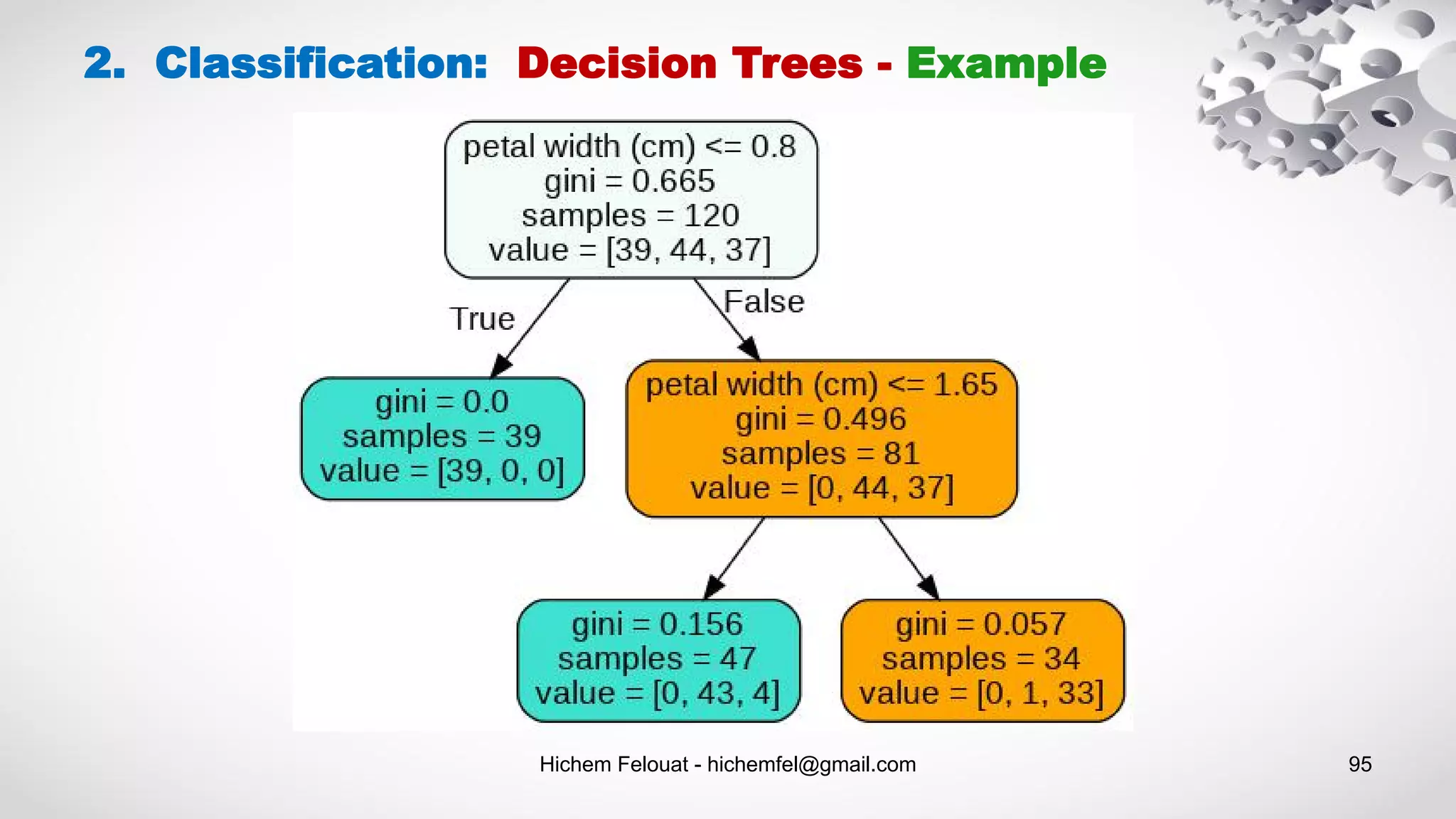
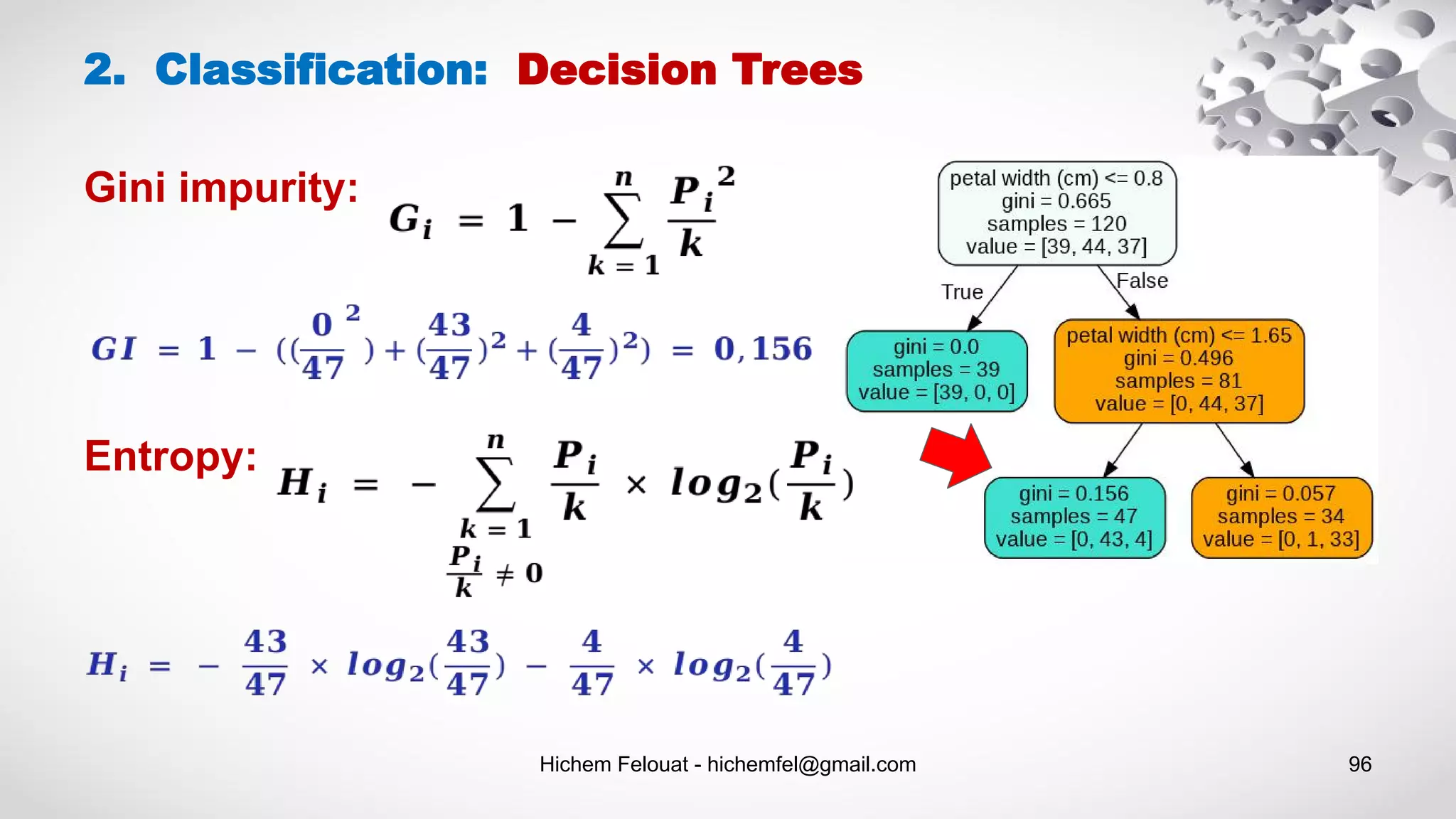
![Hichem Felouat - hichemfel@gmail.com 97 Estimating Class Probabilities: A Decision Tree can also estimate the probability that an instance belongs to a particular class k: first it traverses the tree to find the leaf node for this instance, and then it returns the ratio of training instances of class k in this node. 2. Classification: Decision Trees print("predict_proba : ",tree_clf.predict_proba([[1, 1.5, 3.2, 0.5]])) predict_proba : [[0. 0.91489362 0.08510638]] Scikit-Learn uses the CART algorithm, which produces only binary trees: nonleaf nodes always have two children (i.e., questions only have yes/no answers). However, other algorithms such as ID3 can produce Decision Trees with nodes that have more than two children.](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-97-2048.jpg)
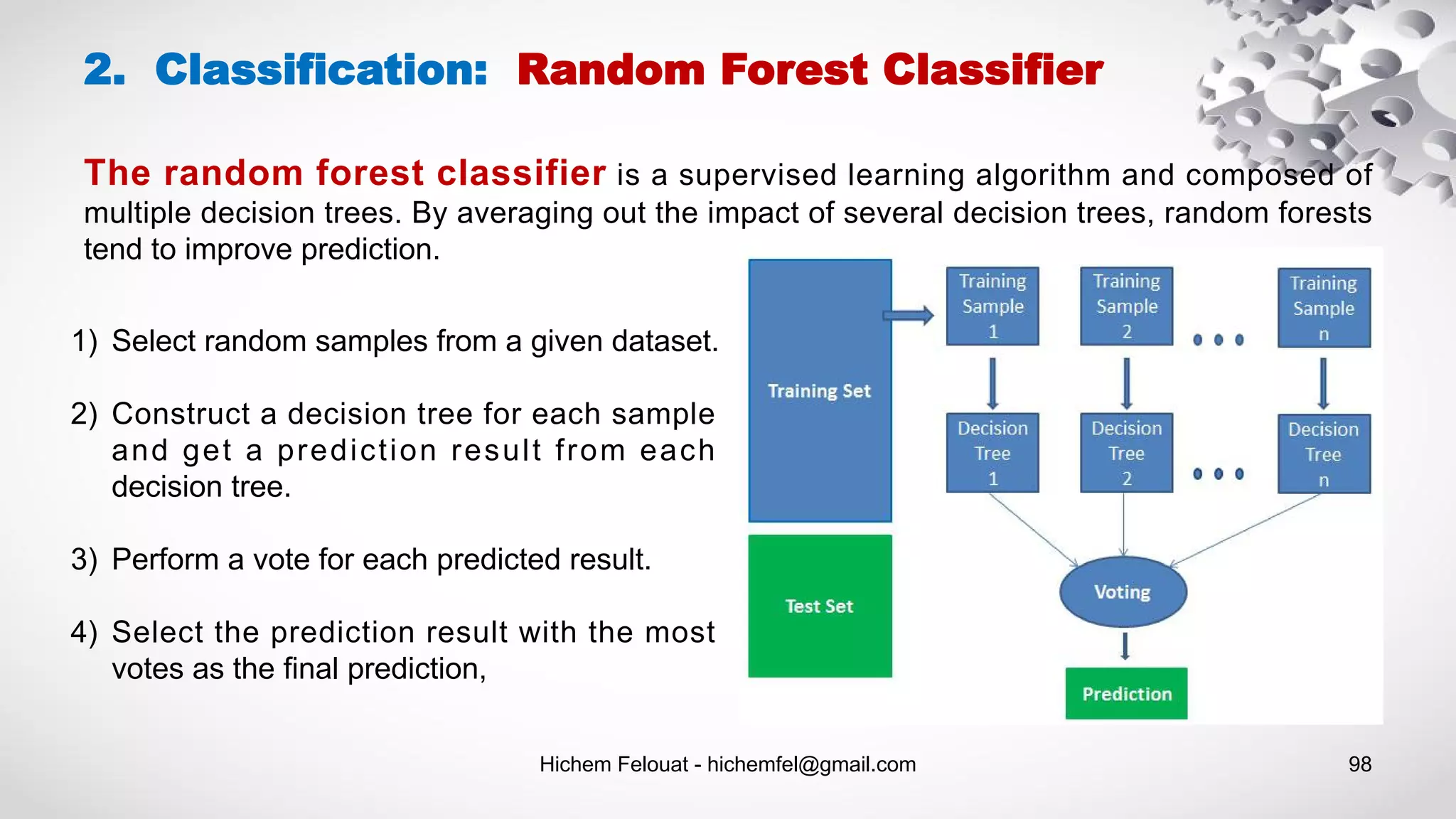



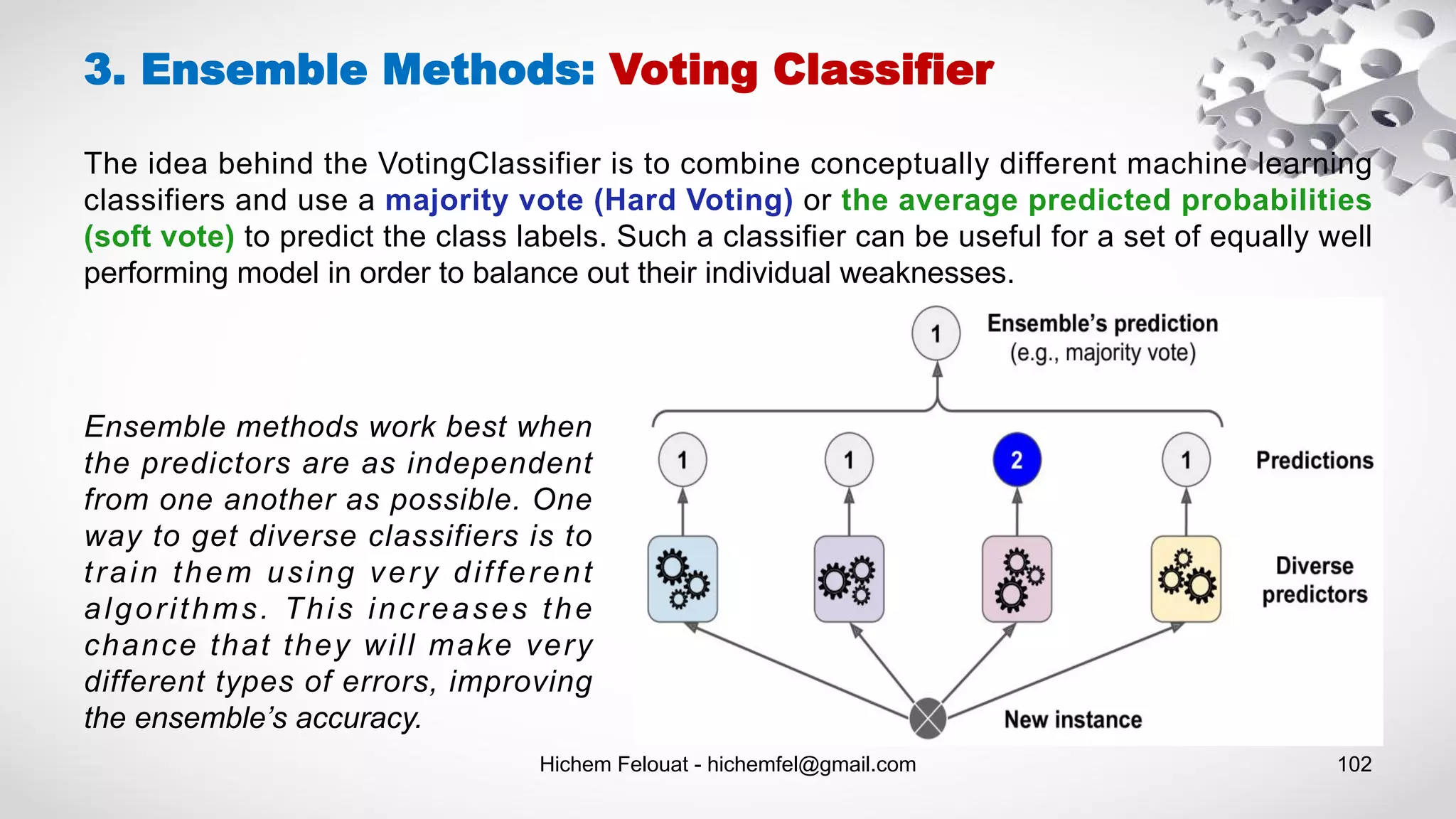
![Hichem Felouat - hichemfel@gmail.com 103 from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier, VotingClassifier from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.metrics import accuracy_score dat = datasets.load_breast_cancer() print("Examples = ",dat.data.shape ," Labels = ", dat.target.shape) X_train, X_test, Y_train, Y_test = train_test_split(dat.data, dat.target, test_size= 0.20, random_state=100) log_clf = LogisticRegression() rnd_clf = RandomForestClassifier() svm_clf = SVC() voting_clf = VotingClassifier( estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],voting='hard') voting_clf.fit(X_train, Y_train) for clf in (log_clf, rnd_clf, svm_clf, voting_clf): clf.fit(X_train, Y_train) y_pred = clf.predict(X_test) print(clf.__class__.__name__, accuracy_score(Y_test, y_pred)) 3. Ensemble Methods: Voting Classifier](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-103-2048.jpg)
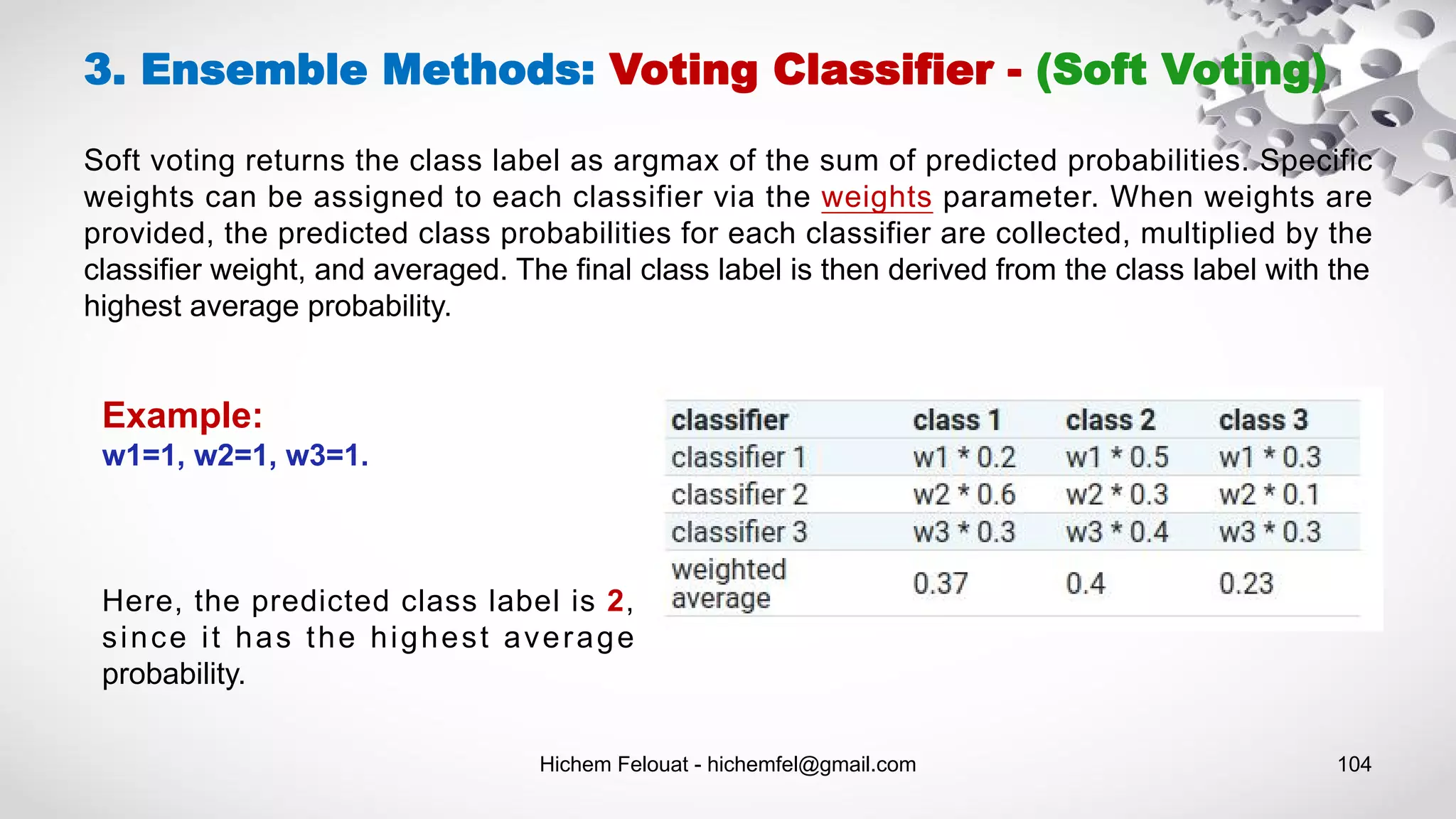
![Hichem Felouat - hichemfel@gmail.com 105 3. Ensemble Methods: Voting Classifier - (Soft Voting) from sklearn import datasets from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from itertools import product from sklearn.ensemble import VotingClassifier from sklearn.model_selection import train_test_split # Loading some example data dat = datasets.load_iris() X_train, X_test, Y_train, Y_test = train_test_split(dat.data, dat.target, test_size= 0.20, random_state=100) # Training classifiers clf1 = DecisionTreeClassifier(max_depth=4) clf2 = KNeighborsClassifier(n_neighbors=7) clf3 = SVC(kernel='rbf', probability=True) voting_clf_soft = VotingClassifier(estimators=[('dt', clf1), ('knn', clf2), ('svc', clf3)], voting='soft', weights=[2, 1, 3]) for clf in (clf1, clf2, clf3, voting_clf_soft): clf.fit(X_train, Y_train) y_pred = clf.predict(X_test) print(clf.__class__.__name__, accuracy_score(Y_test, y_pred))](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-105-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 106 from sklearn.datasets import load_boston from sklearn.ensemble import GradientBoostingRegressor, RandomForestRegressor,VotingRegressor from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn import metrics import numpy as np # Loading some example data dat = load_boston() X_train, X_test, Y_train, Y_test = train_test_split(dat.data, dat.target, test_size= 0.20, random_state=100) # Training classifiers reg1 = GradientBoostingRegressor(random_state=1, n_estimators=10) reg2 = RandomForestRegressor(random_state=1, n_estimators=10) reg3 = LinearRegression() voting_reg = VotingRegressor(estimators=[('gb', reg1), ('rf', reg2), ('lr', reg3)], weights=[1, 3, 2]) for clf in (reg1, reg2, reg3, voting_reg): clf.fit(X_train, Y_train) y_pred = clf.predict(X_test) print(clf.__class__.__name__," : **********") print('Mean Absolute Error : ', metrics.mean_absolute_error(Y_test, y_pred)) print('Mean Squared Error : ', metrics.mean_squared_error(Y_test, y_pred)) print('Root Mean Squared Error: ', np.sqrt(metrics.mean_squared_error(Y_test, y_pred))) 3. Ensemble Methods: Voting Regressor](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-106-2048.jpg)








![Hichem Felouat - hichemfel@gmail.com 115 3. Ensemble Methods: XGBoost - Classification from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split X, y = load_iris(return_X_y=True) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.20, random_state=100) # In order for XGBoost to be able to use our data, # we’ll need to transform it into a specific format that XGBoost can handle. D_train = xgb.DMatrix(X_train, label=y_train) D_test = xgb.DMatrix(X_test, label=y_test) # Training classsifier import xgboost as xgb param = {'eta': 0.3, 'max_depth': 3, 'objective': 'multi:softprob', 'num_class': 3} steps = 20 # The number of training iterations xg_clf = xgb.train(param, D_train, steps) # making predictions on the testing set predicted = xg_reg.predict(X_test) # comparing actual response values (y_test) with predicted response values (predicted) from sklearn import metrics print("Classification report : n", xg_clf,"n", metrics.classification_report(y_test, predicted)) disp.figure_.suptitle("Confusion Matrix") print("Confusion matrix: n", disp.confusion_matrix) # Visualize Boosting Trees and # Feature Importance import matplotlib.pyplot as plt xgb.plot_tree(xg_clf,num_trees=0) plt.rcParams['figure.figsize'] = [10, 10] plt.show() xgb.plot_importance(xg_clf) plt.rcParams['figure.figsize'] = [5, 5] plt.show()](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-115-2048.jpg)


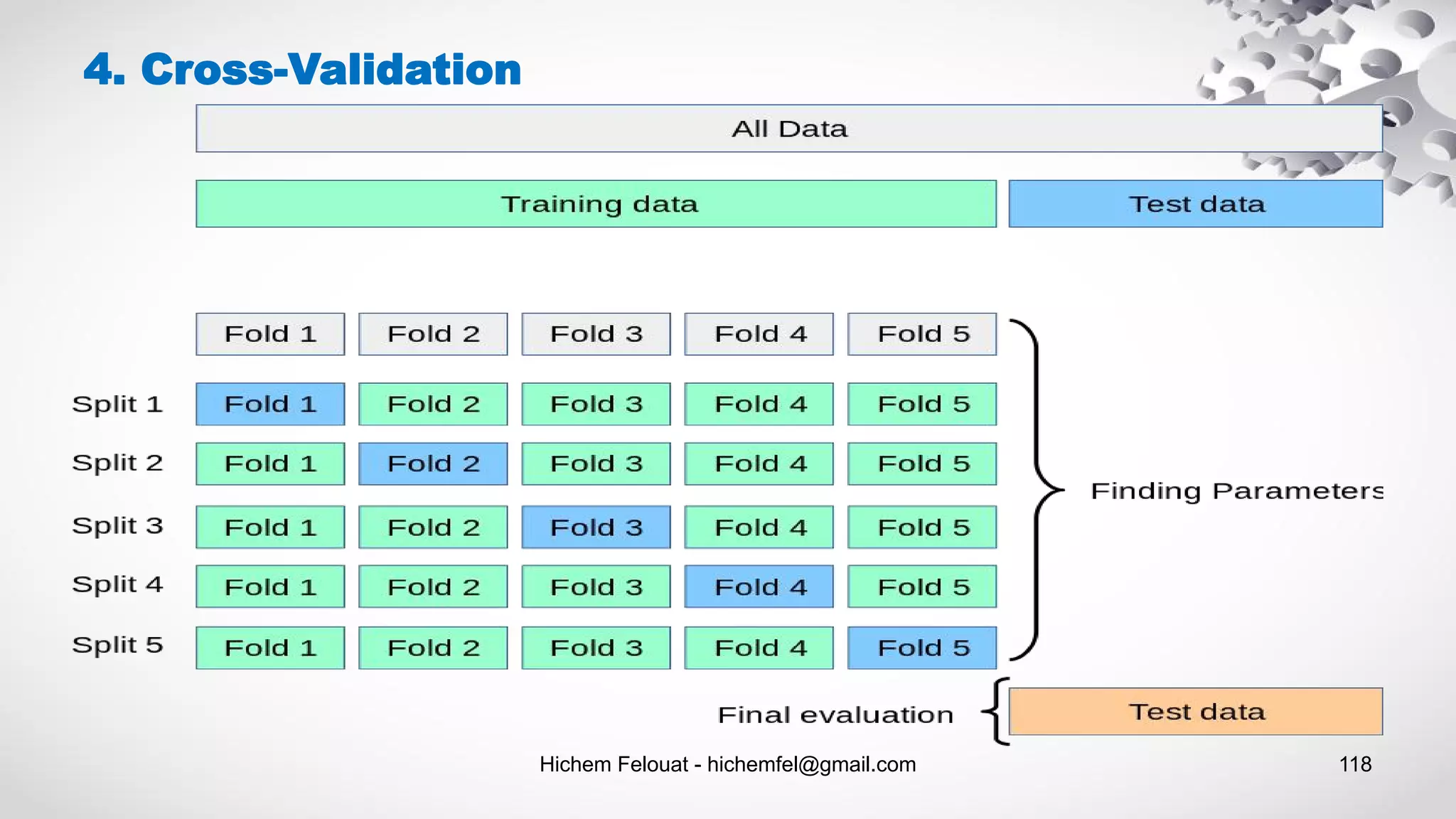


![Hichem Felouat - hichemfel@gmail.com 121 4. Cross-Validation import numpy as np from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn import svm from sklearn.model_selection import cross_val_score from sklearn import model_selection from sklearn import metrics dat = datasets.load_breast_cancer() print("Examples = ",dat.data.shape ," Labels = ", dat.target.shape) print("Example 0 = ",dat.data[0]) print("Label 0 =",dat.target[0]) print(dat.target) X = dat.data Y = dat.target # Make a train/test split using 20% test size X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size= 0.20, random_state=100) print("X_test = ",X_test.shape) print("Without Validation : *********") model_1 = svm.SVC(kernel='linear', C=10.0, gamma= 0.1) model_1.fit(X_train, Y_train) y_pred1 = model_1.predict(X_test) print("Accuracy 1 :",metrics.accuracy_score(Y_test, y_pred1)) print("K-fold Cross-Validation : *********") from sklearn.model_selection import KFold kfold = KFold(n_splits=10, random_state=100) model_2 = svm.SVC(kernel='linear', C=10.0, gamma= 0.1) results_model_2 = cross_val_score(model_2, X, Y, cv=kfold) accuracy2 = results_model_2.mean() print("Accuracy 2 :", accuracy2) print("Stratified K-fold Cross-Validation : *********") from sklearn.model_selection import StratifiedKFold skfold = StratifiedKFold(n_splits=3, random_state=100) model_3 = svm.SVC(kernel='linear', C=10.0, gamma= 0.1) results_model_3 = cross_val_score(model_3, X, Y, cv=skfold) accuracy3 = results_model_3.mean() print("Accuracy 3 :", accuracy3) print("Leave One Out Cross-Validation : *********") from sklearn.model_selection import LeaveOneOut loocv = model_selection.LeaveOneOut() model_4 = svm.SVC(kernel='linear', C=10.0, gamma= 0.1) results_model_4 = cross_val_score(model_4, X, Y, cv=loocv) accuracy4 = results_model_4.mean() print("Accuracy 4 :", accuracy4) print("Repeated Random Test-Train Splits : *********") from sklearn.model_selection import ShuffleSplit kfold2 = model_selection.ShuffleSplit(n_splits=10, test_size=0.30, random_state=100) model_5 = svm.SVC(kernel='linear', C=10.0, gamma= 0.1) results_model_5 = cross_val_score(model_5, X, Y, cv=kfold2) accuracy5 = results_model_5.mean() print("Accuracy 5 :", accuracy5)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-121-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 122 Hyper-parameters are parameters that are not directly learnt within estimators. In scikit-learn they are passed as arguments to the constructor of the estimator classes. Typical examples include C, kernel and gamma for Support Vector Classifier, ect. The Exhaustive Grid Search provided by GridSearchCV exhaustively generates candidates from a grid of parameter values specified with the param_grid parameter. For instance, the following param_grid (SVM): param_grid = [ {'C': [1, 10, 100, 1000], 'kernel': ['linear']}, {'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']}, ] specifies that two grids should be explored: one with a linear kernel and C values in [1, 10, 100, 1000], and the second one with an RBF kernel, and the cross-product of C values ranging in [1, 10, 100, 1000] and gamma values in [0.001, 0.0001]. 5. Hyperparameter Tuning](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-122-2048.jpg)

![Hichem Felouat - hichemfel@gmail.com 124 5. Hyperparameter Tuning from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.model_selection import GridSearchCV from sklearn.metrics import classification_report from sklearn.svm import SVC dat = datasets.load_breast_cancer() print("Examples = ",dat.data.shape ," Labels = ", dat.target.shape) X_train, X_test, Y_train, Y_test = train_test_split(dat.data, dat.target, test_size= 0.20, random_state=100) param_grid = [ {'C': [1, 10, 100, 1000], 'kernel': ['linear']}, {'C': [2, 20, 200, 2000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']}, ] grid = GridSearchCV(SVC(), param_grid, refit = True, verbose = 3) grid.fit(X_train, Y_train) print('The best parameter after tuning :',grid.best_params_) print('our model looks after hyper-parameter tuning',grid.best_estimator_) grid_predictions = grid.predict(X_test) print(classification_report(Y_test, grid_predictions)) from sklearn.model_selection import RandomizedSearchCV from scipy.stats import expon param_rdsearch = { 'C': expon(scale=100), 'gamma': expon(scale=.1), 'kernel': ['rbf'], 'class_weight':['balanced', None] } clf_rds = RandomizedSearchCV(SVC(), param_rdsearch, n_iter=100) clf_rds.fit(X_train, Y_train) print("Best: %f using %s" % (clf_rds.best_score_, clf_rds.best_params_)) rds_predictions = clf_rds.predict(X_test) print(classification_report(Y_test, rds_predictions))](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-124-2048.jpg)

![Hichem Felouat - hichemfel@gmail.com 126 6. Pipeline: chaining estimators from sklearn.datasets import load_breast_cancer from sklearn.pipeline import Pipeline, FeatureUnion from sklearn.svm import SVC from sklearn.decomposition import PCA from sklearn.impute import SimpleImputer from sklearn.preprocessing import StandardScaler import numpy as np from sklearn.model_selection import train_test_split from sklearn import metrics dat = load_breast_cancer() X = dat.data Y = dat.target print("Examples = ",X.shape ," Labels = ", Y.shape) X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.3, random_state=100) model_pipeline = Pipeline(steps=[ ("feature_union", FeatureUnion([ ('missing_values',SimpleImputer(missing_values=np.nan, strategy='mean')), ('scale', StandardScaler()), ("reduce_dim", PCA(n_components=10)), ])), ('clf', SVC(kernel='rbf', gamma= 0.001, C=5)) ]) model_pipeline.fit(X_train, y_train) predictions = model_pipeline.predict(X_test) print(" Accuracy :",metrics.accuracy_score(y_test, predictions))](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-126-2048.jpg)



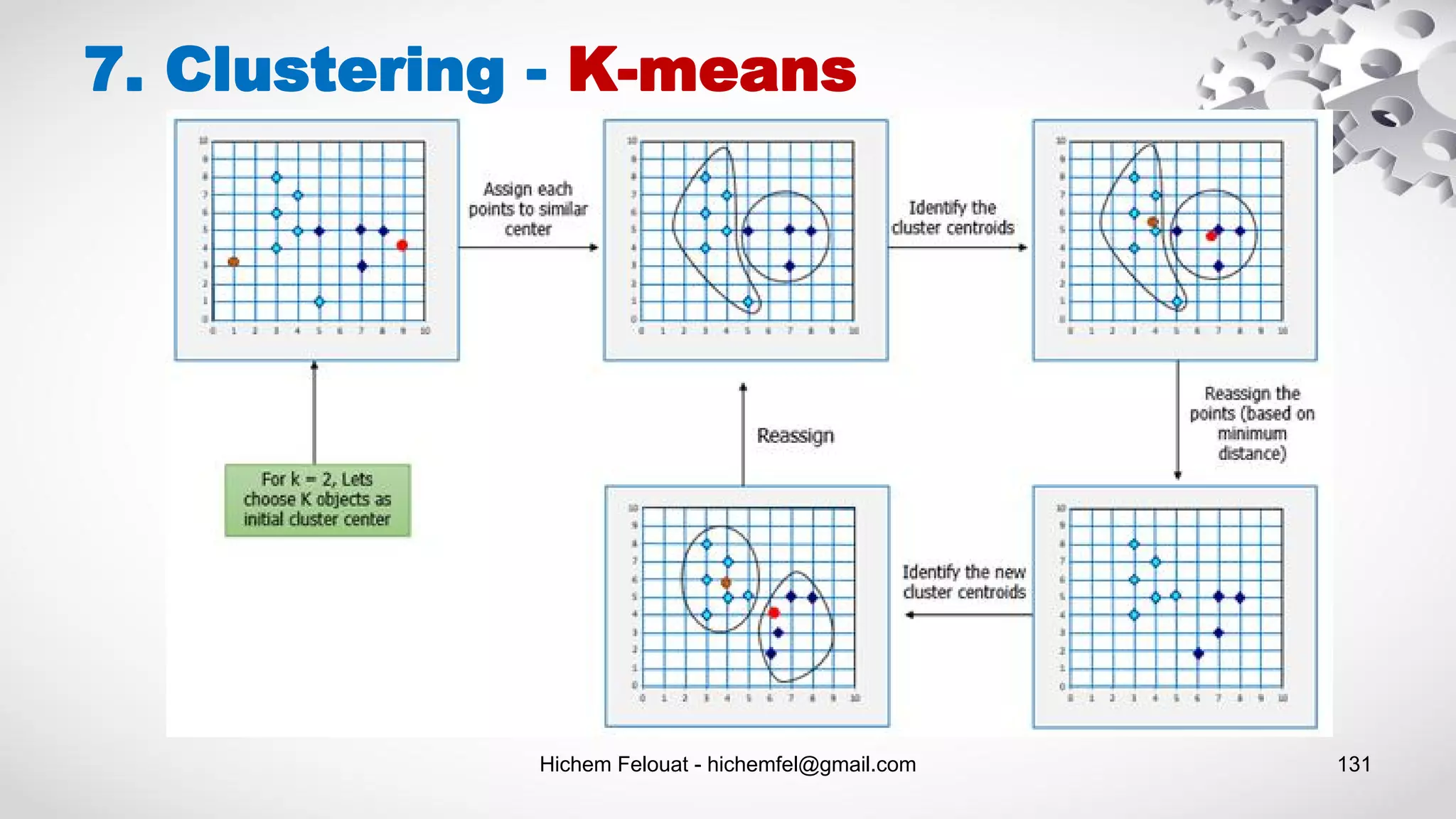

![Hichem Felouat - hichemfel@gmail.com 133 7. Clustering - K-means from sklearn import metrics labels_true = [0, 0, 0, 1, 1, 1] labels_pred = [0, 0, 1, 1, 2, 2] metrics.adjusted_rand_score(labels_true, labels_pred) good_init = np.array([[-3, 3], [-3, 2], [-3, 1], [-1, 2], [0, 2]]) kmeans = KMeans(n_clusters=5, init=good_init, n_init=1) Centroid initialization methods : Clustering performance evaluation :](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-133-2048.jpg)
![Hichem Felouat - hichemfel@gmail.com 134 import matplotlib.pyplot as plt import seaborn as sns; sns.set() # for plot styling import numpy as np from sklearn.datasets.samples_generator import make_blobs # n_featuresint, optional (default=2) X, y_true = make_blobs(n_samples=300, centers=4,cluster_std=1.5, random_state=100) print("Examples = ",X.shape) # Visualize the Data fig, ax = plt.subplots(figsize=(8,5)) ax.scatter(X[:, 0], X[:, 1], s=50) ax.set_title("Visualize the Data") ax.set_xlabel("X") ax.set_ylabel("Y") plt.show() # Create Clusters from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=4) kmeans.fit(X) y_kmeans = kmeans.predict(X) print("the 4centroids that the algorithm found: n",kmeans.cluster_centers_) # Visualize the results fig, ax = plt.subplots(figsize=(8,5)) ax.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis') centers = kmeans.cluster_centers_ ax.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5); ax.set_title("Visualize the results") ax.set_xlabel("X") ax.set_ylabel("Y") plt.show() 7. Clustering - K-means # Assign new instances to the cluster whose centroid is closest: X_new = np.array([[0, 2], [3, 2], [-3, 3], [-3, 2.5]]) y_kmeans_new = kmeans.predict(X_new) # The transform() method measures the distance from each instance to every centroid: print("The distance from each instance to every centroid: n",kmeans.transform(X_new)) # Visualize the new results fig, ax = plt.subplots(figsize=(8,5)) ax.scatter(X_new[:, 0], X_new[:, 1], c=y_kmeans_new, s=50, cmap='viridis') centers = kmeans.cluster_centers_ ax.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5); ax.set_title("Visualize the new results") ax.set_xlabel("X") ax.set_ylabel("Y") plt.show() print("inertia : ",kmeans.inertia_) print("score : ", kmeans.score(X))](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-134-2048.jpg)


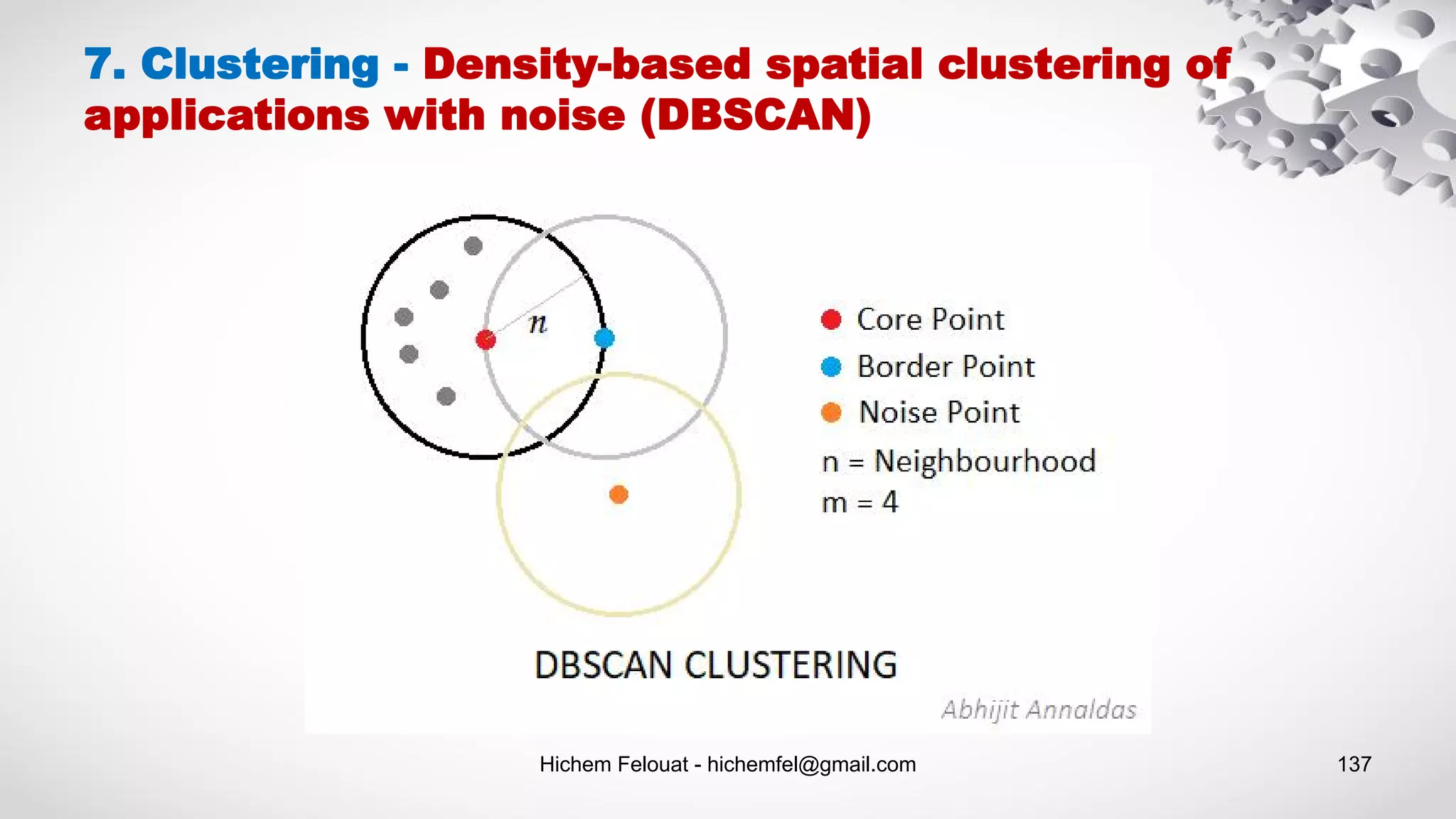
![Hichem Felouat - hichemfel@gmail.com 138 from sklearn.cluster import DBSCAN import matplotlib.pyplot as plt from sklearn.datasets import make_moons X, y = make_moons(n_samples=1000, noise=0.05) dbscan = DBSCAN(eps=0.05, min_samples=5) dbscan.fit(X) # The labels of all the instances. Notice that some instances have a cluster index equal to –1, which means that # they are considered as anomalies by the algorithm. print("The labels of all the instances : n",dbscan.labels_) # The indices of the core instances print("The indices of the core instances : n Len = ",len(dbscan.core_sample_indices_), "n", dbscan.core_sample_indices_) # The core instances print("the core instances : n", dbscan.components_) # Visualize the results fig, ax = plt.subplots(figsize=(8,5)) ax.scatter(X[:, 0], X[:, 1], c= dbscan.labels_, s=50, cmap='viridis') ax.set_title("Visualize the results") ax.set_xlabel("X") ax.set_ylabel("Y") plt.show() 7. Clustering - Density-based spatial clustering of applications with noise (DBSCAN)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-138-2048.jpg)



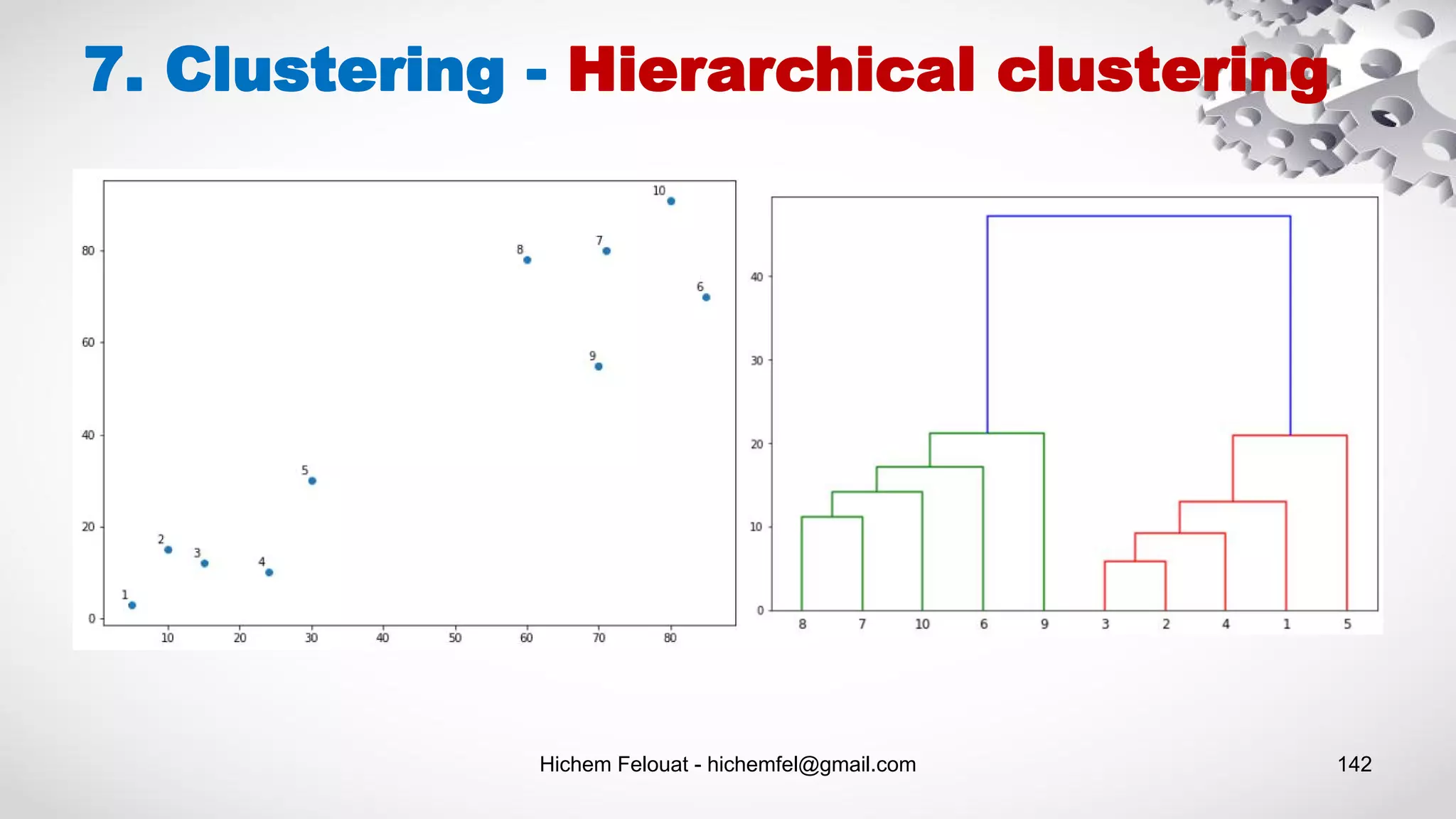
![Hichem Felouat - hichemfel@gmail.com 143 import matplotlib.pyplot as plt import numpy as np from scipy.cluster.hierarchy import dendrogram from sklearn.cluster import AgglomerativeClustering def plot_dendrogram(model, **kwargs): # Create linkage matrix and then plot the dendrogram # create the counts of samples under each node counts = np.zeros(model.children_.shape[0]) n_samples = len(model.labels_) for i, merge in enumerate(model.children_): current_count = 0 for child_idx in merge: if child_idx < n_samples: current_count += 1 # leaf node else: current_count += counts[child_idx - n_samples] counts[i] = current_count linkage_matrix = np.column_stack([model.children_, model.distances_, counts]).astype(float) # Plot the corresponding dendrogram dendrogram(linkage_matrix, **kwargs) 7. Clustering - Hierarchical clustering X = np.array([[5,3],[10,15],[15,12],[24,10],[30,30], [85,70],[71,80],[60,78],[70,55],[80,91],]) model = AgglomerativeClustering(distance_threshold=0, n_clusters=None) model.fit(X) plt.title("Hierarchical Clustering Dendrogram") # plot the top three levels of the dendrogram plot_dendrogram(model, truncate_mode="level", p=3) plt.xlabel("Number of points in node (or index of point if no parenthesis).") plt.show() """ import scipy.cluster.hierarchy as shc plt.figure(figsize=(10, 7)) plt.title("Customer Dendograms") dend = shc.dendrogram(shc.linkage(X, method='ward')) """](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-143-2048.jpg)
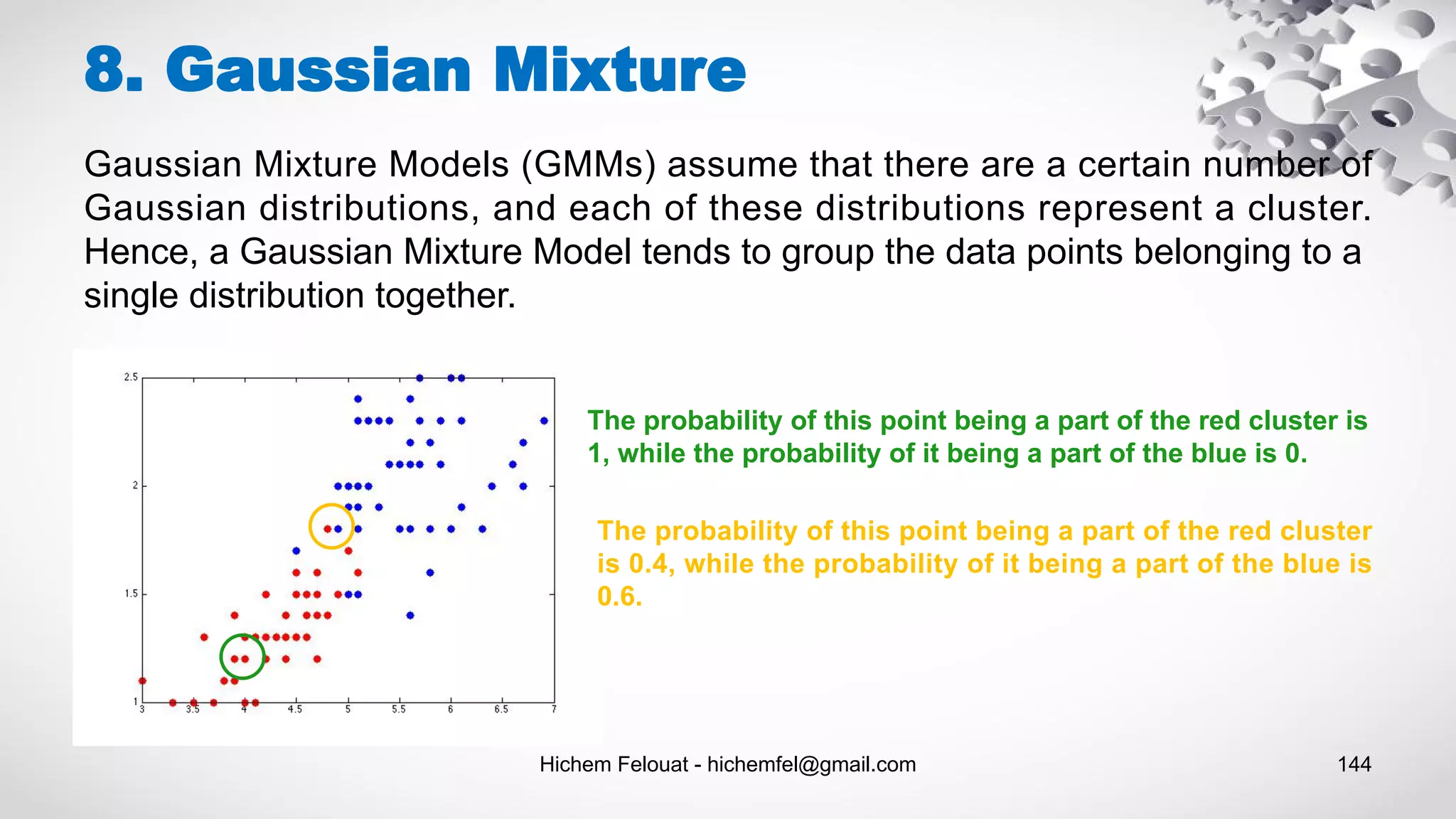
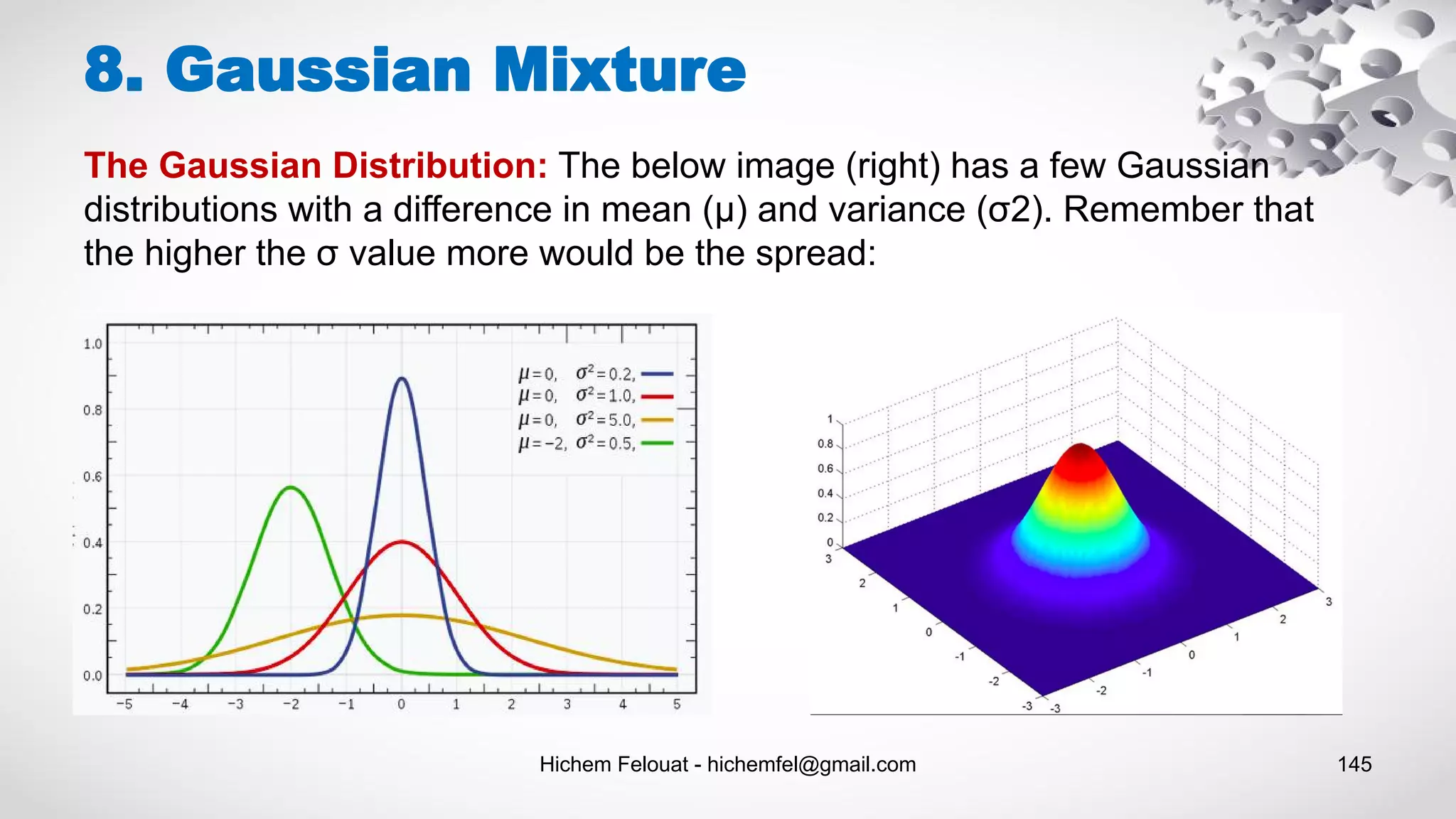
![Hichem Felouat - hichemfel@gmail.com 146 8. Gaussian Mixture import matplotlib.pyplot as plt import numpy as np from sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0) # training gaussian mixture model from sklearn.mixture import GaussianMixture gm = GaussianMixture(n_components=4) gm.fit(X) print("The weights of each mixture components:n",gm.weights_) print("The mean of each mixture component:n",gm.means_) print("The covariance of each mixture component:n",gm.covariances_) print("check whether or not the algorithm converged: ", gm.converged_) print("nbr of iterations: ",gm.n_iter_) #print("score: n",gm.score_samples(X)) from matplotlib.patches import Ellipse def draw_ellipse(position, covariance, ax=None, **kwargs): """Draw an ellipse with a given position and covariance""" ax = ax or plt.gca() # Convert covariance to principal axes if covariance.shape == (2, 2): U, s, Vt = np.linalg.svd(covariance) angle = np.degrees(np.arctan2(U[1, 0], U[0, 0])) width, height = 2 * np.sqrt(s) else: angle = 0 width, height = 2 * np.sqrt(covariance) # Draw the Ellipse for nsig in range(1, 4): ax.add_patch(Ellipse(position, nsig * width, nsig * height, angle, **kwargs)) def plot_gm(gmm, X, label=True, ax=None): ax = ax or plt.gca() labels = gmm.fit(X).predict(X) if label: ax.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap='viridis', zorder=2) else: ax.scatter(X[:, 0], X[:, 1], s=40, zorder=2) ax.axis('equal') w_factor = 0.2 / gmm.weights_.max() for pos, covar, w in zip(gmm.means_, gmm.covariances_, gmm.weights_): draw_ellipse(pos, covar, alpha=w * w_factor) plot_gm(gm, X)](https://image.slidesharecdn.com/machinelearningalgorithms-200927153935/75/Machine-Learning-Algorithms-146-2048.jpg)



This document provides an overview of machine learning algorithms and scikit-learn. It begins with an introduction and table of contents. Then it covers topics like dataset loading from files, pandas, scikit-learn datasets, preprocessing data like handling missing values, feature selection, dimensionality reduction, training and test sets, supervised and unsupervised learning models, and saving/loading machine learning models. For each topic, it provides code examples and explanations.