Downloaded 70 times




![Document Model • Matches Application Objects • Flexible • High performance { "customer_id" : 123, "first_name" : ”John", "last_name" : "Smith", "address" : { "street": "123 Main Street", "city": "Houston", "state": "TX", "zip_code": "77027" } policies: [ { policy_number : 13, description: “short term”, deductible: 500 }, { policy_number : 14, description: “dental”, visits: […] } ] }](https://image.slidesharecdn.com/mongodb-at-scale-150527195531-lva1-app6891/75/Scaling-MongoDB-6-2048.jpg)









![mongod log files Sun Jun 29 06:35:37.646 [conn2] query test.docs query: { parent.company: "22794", parent.employeeId: "83881" } ntoreturn:1 ntoskip:0 nscanned:806381 keyUpdates:0 numYields: 5 locks(micros) r:2145254 nreturned:0 reslen:20 1156ms](https://image.slidesharecdn.com/mongodb-at-scale-150527195531-lva1-app6891/75/Scaling-MongoDB-17-2048.jpg)

















The document discusses strategies for scaling MongoDB, emphasizing schema design, indexing, and the use of the WiredTiger storage engine to improve performance and reduce storage needs. It provides tips for optimizing operations, such as vertical and horizontal scaling, and highlights the importance of monitoring and using the MongoDB Management Service (MMS) for efficient database management. Key points include schema patterns, indexing strategies, and best practices for selecting effective shard keys to enhance database performance.
Overview of achieving scale with MongoDB with a focus on optimization tips, different scaling types, and operations team scaling.
Discussion on schema design for MongoDB, highlighting flexible document models, denormalization, and design patterns.
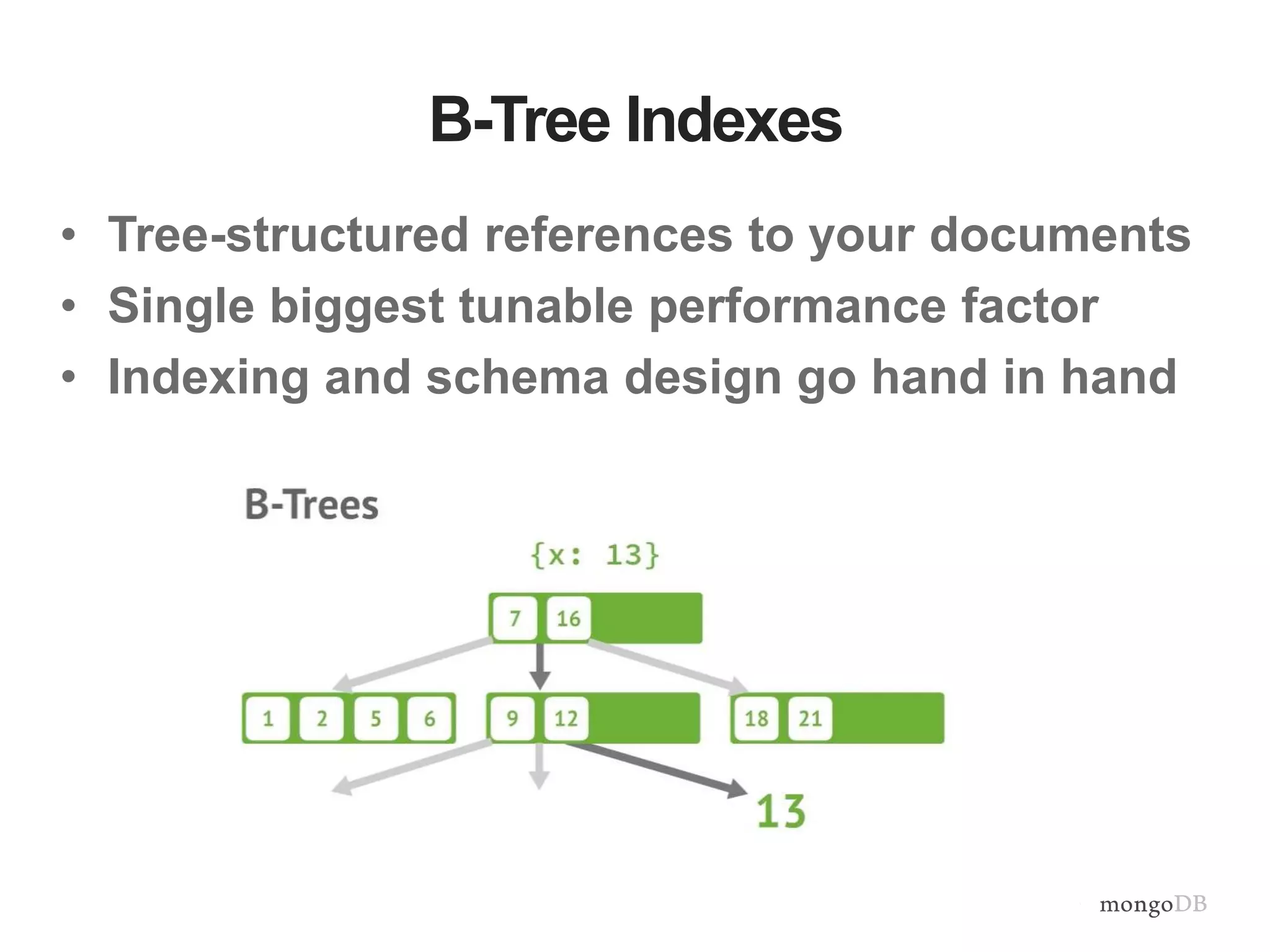
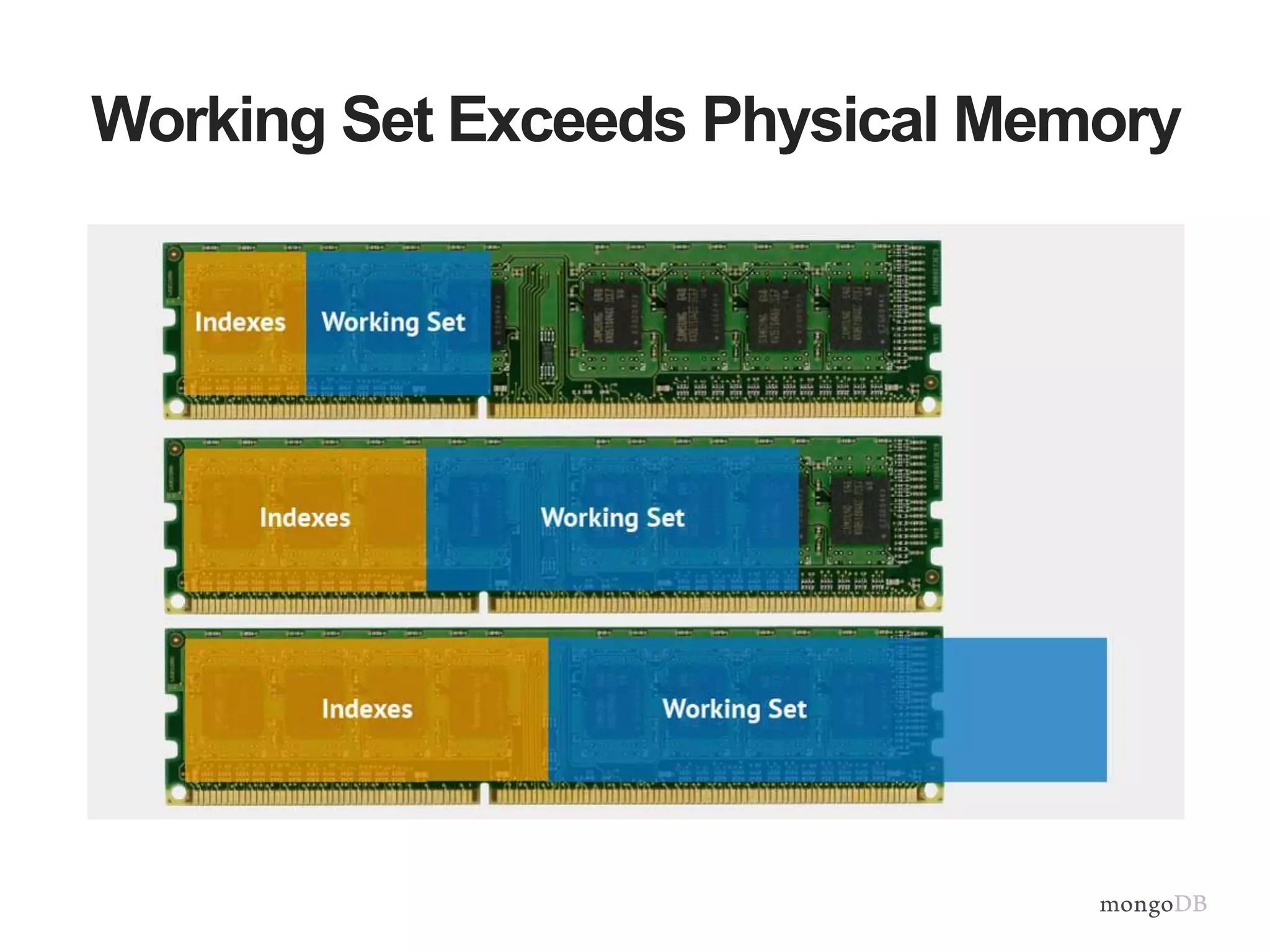
Focus on optimization through indexing including B-Tree indexes, common mistakes, and strategies to improve query performance.
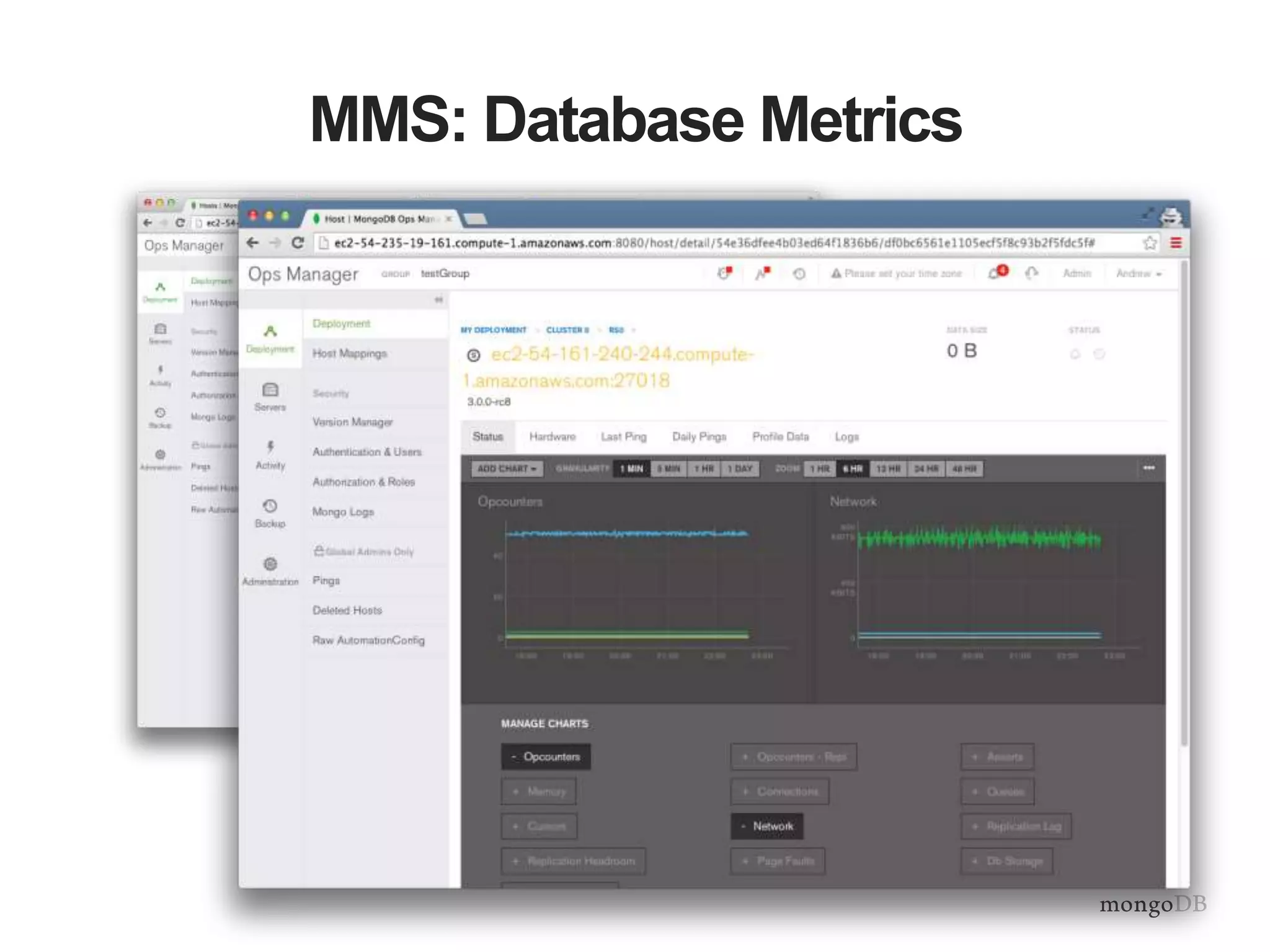
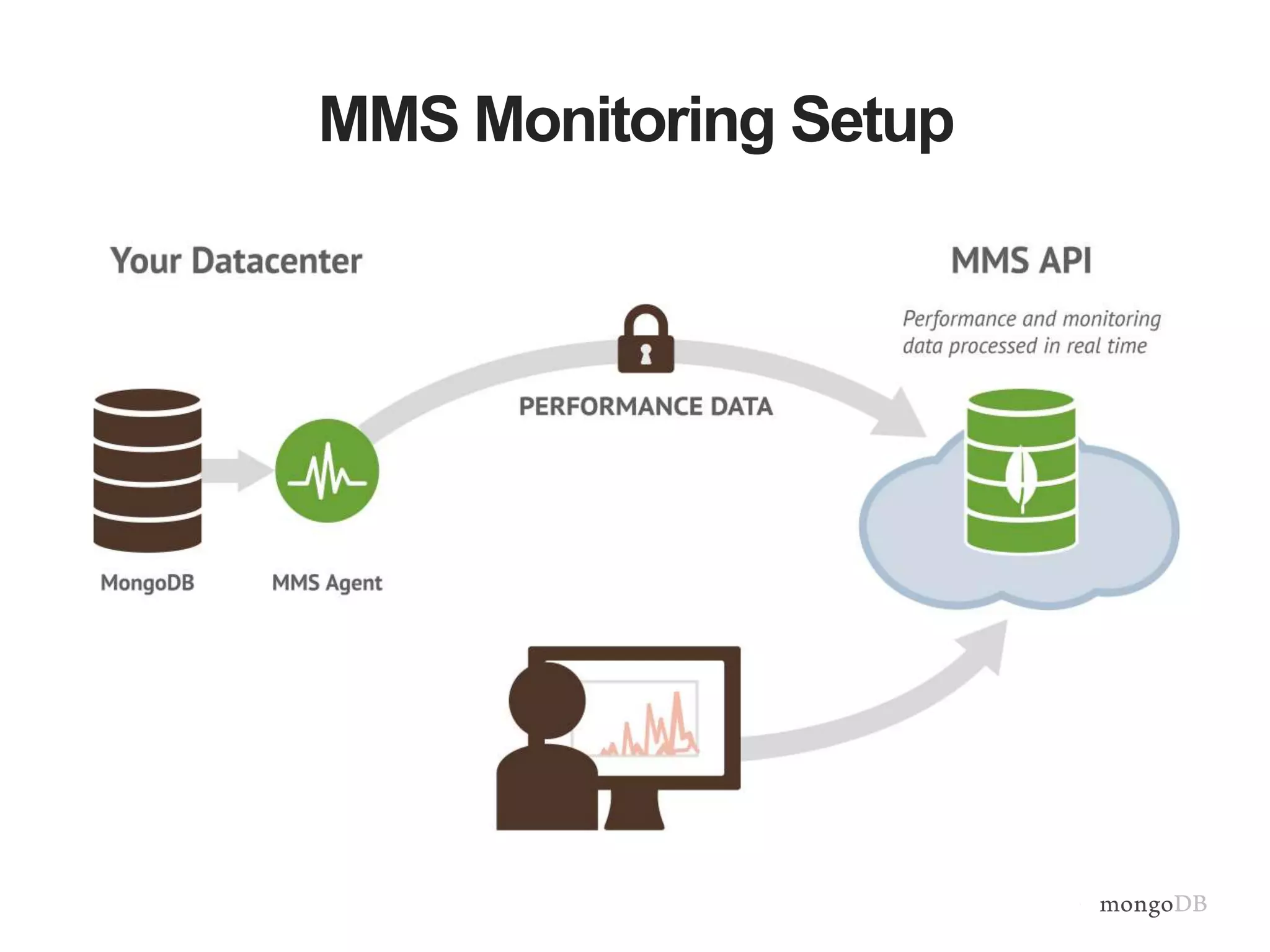
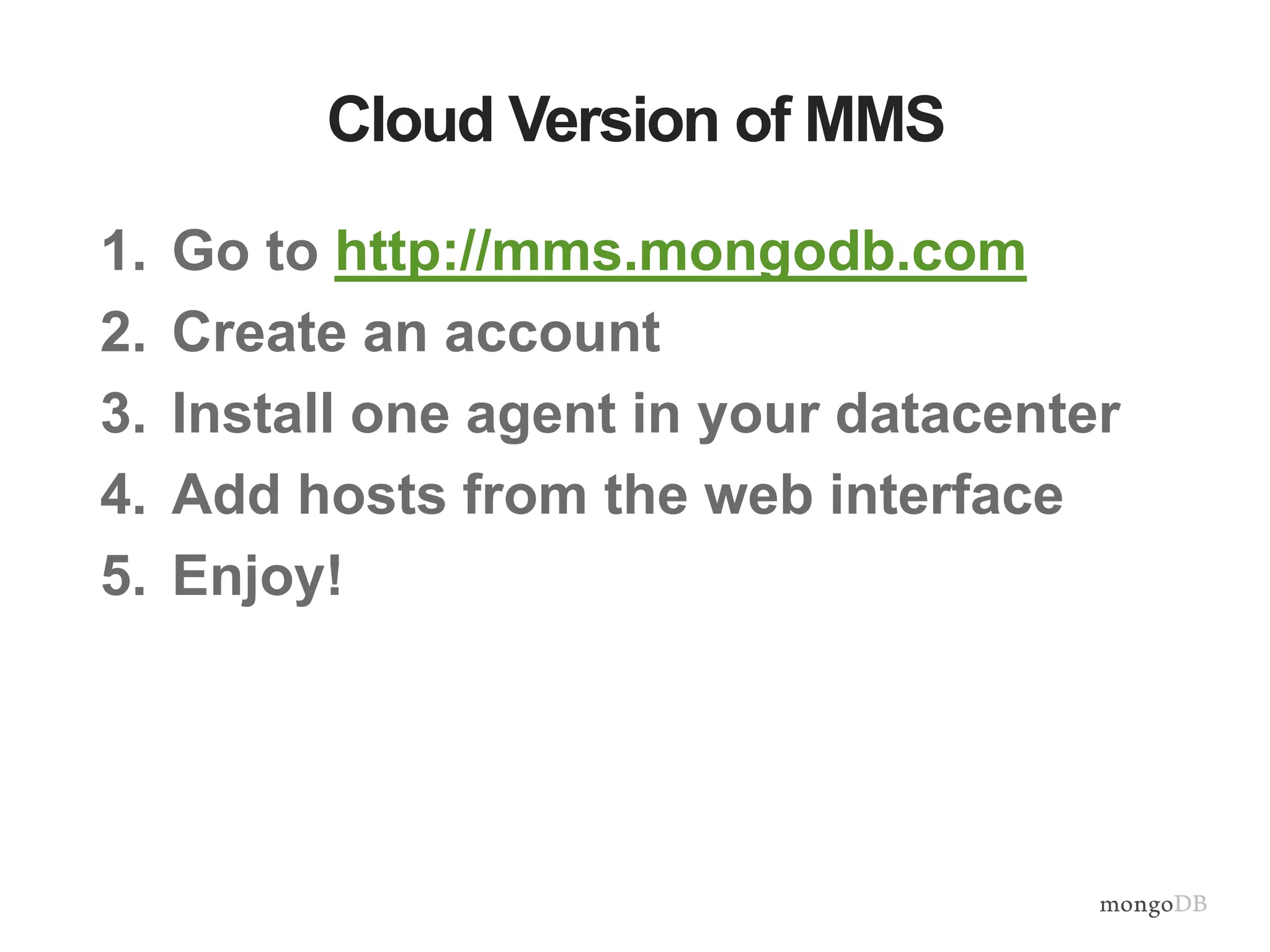
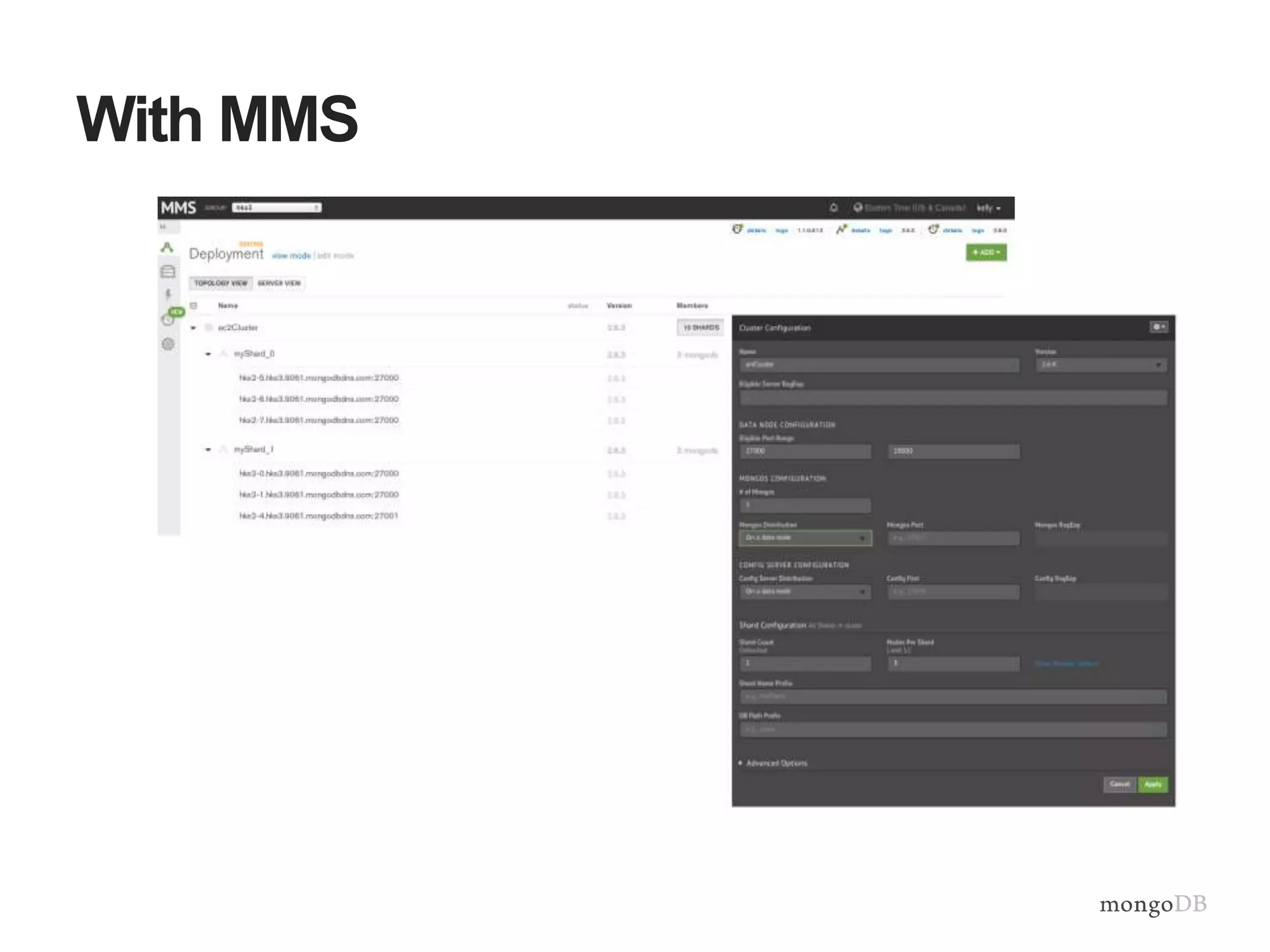
Importance of monitoring, setup of MongoDB Management Services (MMS) for automated backup and monitoring.
Benefits of the WiredTiger storage engine with increased performance (7x-10x) and storage efficiency (50%-80% less storage).
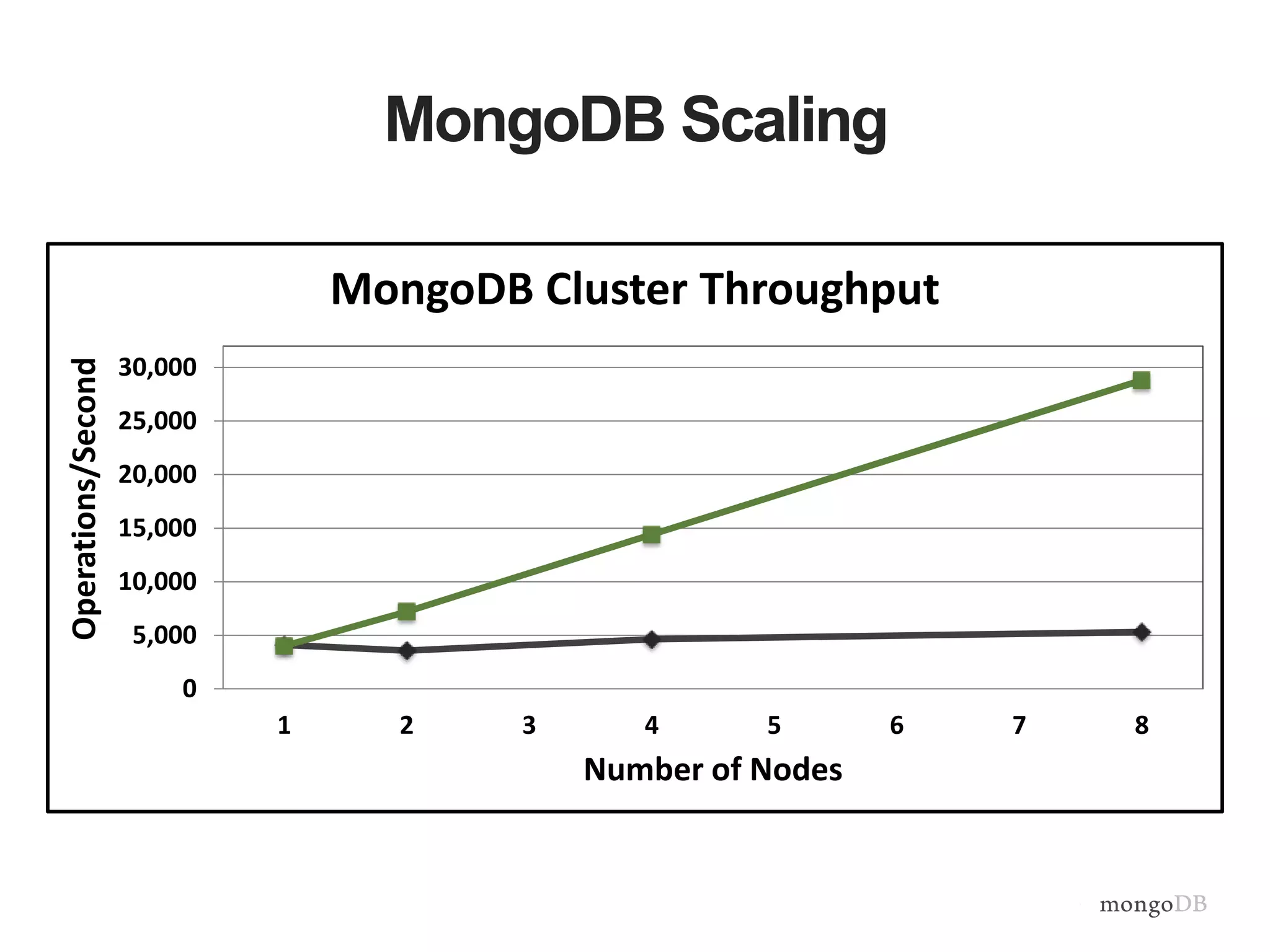
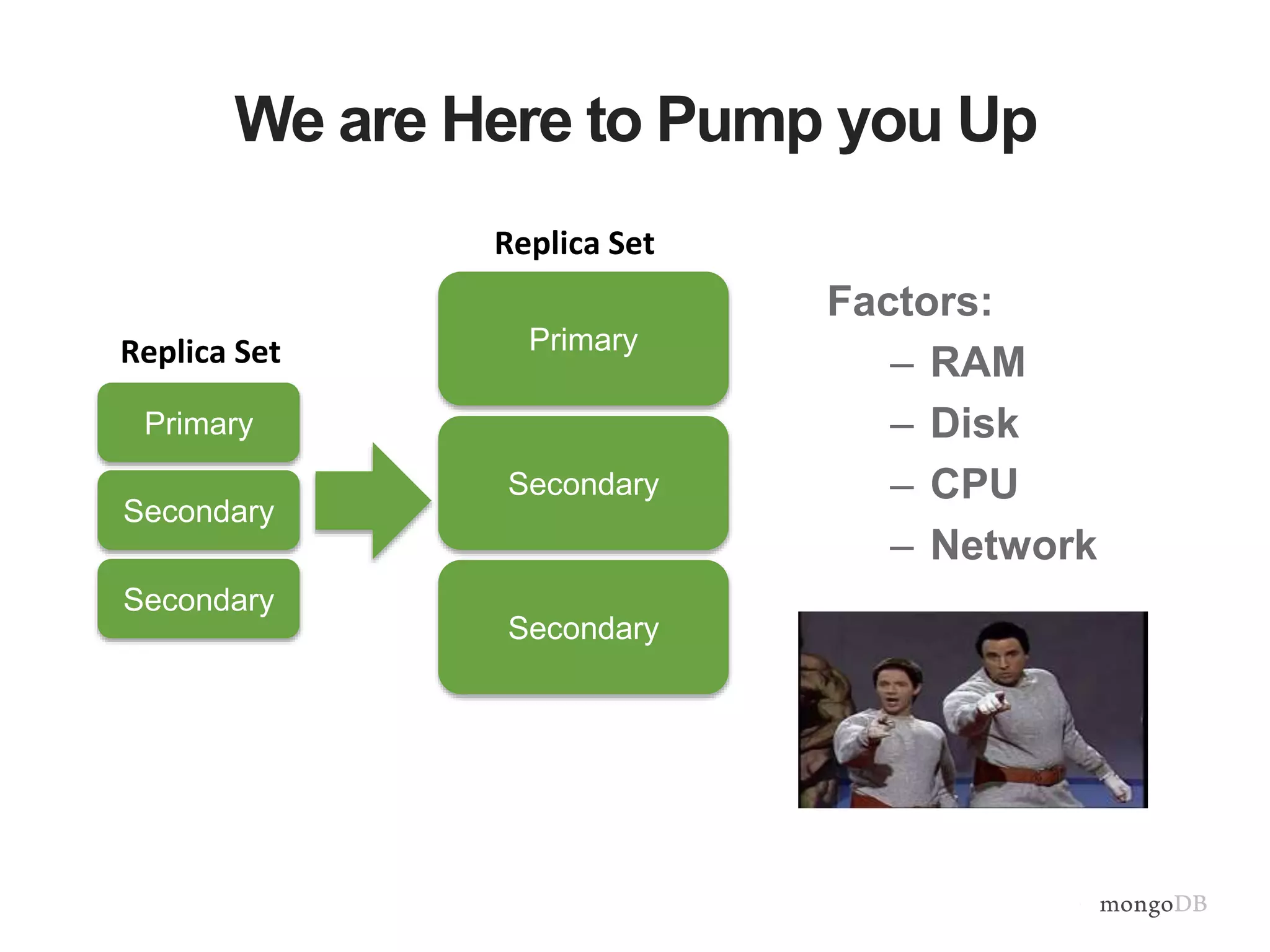
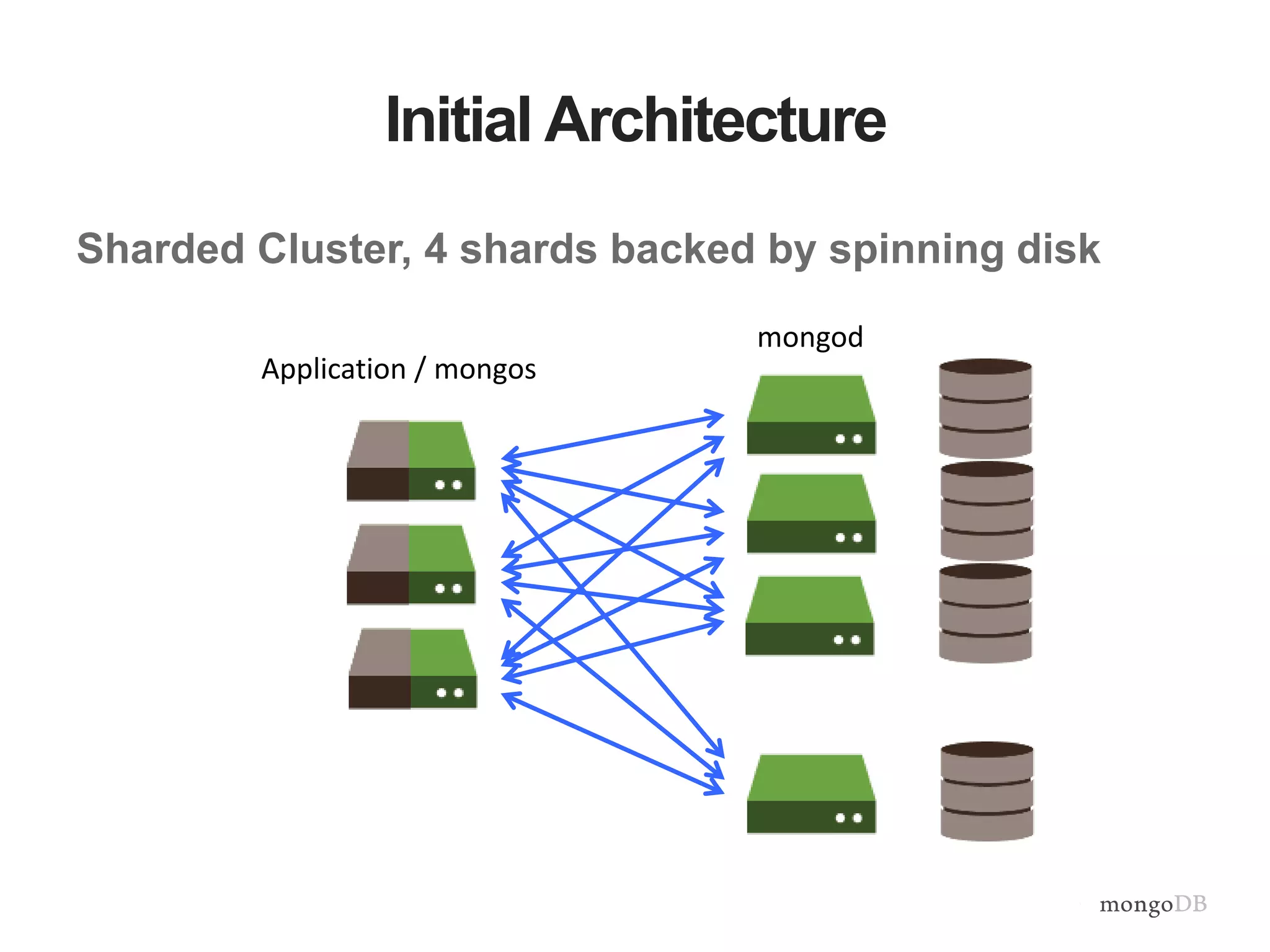
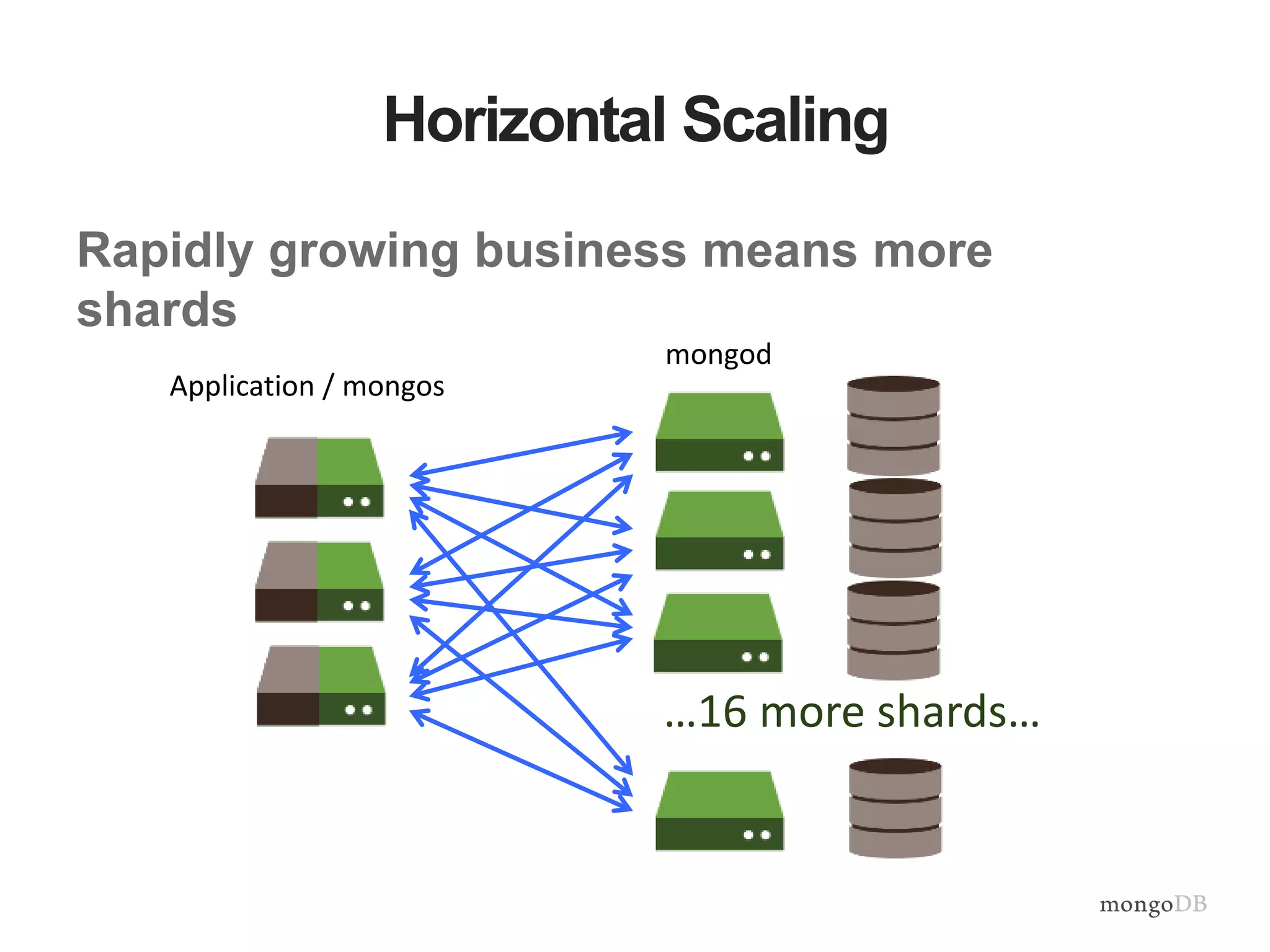
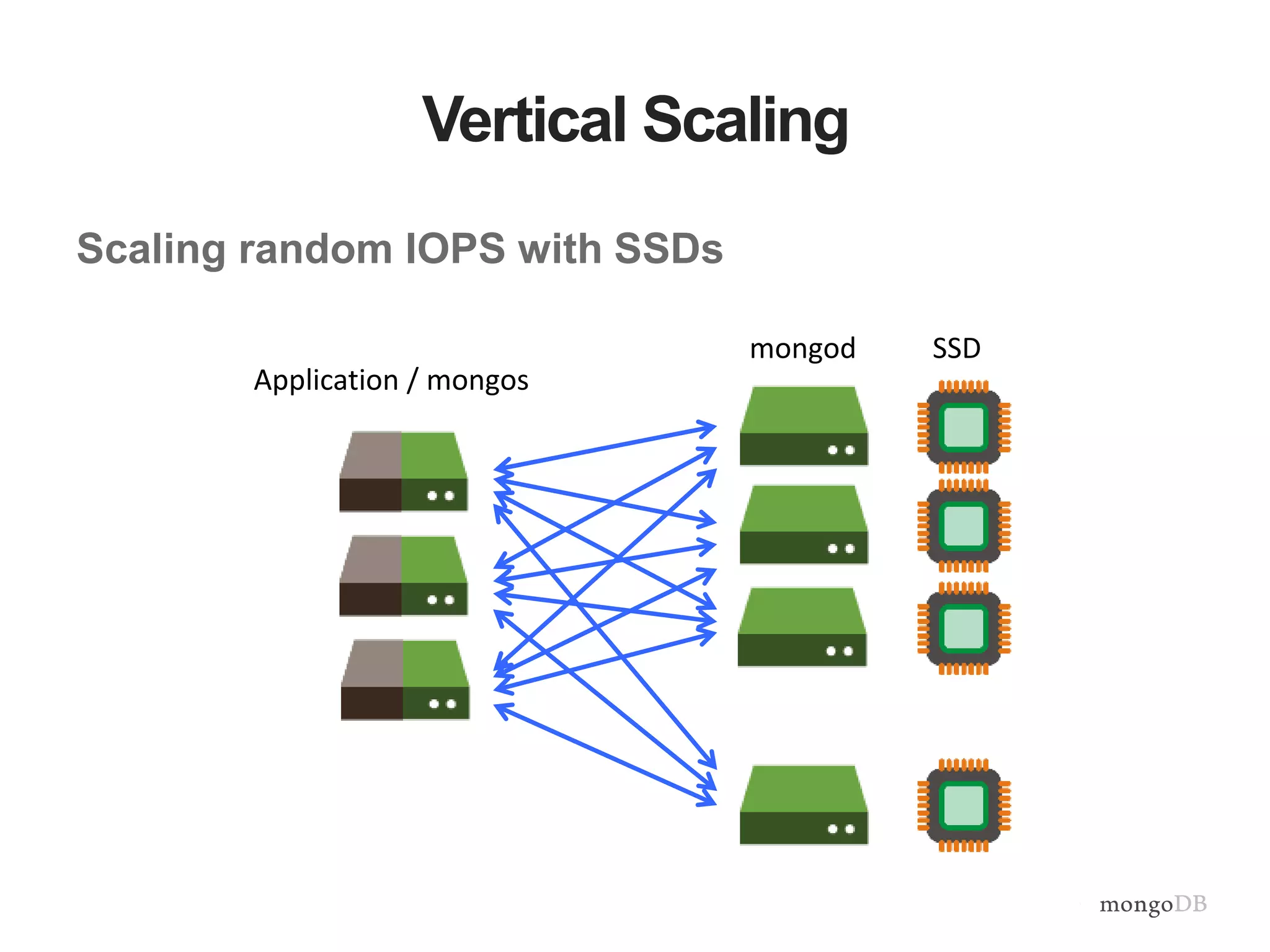
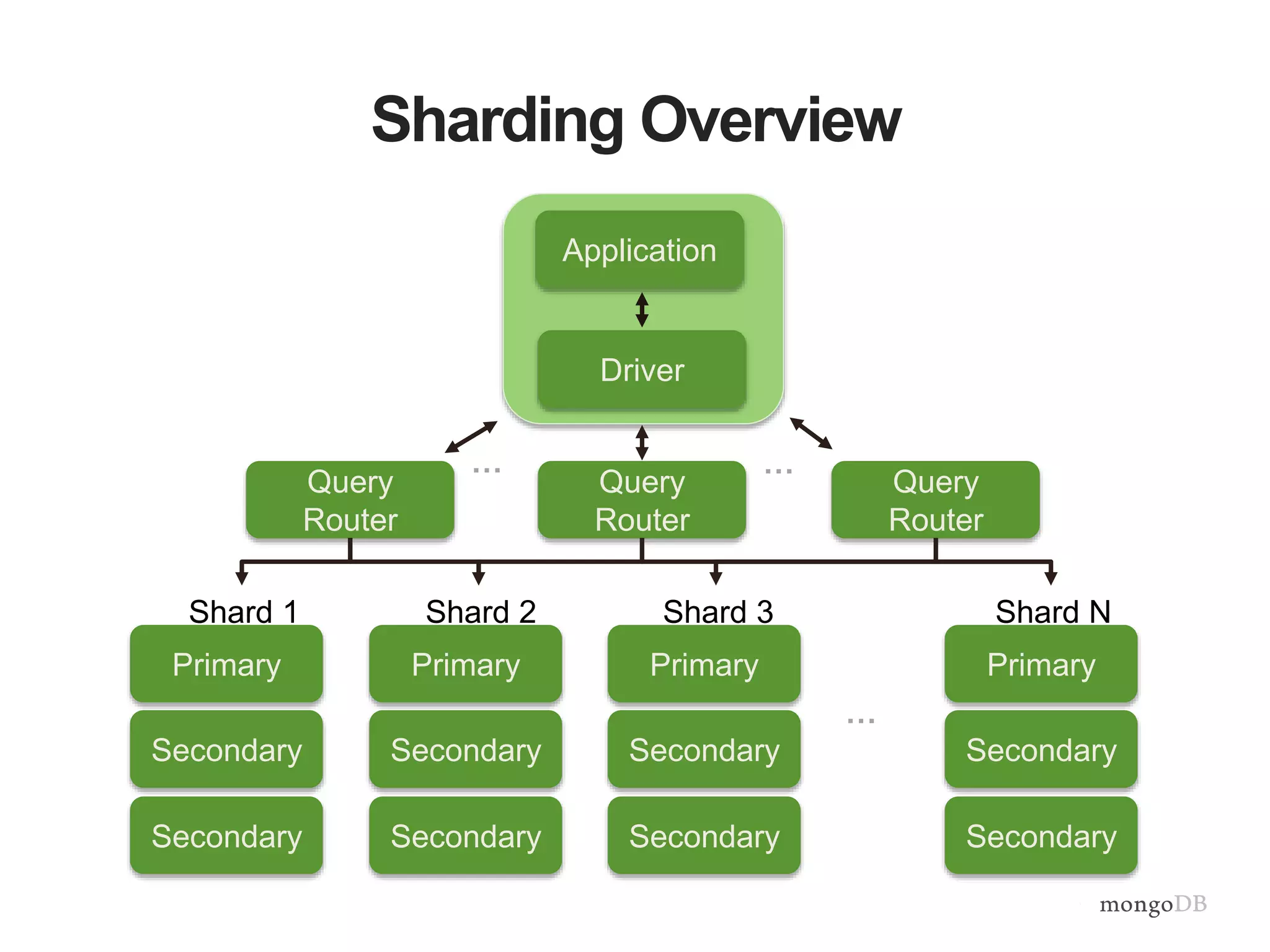
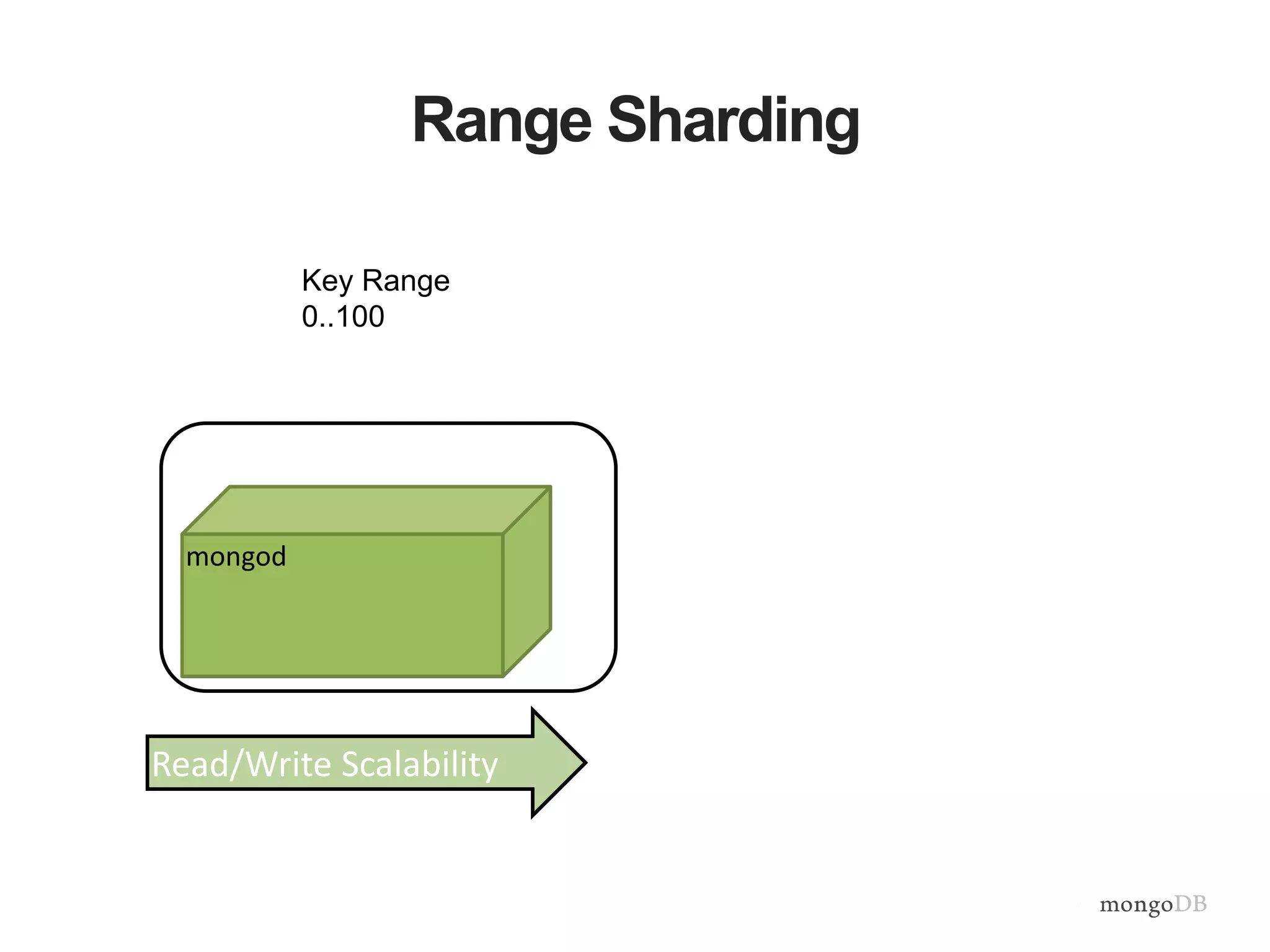
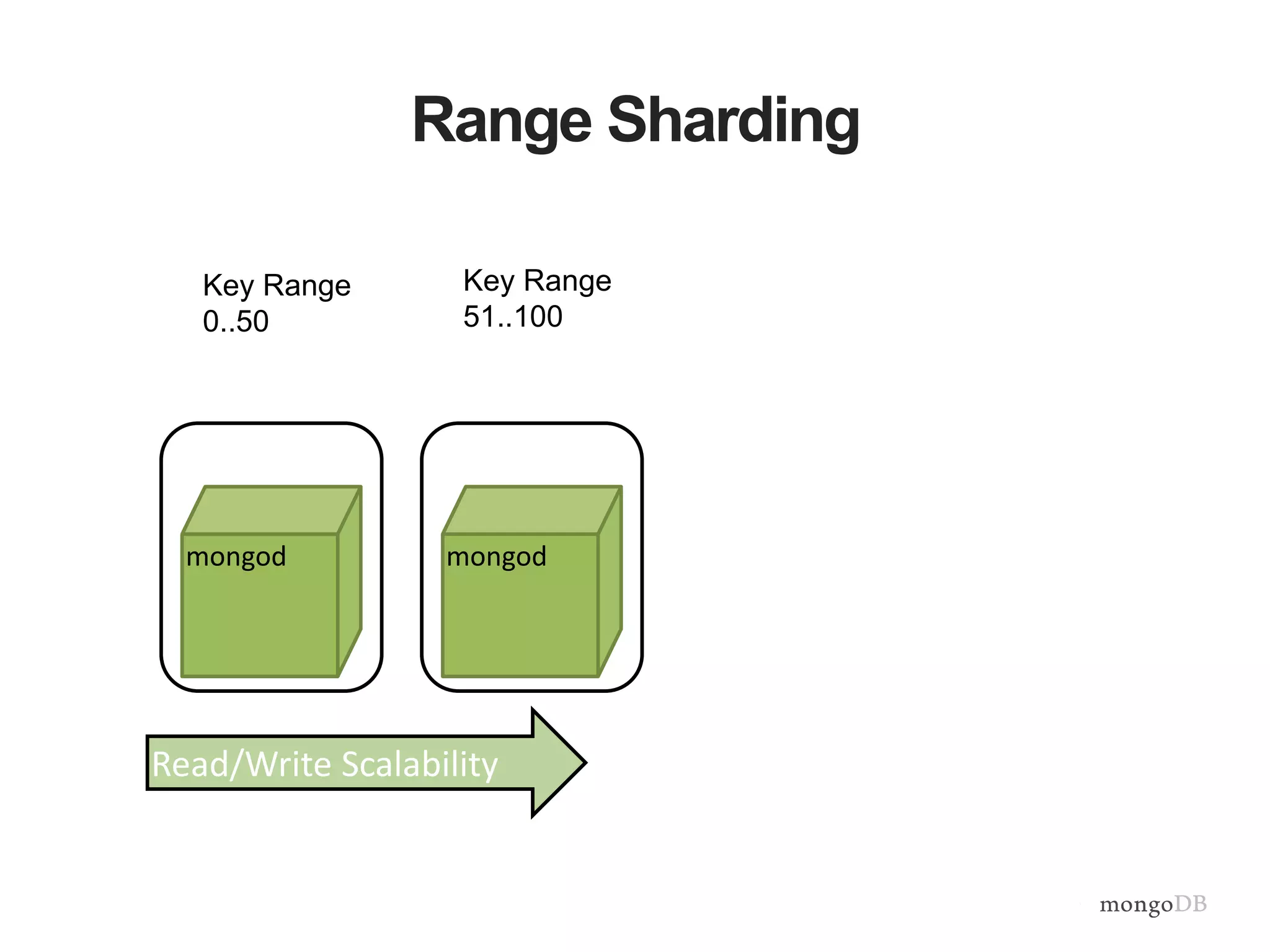
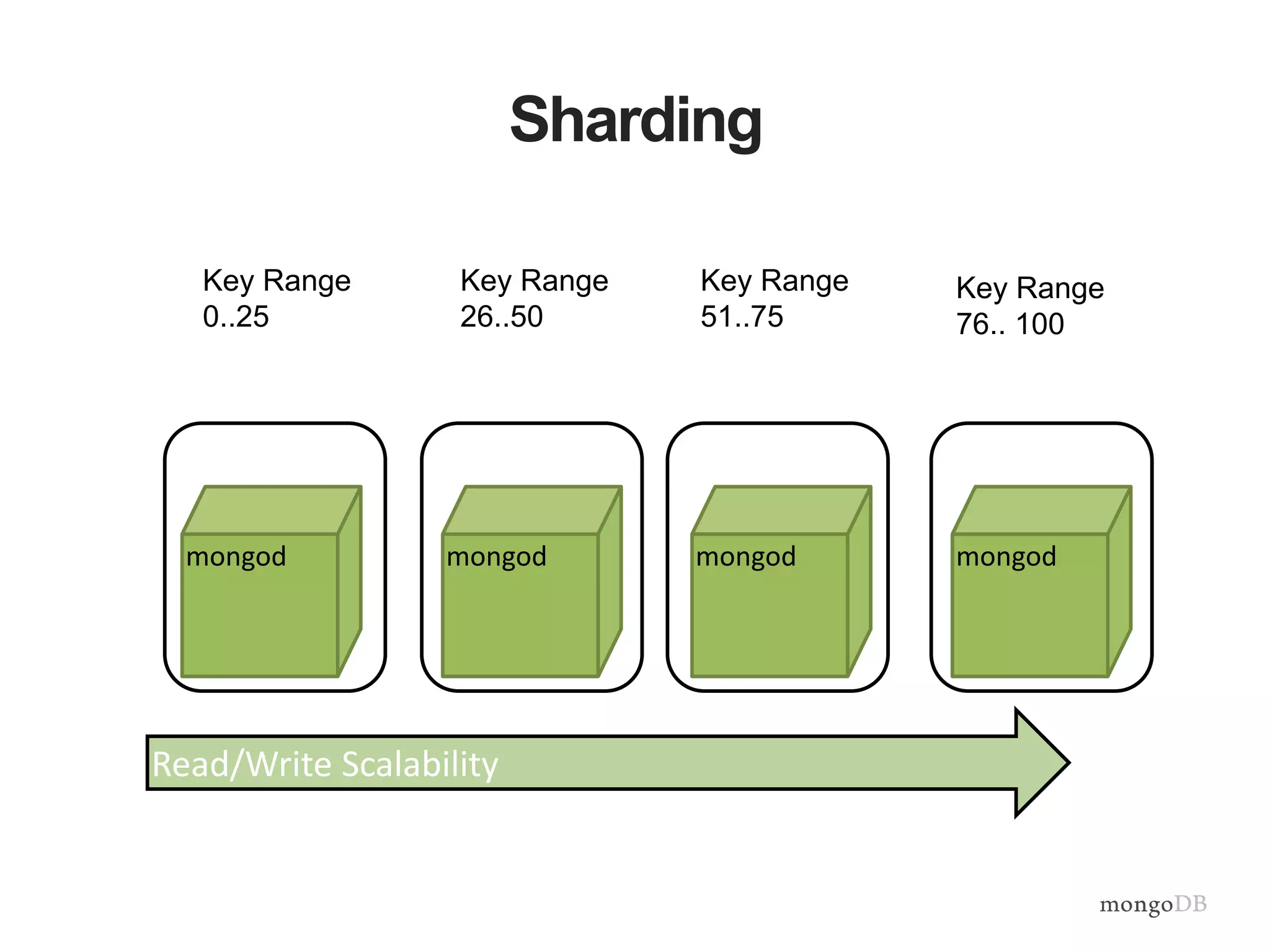
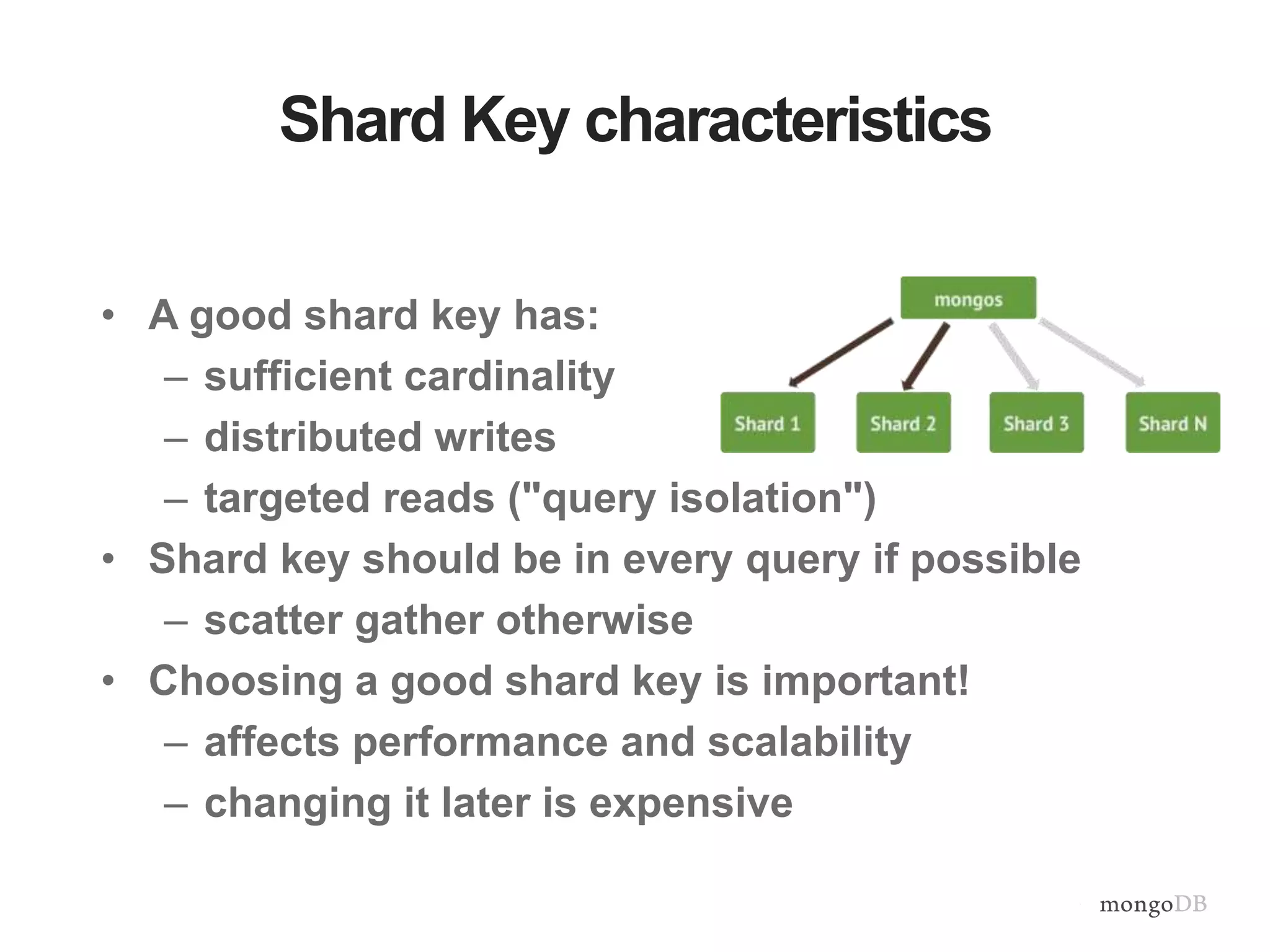
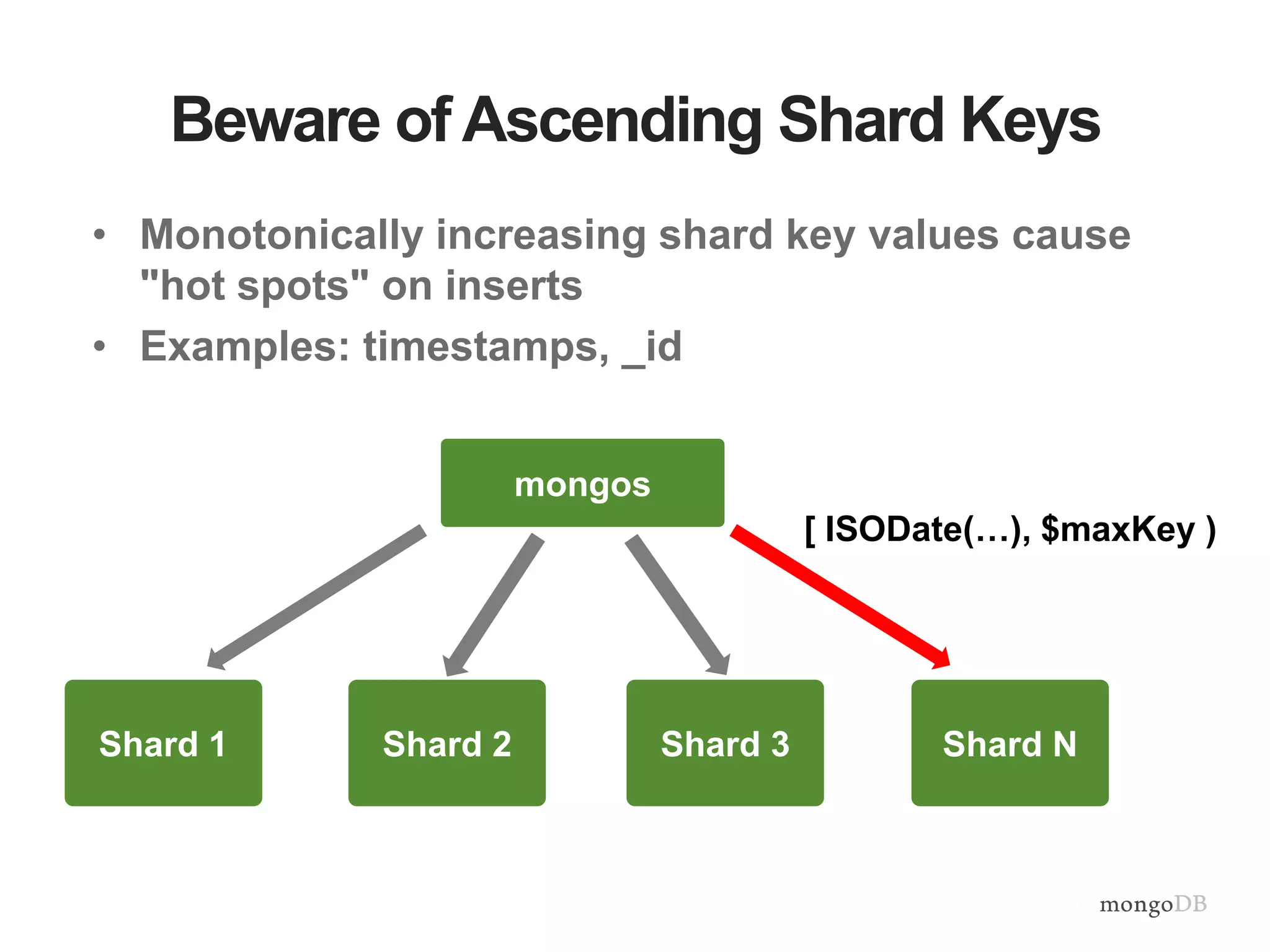
Vertical and horizontal scaling details, including factors affecting scaling, sharding overview, and shard key characteristics.
Strategies for scaling operations teams effectively, showcasing the role of MongoDB Management Service in simplifying management tasks.