Downloaded 27 times















![Model representation On the wire syntax = “proto3”; // Description of the trained model. message ModelDescriptor { // Model name string name = 1; // Human readable description. string description = 2; // Data type for which this model is applied. string dataType = 3; // Model type enum ModelType { TENSORFLOW = 0; TENSORFLOWSAVED = 2; PMML = 2; }; ModelType modeltype = 4; oneof MessageContent { // Byte array containing the model bytes data = 5; string location = 6; } } Internal
trait Model { def score(input : AnyVal) : AnyVal def cleanup() : Unit def toBytes() : Array[Byte] def getType : Long }
trait ModelFactoryl { def create(input : ModelDescriptor) : Model def restore(bytes : Array[Byte]) : Model } 18](https://image.slidesharecdn.com/lb-presentation-operationalizing-machine-learning-v3copy2-181102130038/75/Machine-Learning-At-Speed-Operationalizing-ML-For-Real-Time-Data-Streams-18-2048.jpg)






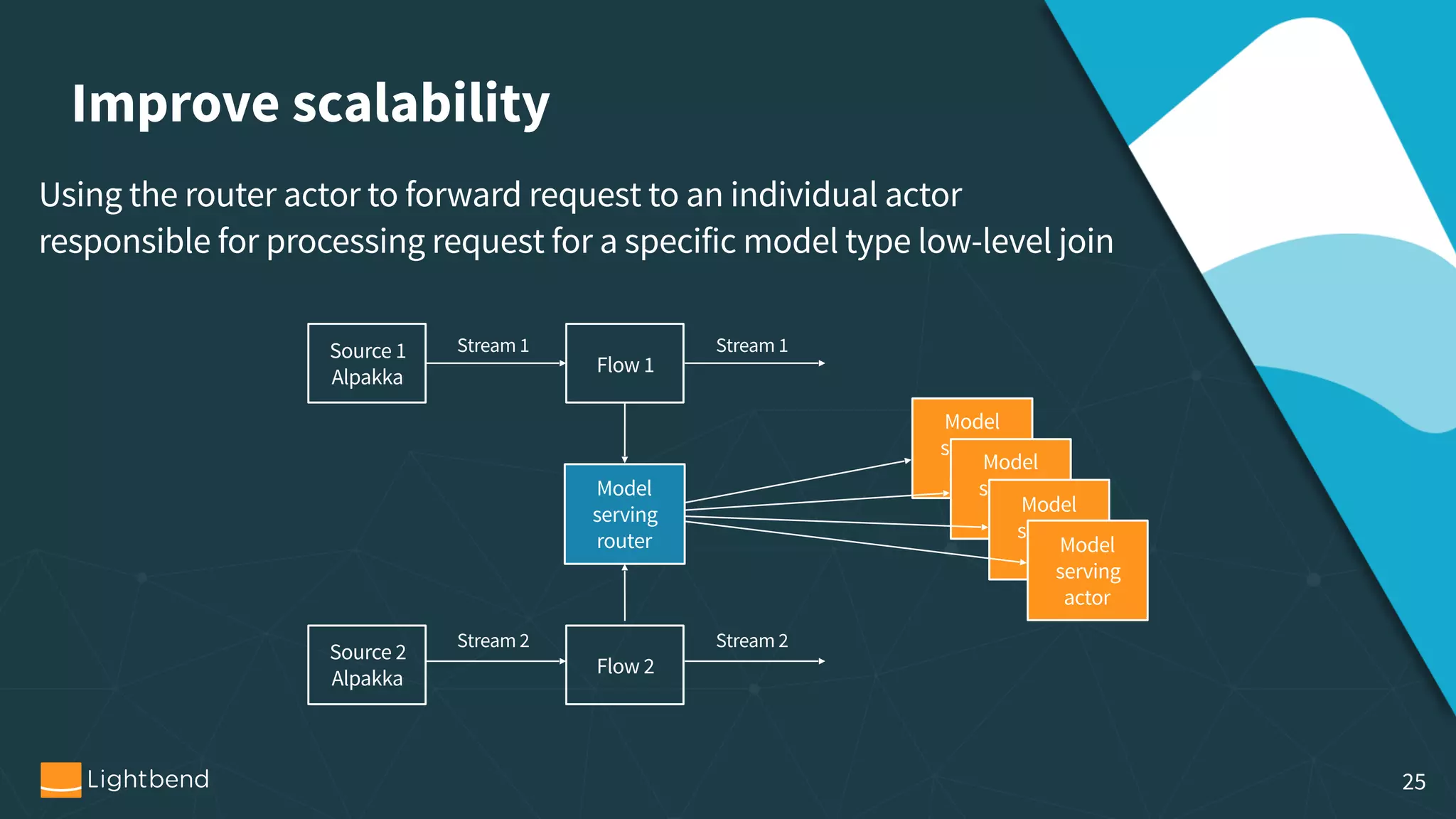


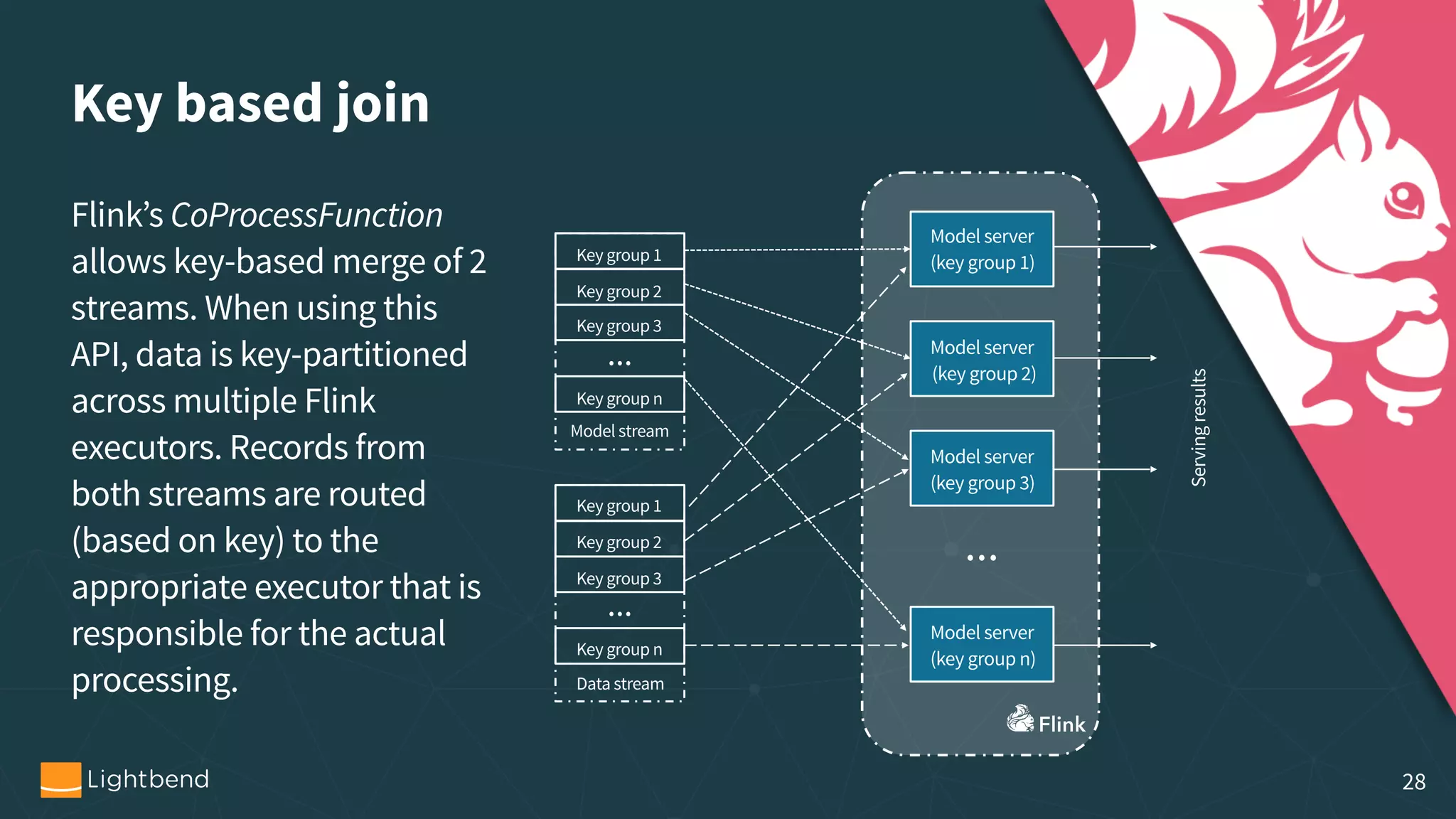
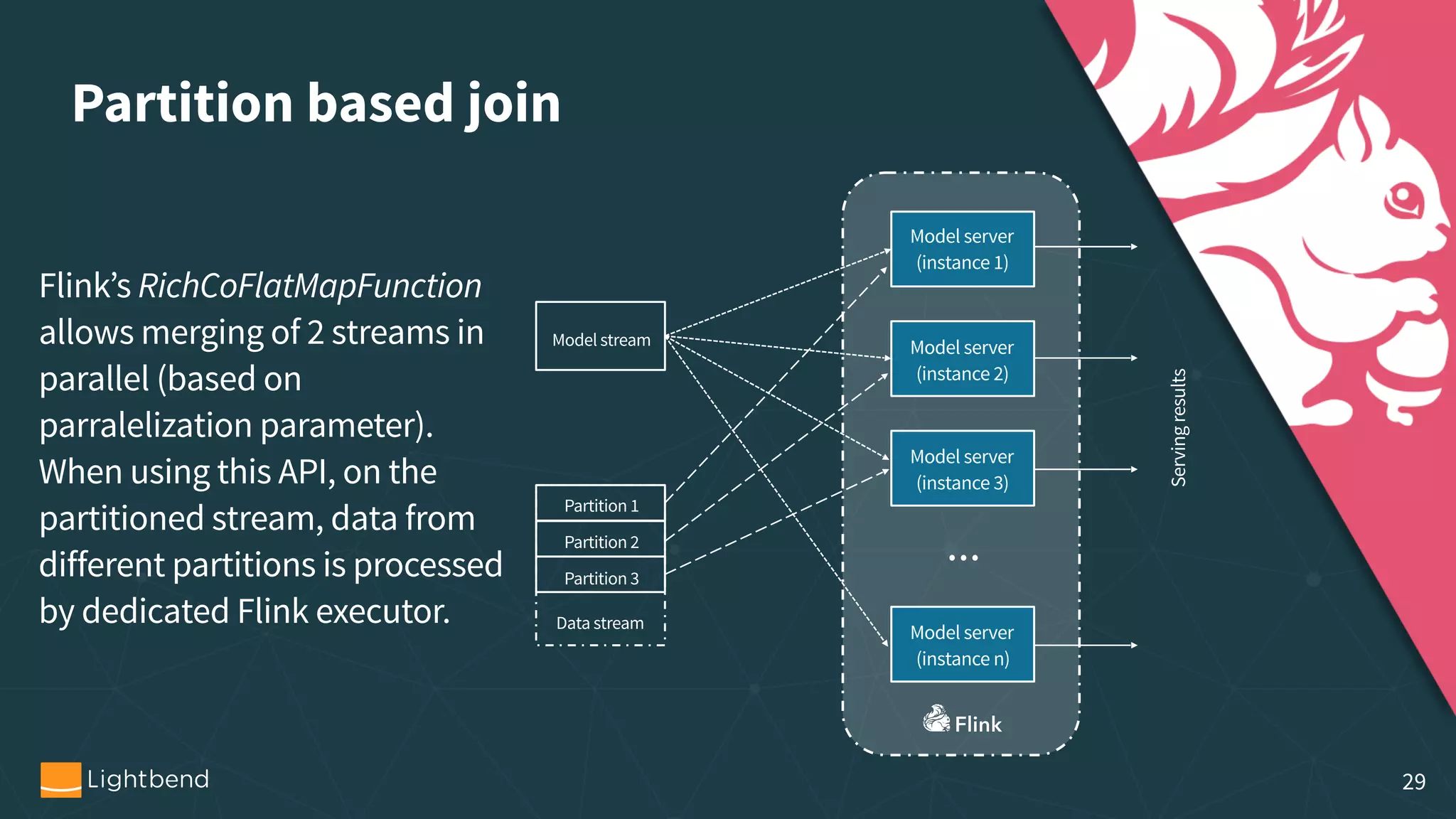





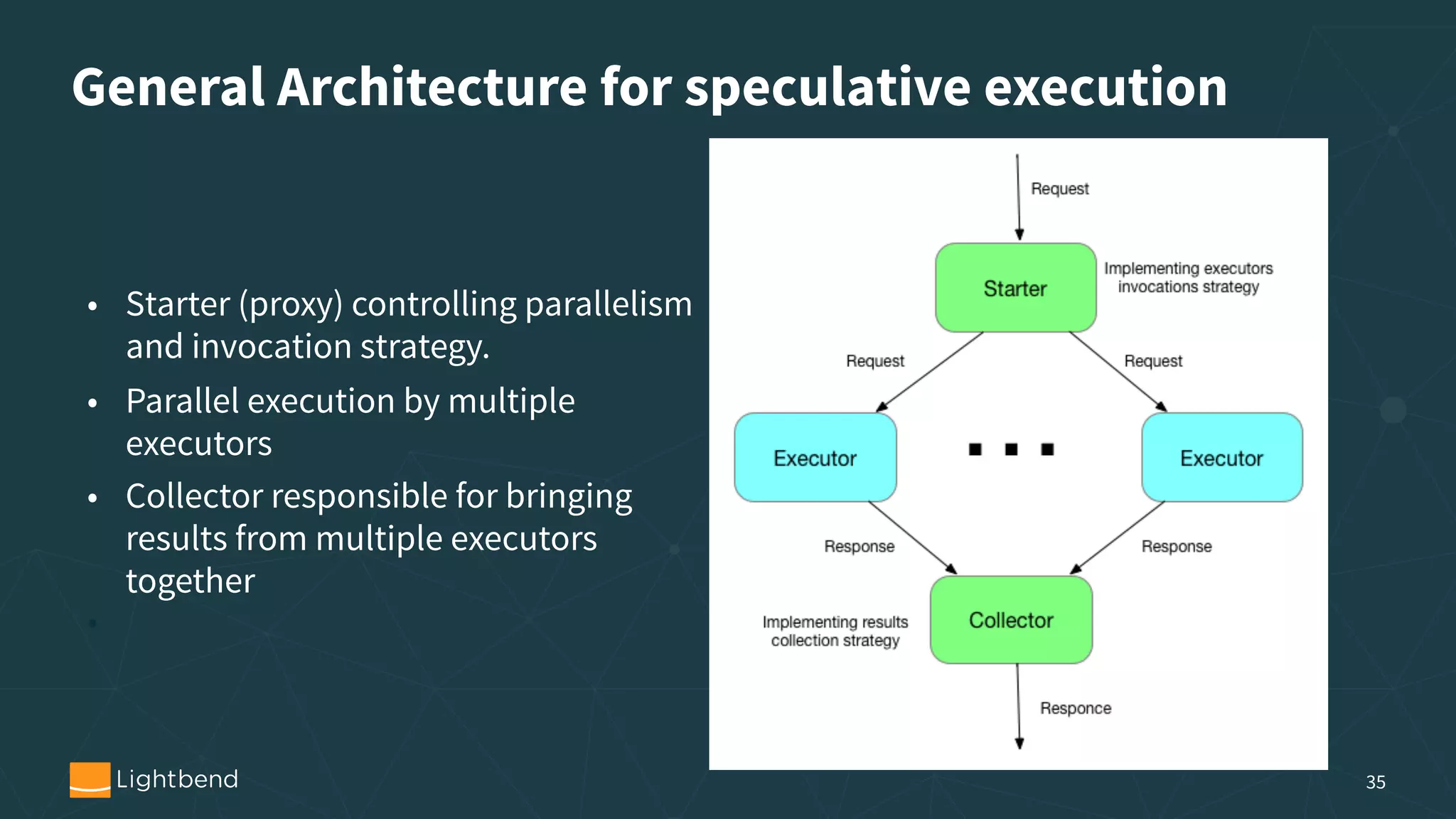





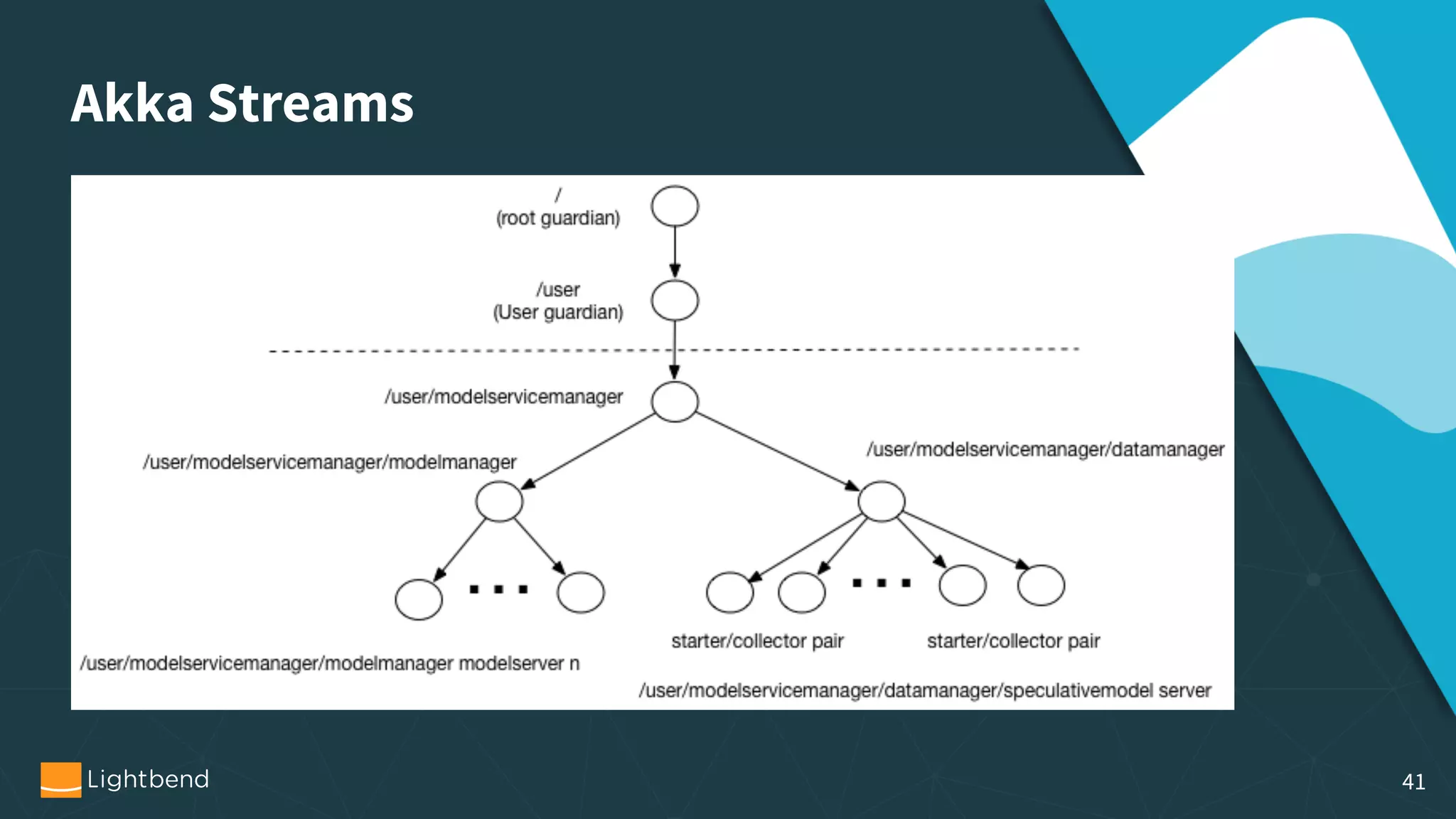
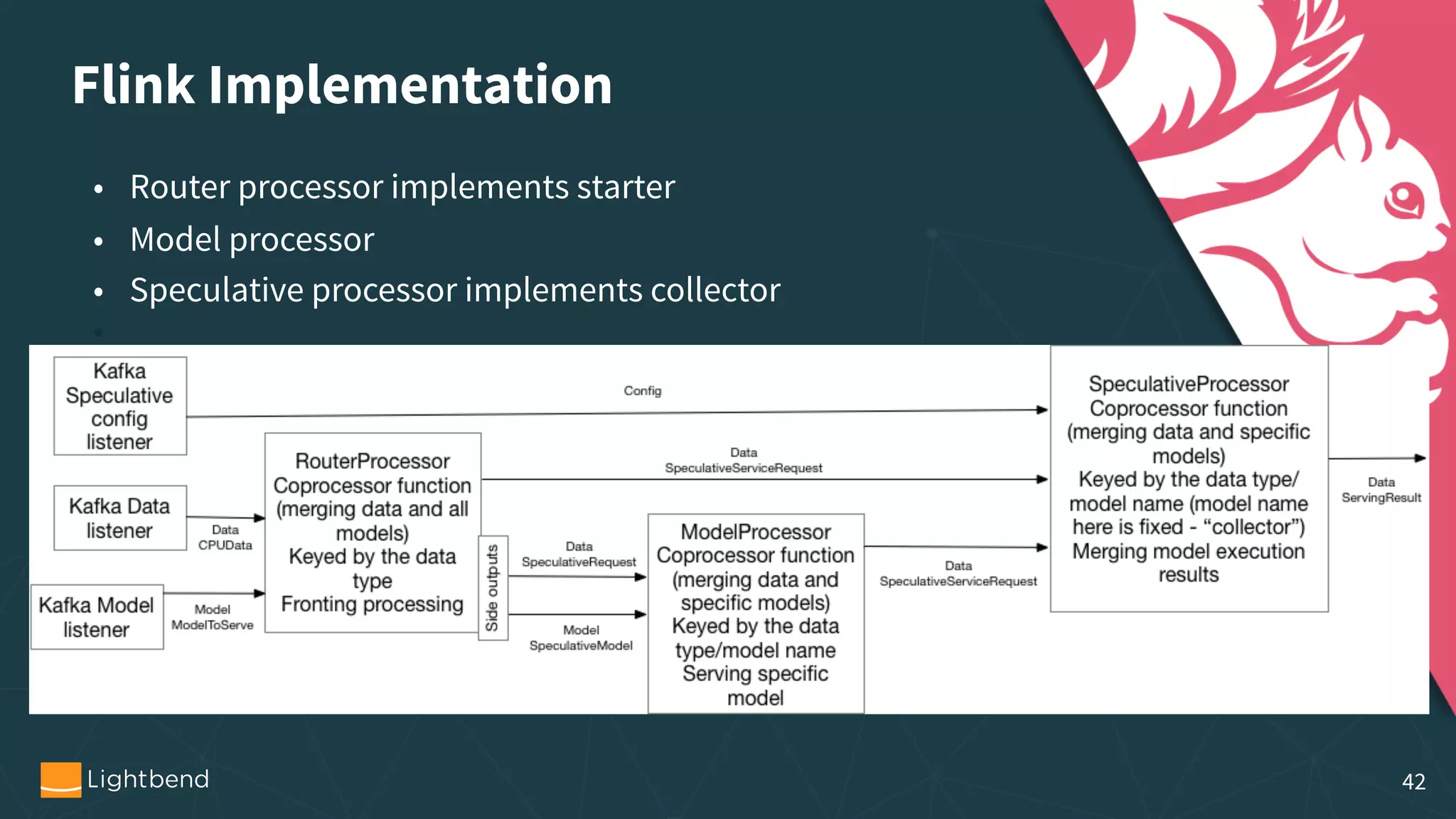



The document discusses the concepts, pipelines, and lifecycle management associated with machine learning model serving, emphasizing the need for effective data transformation and model evaluation techniques. It examines different approaches to model representation, such as exporting models as data using formats like PMML and TensorFlow, and the importance of model tracking and speculative execution for performance optimization. The document also covers architectural considerations and implementation options for stream processing engines, highlighting their scalability and fault tolerance.