Downloaded 34 times



![5 Evolution of a Profile (n+1) { "_id" : ObjectId("553e7dca588ac9ef066428e0"), "firstName" : "John", "lastName" : "Doe", "address" : "229 W. 43rd St.", "city" : "New York", "state" : "NY", "zipCode" : "10036", "age" : 30, "email" : "john.doe@mongodb.com", "twitterHandle" : "johndoe", "gender" : "male", "interests" : [ "electronics", "basketball", "weightlifting", "ultimate frisbee", "traveling", "technology" ], "visitedCounts" : { "watches" : 3, "shirts" : 1, "sunglasses" : 1, "bags" : 2 }, "purchases" : [ { "id" : 1, "desc" : "Power Oxford Dress Shoe", "category" : "Mens shoes" }, { "id" : 2, "desc" : "Striped Sportshirt", "category" : "Mens shirts" } ], "persona" : "shoe-fanatic” }](https://image.slidesharecdn.com/2015-mongodbandflink-spark-151026142710-lva1-app6891/75/MongoDB-Days-Germany-Data-Processing-with-MongoDB-5-2048.jpg)
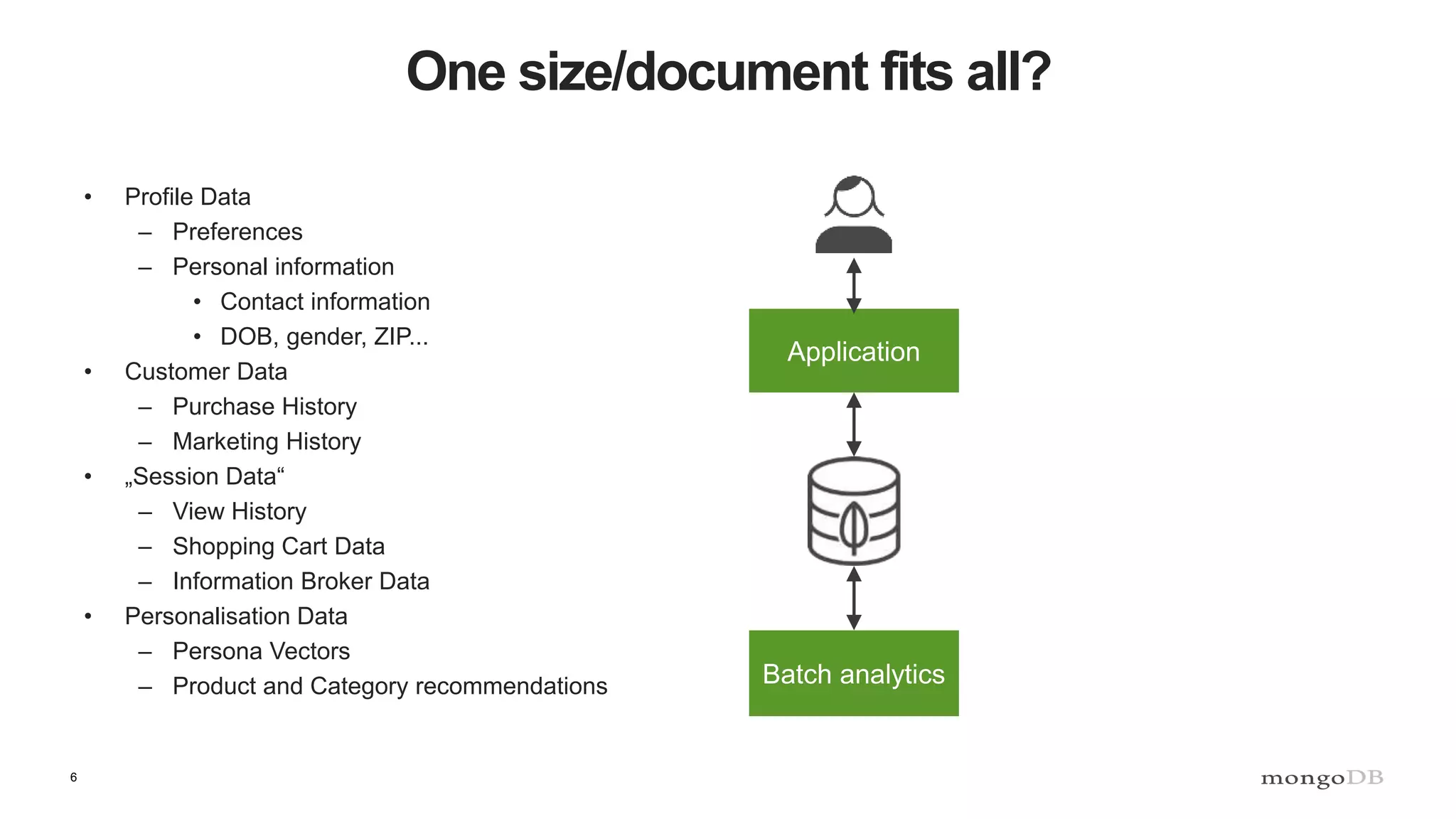
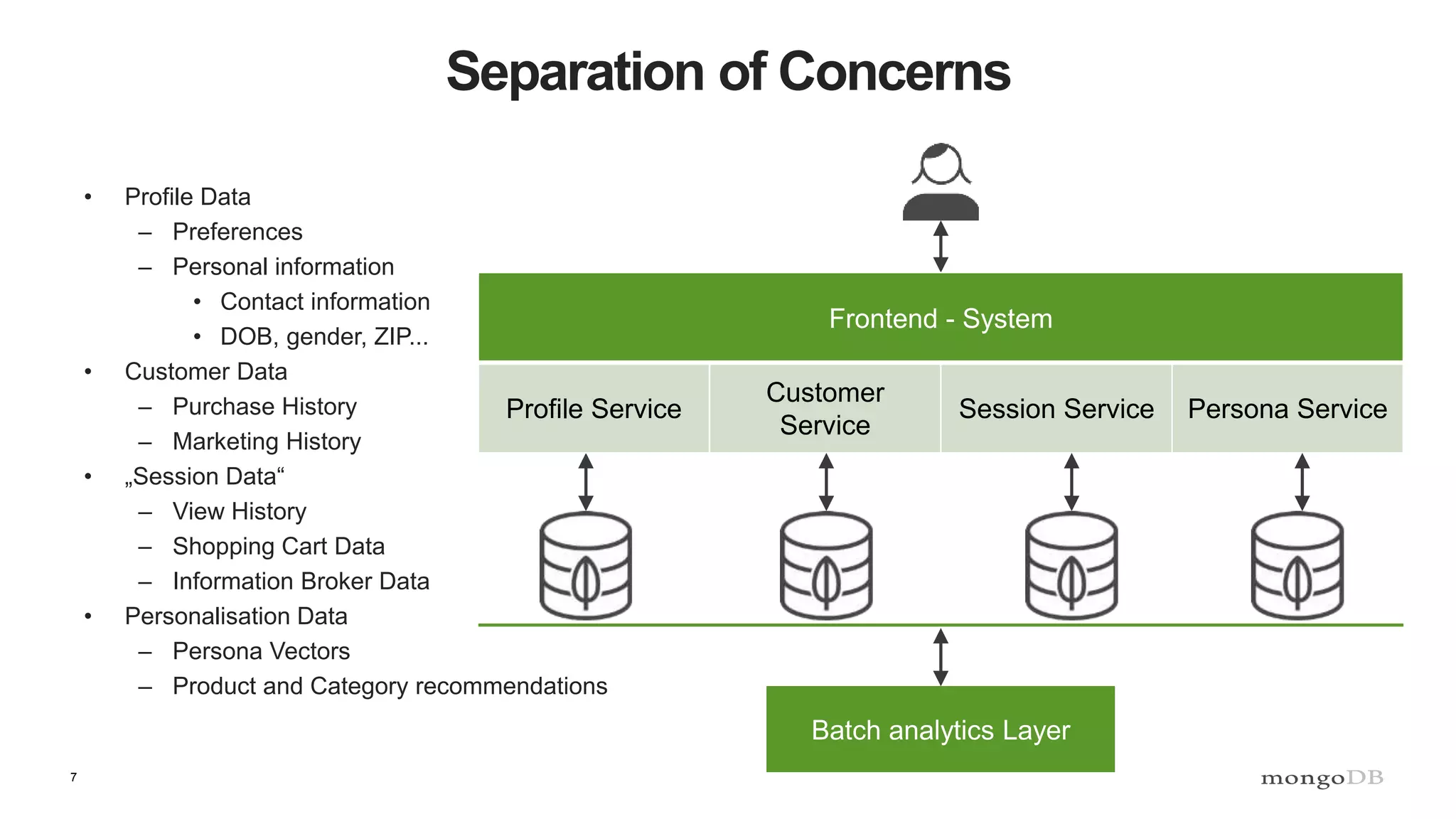



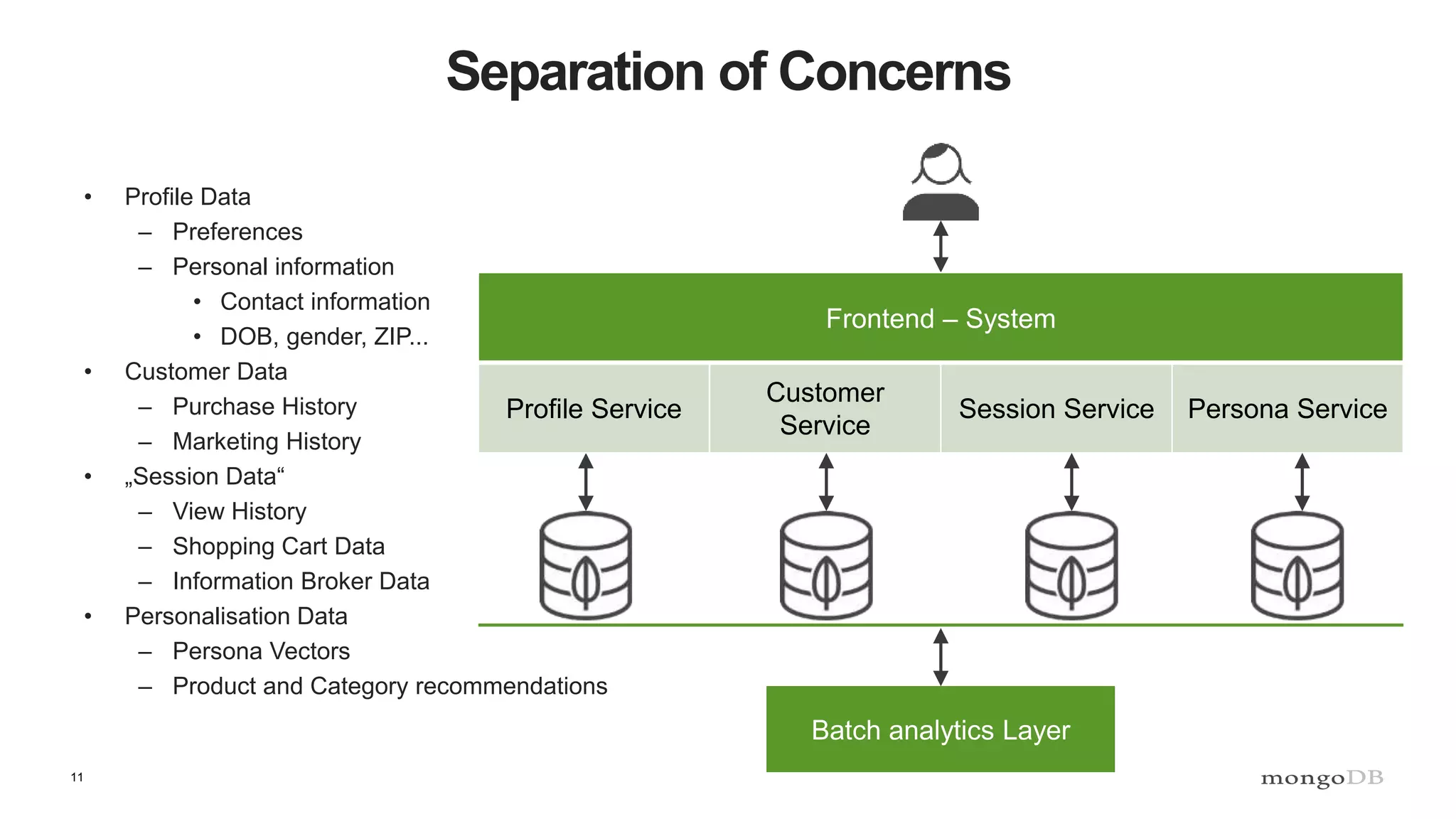
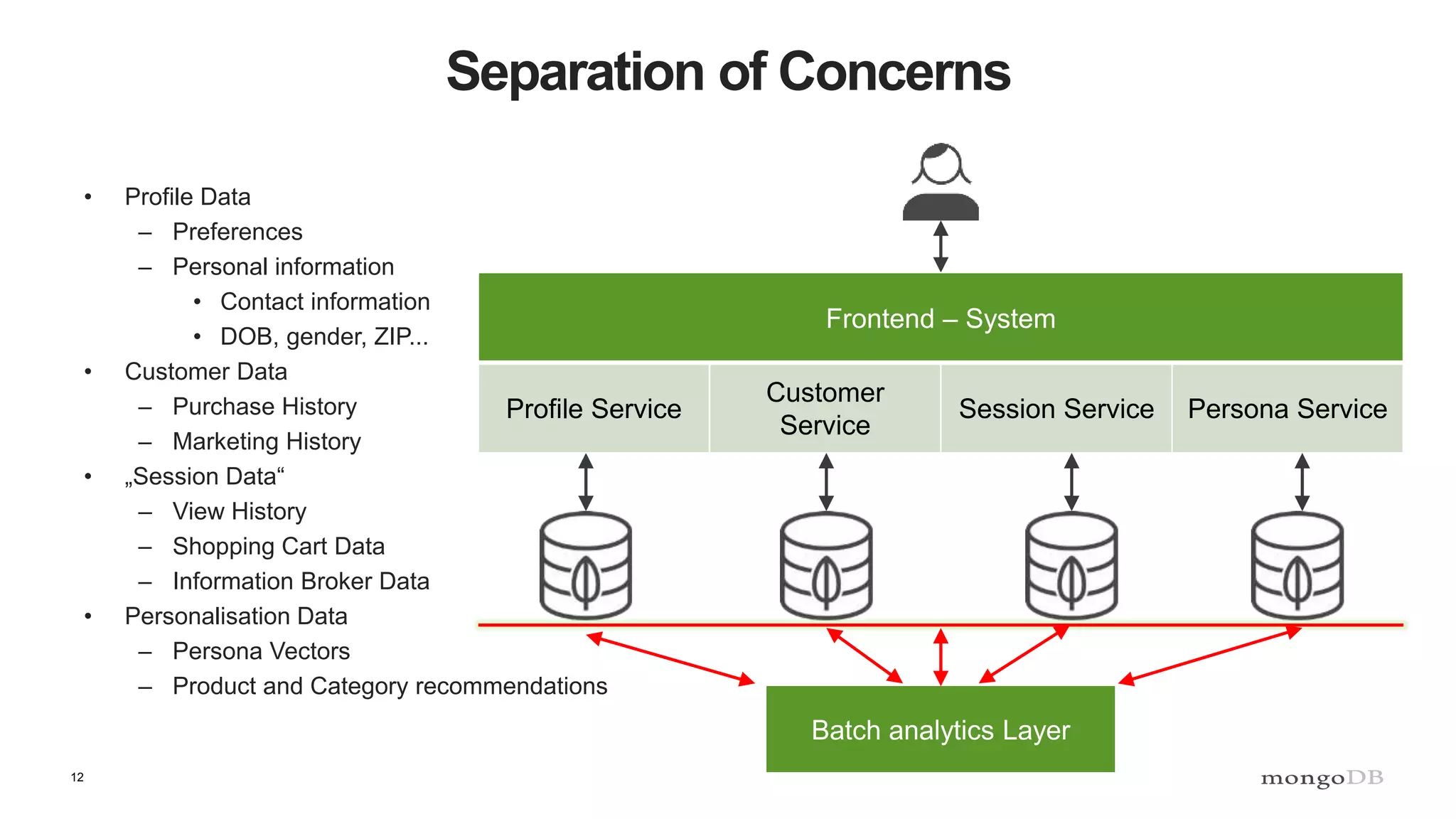
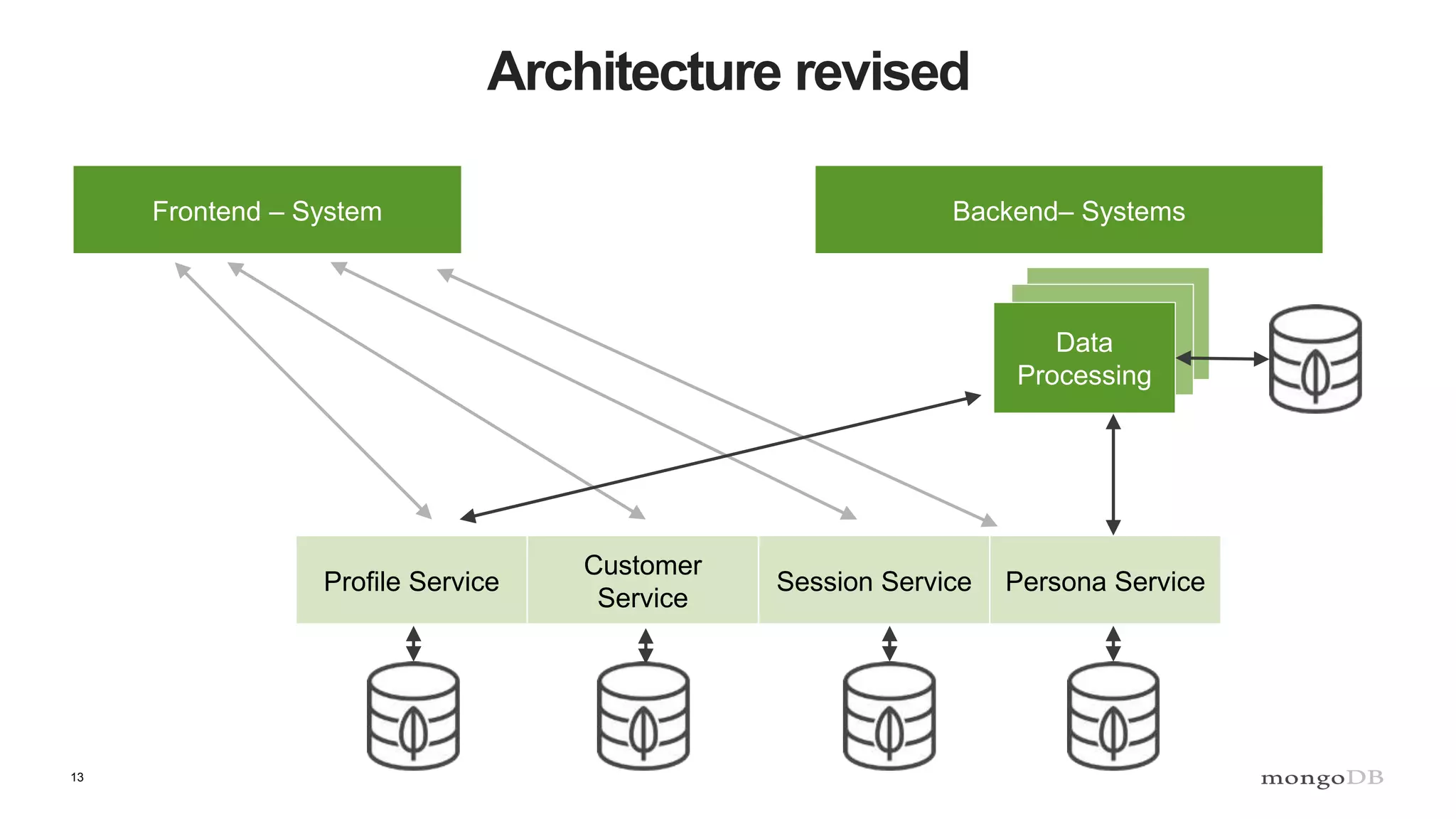





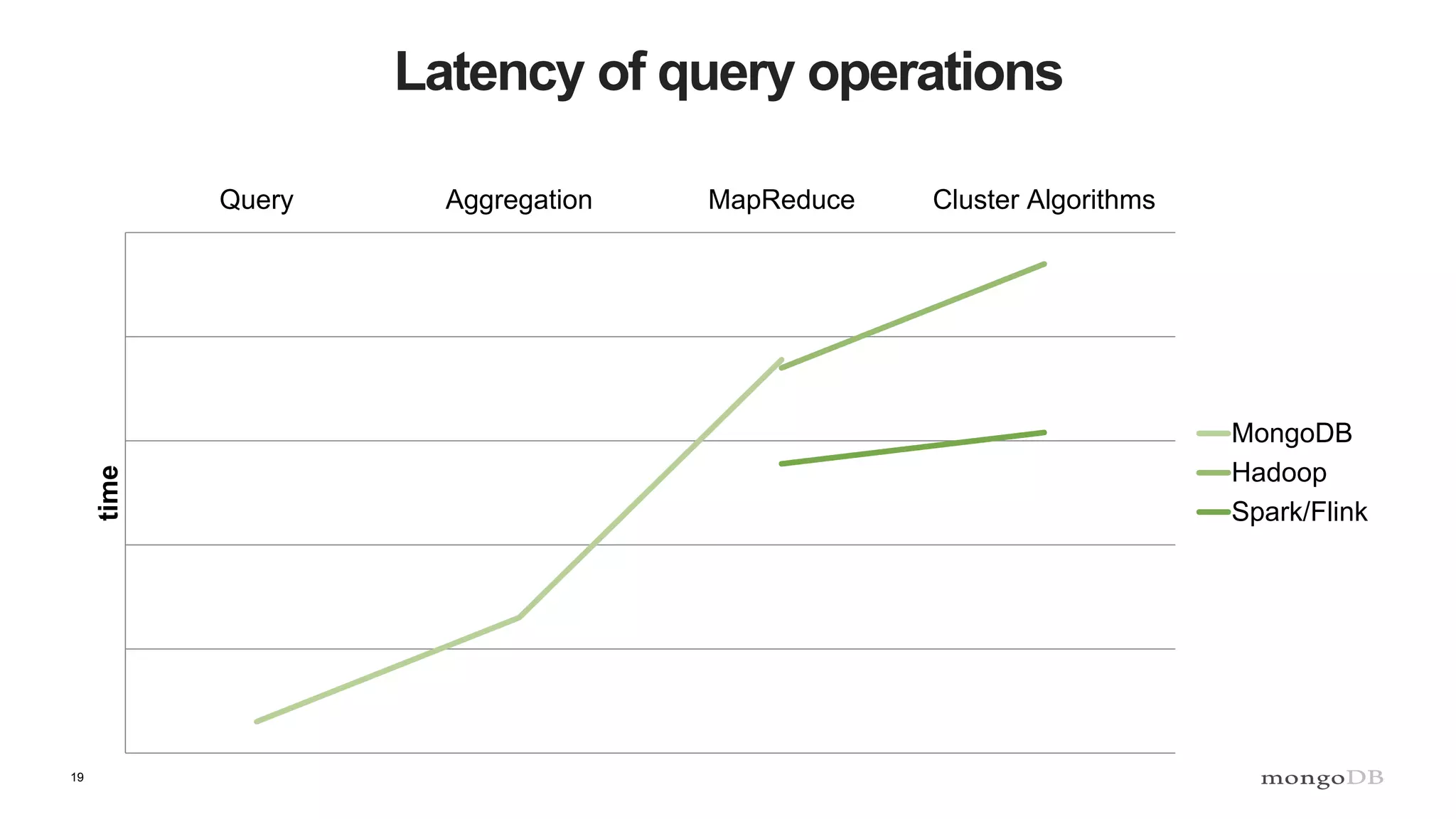


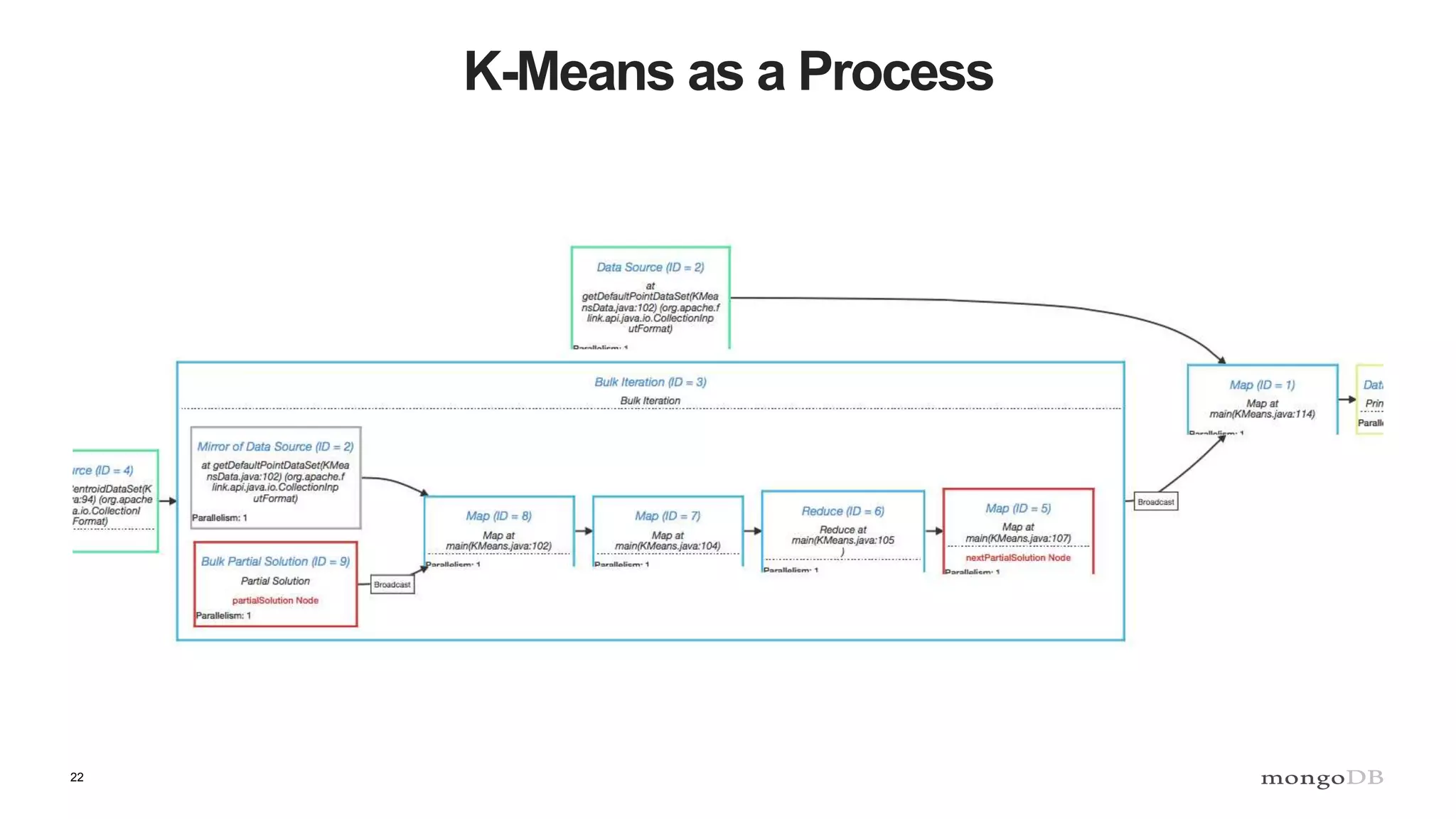
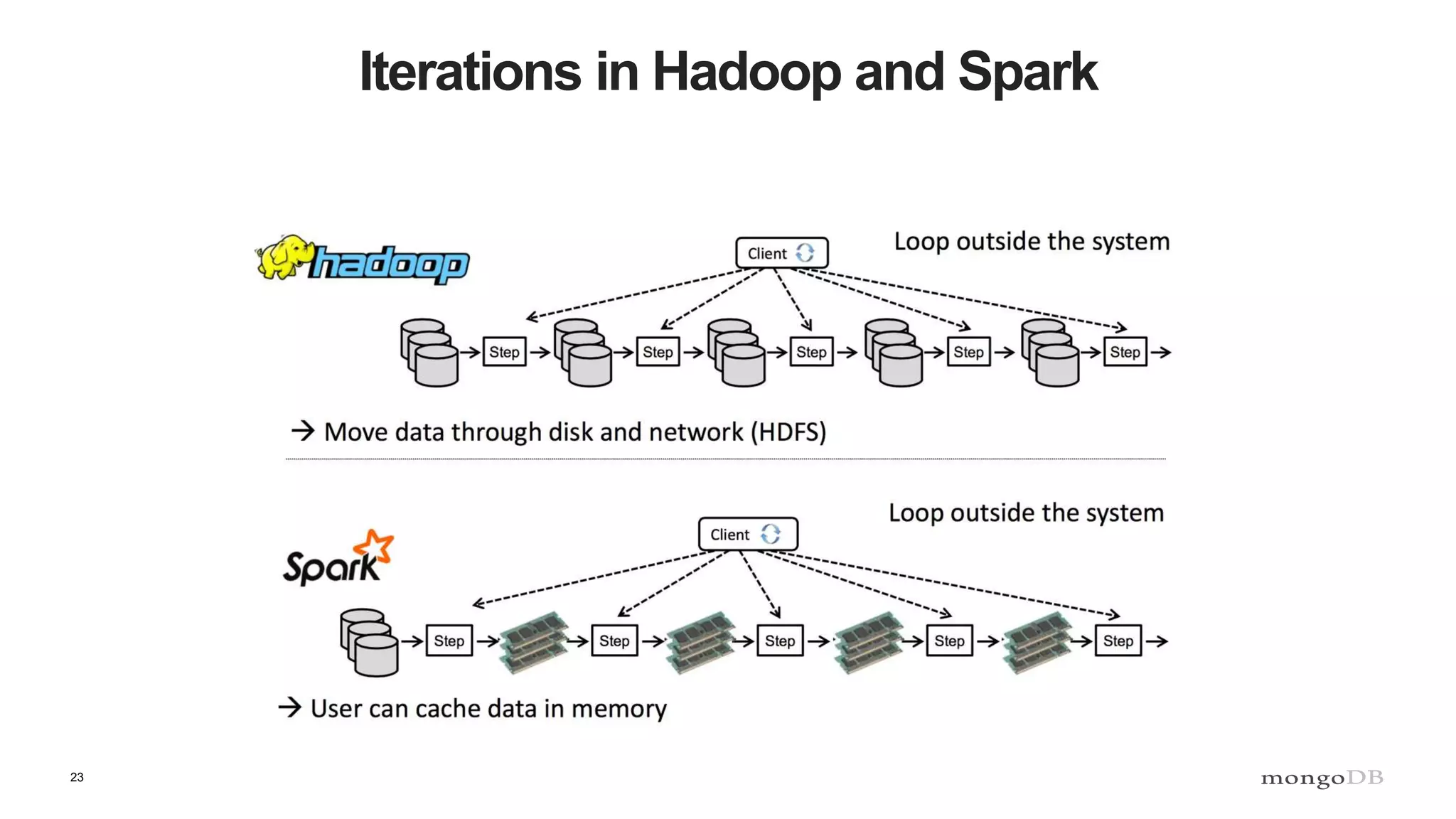
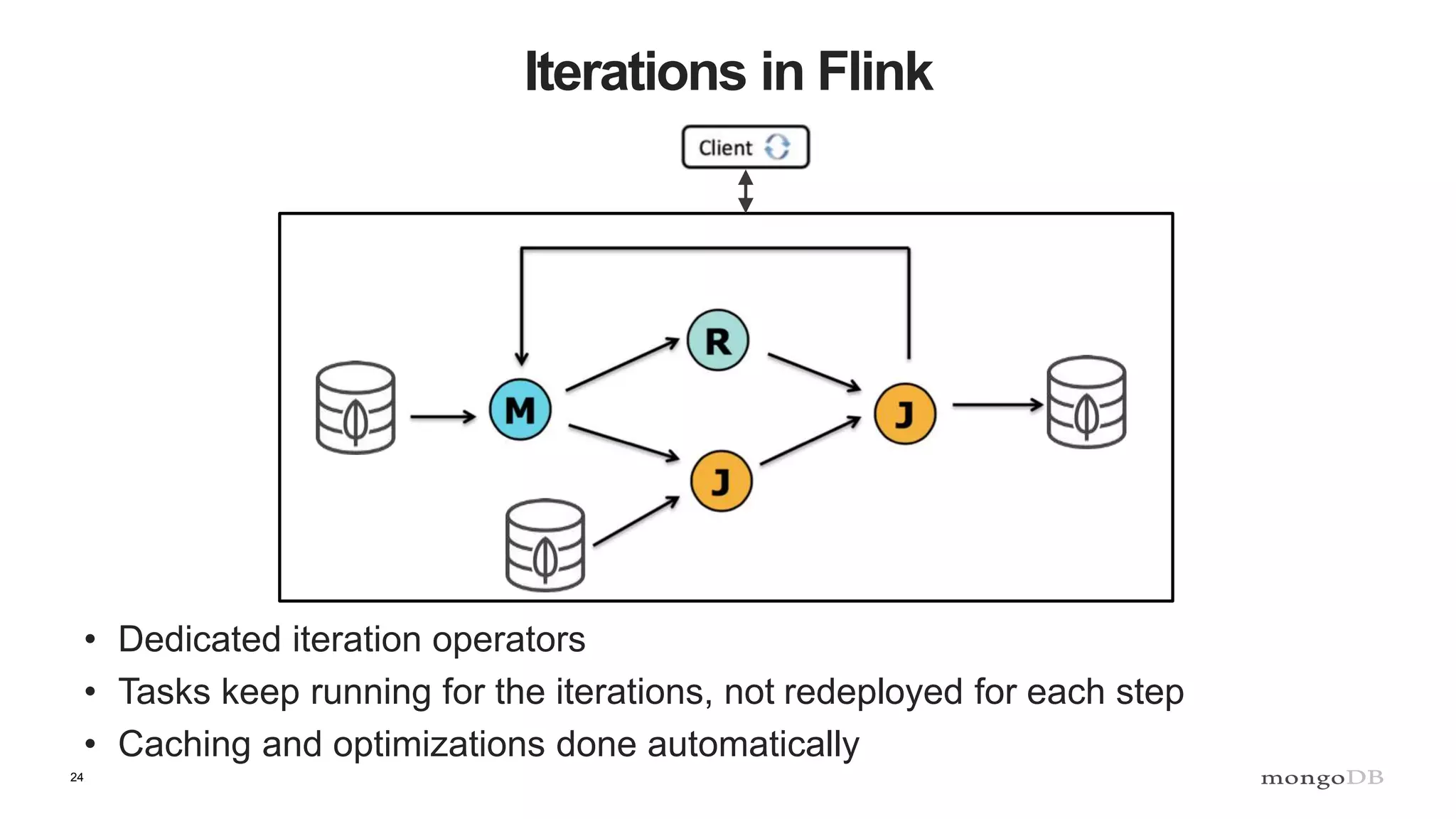




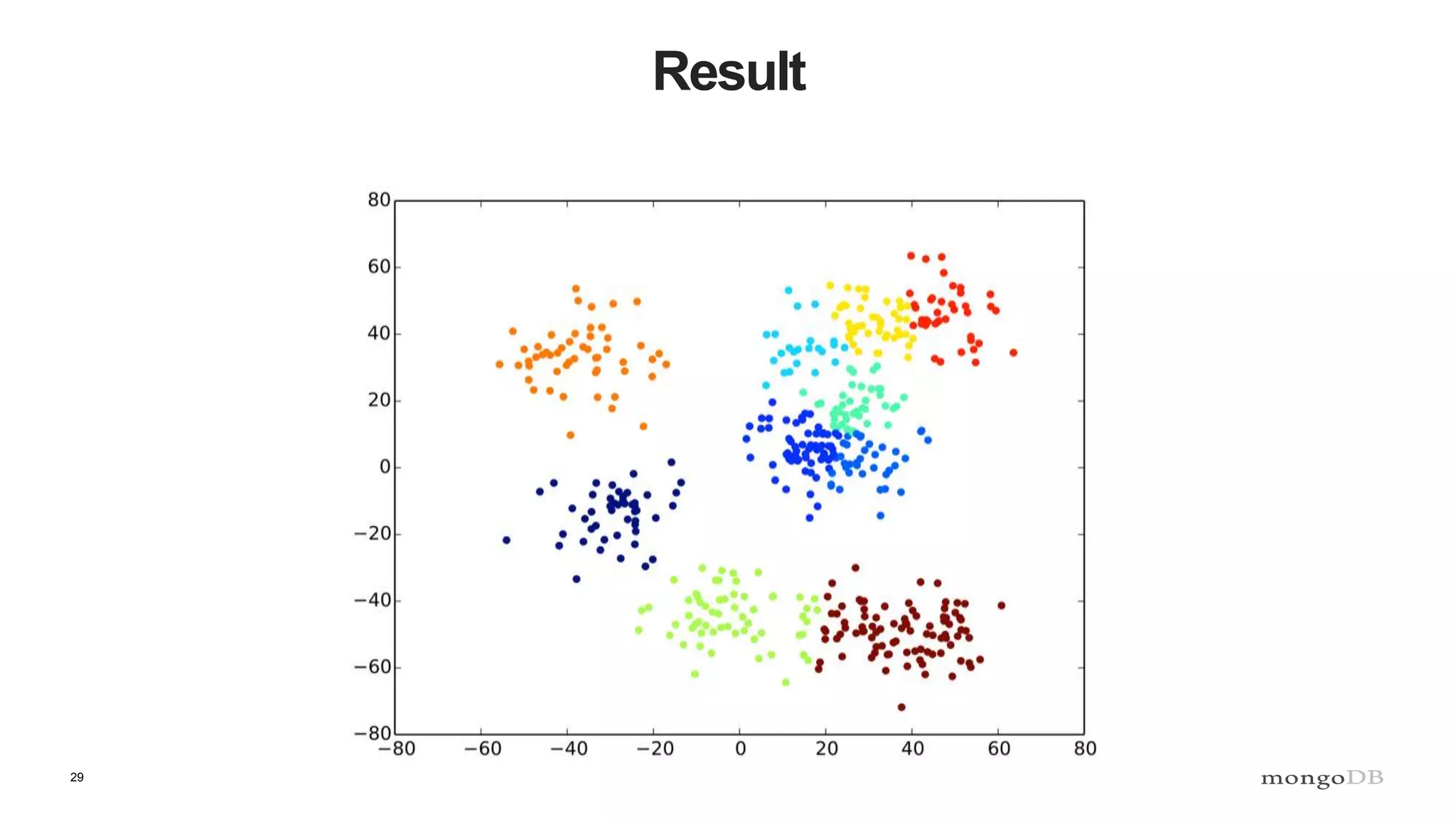




The document discusses data processing using MongoDB and Apache technologies, emphasizing architectural overviews and the role of services in data handling and personalization. It covers the evolution of user profiles, separation of concerns in application architecture, and provides an overview of Hadoop, Spark, and Flink as data processing frameworks. The document also includes guidance for developers on managing data and highlights the importance of exploring new tools and community engagement.