Downloaded 14 times
![INTERNATIONAL JOURNAL OF TECHNOLOGY AND COMPUTING (IJTC) ISSN-2455-099X, Volume 2, Issue 10 October 2016 IJTC201610001 www. ijtc.org 489 Predicting Students’ Performance Using Classification Techniques in Data Mining Mukesh Kumar1 , Prof (Dr.) A. J. Singh 1 (PhD Scholar, CS Department, HPU-Shimla HP, mukesh.kumarphd2014@gmail.com) 2 (Professor, CS Department, HPU-Shimla HP, aj_singh@yahoo.uk.in) Abstract: Role of education is very critical for the development of any country. So it is the responsibility of each and every person to do something for the betterment of education. Taking this fact into consideration we start working on the education system. Education system ranging from basic to higher education. Now a day education system generates a lots of data related to student. If we cannot analyze that data properly then that data is useless. With the help of data mining techniques we can find the hidden information from the data collected for the different educational setting. With the help of that information we can review our educational process or make improvement in our education system. Here in this article we are considering a case of an engineering college student and try to predict the final result in advance. The result of the prediction provides timely help to those students who are on risk of failure in the final examination. There are different techniques of data mining are available and we are using J48, RandomForest, and ADTree to predict the performance of the student in their final examination. On the basis of this predication we can make a decision whether the student will be promoted to next year or not. We the help of the result we can improve the performance of the student who are on risk of fail or promoted. After the declaration of the final result of the student, result is fed into the system and hence the result will analysed for the next semester. The comparative result shows that, prediction help in the improvement of overall result of the weaker students. Keywords- Data Mining, EDM, Decision Tree Algorithm, J48, RandomForest, ADTree. I. INTRODUCTION Data mining is a one of the most important field to study. Data mining concepts, techniques and algorithms are applied into different fields like education, medicine, business, retail management, hospital and hospitality industries etc. With the help of data mining techniques we can predict the future of any business or make improvement in it. We are learning about different data mining techniques in our study like association rule mining, clustering, classification etc. There are two types of data mining techniques are available like supervised and unsupervised learning. In supervised learning we are making model first and then apply algorithm on that data set [2]. While in unsupervised learning we are applying algorithm first and then make model for analysis. Now we are just discussing about the concept of educational data mining. As we already mentioned that we are choosing educational field because education is one of the most important facture for the development of the nation. Data mining is used to find hidden information for the data set. So by analysing the educational data we want to find some important information which is helpful for the further improvement in education. Which data mining algorithms are applied on dataset is depend upon the types of dataset and what you want to find form it. We have studied different algorithm which are applied on the different data set. Data mining algorithm like neural network, Naïve Bayes, K- Nearest neighbour, Decision tree, classification and clustering are applied on the educational dataset [3]. With the help of data mining techniques we can predict, classify or cluster student according to their performance in their education. Examination marks play most important role in the life of a student. If we can predict the result of the student before examination then we can put some extra effort to improve the performance of that student in their final examination. You can say with the help of predication we can provide timely help to the student who are at risk of education failure. II. PROBLEM RELATED TO THE HIGHER EDUCATION SYSTEM At present most of the institutions or organisation in India are facing the problem of student admission. Most of the engineering college or university are face problem of low admission in engineering stream. There are lot of reason for that like less placement record, less infrastructures; syllabus not updated, less qualified staff, poor teaching methodology. So to increase admission in the college we need to provide these basic needs of the time. Without providing these features no college will sustain in the near future and face the problem of failure [1]. So to remain in the competition with other college they need to provide extra to the student which helps them a lot in their study. Educational data mining is the solution of the entire problem because with the help of educational data mining we can analysis the all the data which are produced by the educational setting. With the help of analysis we can predict the result of the student, dropout of any student, placement of the student, behaviour of the student etc. If any student having a risk of failure and we can predict that risk in advance then we can provide timely help to that student. Education data mining techniques can be applied on any types of educational data. There are lots of data mining techniques which are applied on educational data like classification and clustering algorithm. In this article we can consider the case of an engineering college in which we want to predict the result of the student in their final examination of next semester. For that purpose we can collect the information of the first year student with different attribute like branch, sex, category, father occupation, Mother occupation etc [1]. With the help of data mining we can predict the result of the student in advance and then provide the student timely help who are IJTC.O RG](https://image.slidesharecdn.com/ijtc201610001-predictingstudentsperformanceusingclassificationtechniquesindatamining-s180-181116145903/75/Predicting-students-performance-using-classification-techniques-in-data-mining-1-2048.jpg)
![INTERNATIONAL JOURNAL OF TECHNOLOGY AND COMPUTING (IJTC) ISSN-2455-099X, Volume 2, Issue 10 October 2016 IJTC201610001 www. ijtc.org 490 on the risk of failure. The motive behind this article is to help different educational institutional administrator by creating a model which provide some helps to student and hence they will improve their result in future. We are taking different steps to achieve these motives in mind are listed below: 1. Choose the different source by which you can collect the information related to the student with selected attributes 2. By collecting these data select the best attribute which helps for the prediction of the student result, their behaviour and academic achievement. 3. Select the best data mining algorithm for your dataset which give the result with great accuracy. We are applying different classification data mining algorithm for our analysis. 4. At the end, validate the presented model for different student of engineering institution and university of India. III. DIFFERENT SOFTWRAES AVAILABLE FOR THE DATA MINING ANALYSIS At present scenario, data is one of the most important in today’s world. Because by analysing that data we can find some information which will be helpful in future. We have different types of data mining software for analysis. Every organisation deals with different types of data in real life like data related to education, business, sales, marketing, hospital, hospitality etc. Software’s has their own features and properties and it depend on the data that which software is suitable for their analysis [6]. Here we present ten most important tools used for the data analysis in tabular form below: Table 1: List of different software available for the purpose of data mining analysis S.No Software Language used Developed State 1 RapidMiner Java Technical University of Dortmund 2 SAS Data Mining C North Carolina State University 3 WEKA Java University of Waikato, New Zealand 4 R-Software C, Fortran, R University of Auckland, New Zealand 5 Orange Python University of Ljubljana 6 KNIME Java University of Konstanz 7 NLTK Python University of Pennsylvania 8 DataMelt Jython, Groovy jWork.ORG community 9 Pentaho Java Hitachi Data Systems 10 Tanagra DELPHI 6 Lumière University Lyon, France After reading different research paper about educational data mining we find that RapidMiner and WEKA are the mostly used software for the analysis purpose. So form the above discussion we are taken WEKA software tool for our analysis purpose. WEKA is an Open source software and easily available for the user under GNU public licence. We can also implement our own algorithm on this software. Most of the data mining algorithms are available in WEKA software. WEKA is a complete package of different data mining or machine learning algorithm. It support classification, clustering, regression, association rule and feature selection algorithm. It also able to shows you various relationships between data sets, cluster, visualization, predictive modelling and association rule algorithms. IV. CLASSIFICATION ALGORITHM TAKEN INTO CONSIDERATION FOR ANALYSIS We have different types of data mining algorithms are available to make an analysis of our data like clustering, classification, association rule mining. But which data mining algorithm is suitable for your data is depend upon what types of information your want to take and what types of data set you have in your hand. Before selecting any algorithm make sure that what types of information your want to take from the dataset [7]. Every data mining model is created with the help of a specific algorithm. We can solve any data mining problem with best possible way by using more than one algorithm. In this article we want to make a prediction related to the final result of the student in the coming semester. You will be the successful at data mining field even if you are not very much familiar with the inner working of the each algorithm. But it is important to get the full understanding of the general features of the each algorithms and their suitability with different dataset. Data mining function may be off two types supervised and unsupervised. Here according to our dataset fall into the categories of supervised learning. Under supervised learning we want to apply classification function. Because we want to predict the result of the student according to the predefined classes [4]. There are lots of algorithms fall into the categories of classification like Decision tree, Naive Bayes, Generalized Linear Models (GLM), Support Vector Machine (SVM) etc. In this article we want to apply Decision tree algorithms because it extracts predictive information in human readable and easy to understandable form. The rules generated are in the form of if-else expressions and hence they leads to the prediction. There are lot of Classification algorithm are available for the analysis but we are applying only few of them for the IJTC.O RG](https://image.slidesharecdn.com/ijtc201610001-predictingstudentsperformanceusingclassificationtechniquesindatamining-s180-181116145903/75/Predicting-students-performance-using-classification-techniques-in-data-mining-2-2048.jpg)
![INTERNATIONAL JOURNAL OF TECHNOLOGY AND COMPUTING (IJTC) ISSN-2455-099X, Volume 2, Issue 10 October 2016 IJTC201610001 www. ijtc.org 491 analysis purpose like, J48, RandomForest REPTree, LADTree and then compare their predictive result. V. DATA COLLECTION AND PROCESSING PHASE For predicting the academic progress of any student in their early stage of higher education is very important. Because early prediction of result always help a students to perform well in the final examination. So for making any prediction related to academic progress of the students we need lots of parameters of students [1]. Prediction model takes lots of parameter of student into consideration like personal, family, psychological and social information for effective prediction in their academics. Student’s educational backgrounds are also taken into consideration while making the prediction [8]. In student’s educational background make contain data like grade, attendance, behaviour, attitude toward study etc. The dataset used for this article was taken from a reputed engineering from under Punjab Technical University Jalandhar. This university produced lots of engineer every year. But the problem is that not all the registered student gets their degree in time due to their backlogs. So in this study we want to analysis the result of student in advance and if the result is not in the favour of student then we can provide timely help to them to improve their result in final examination. For that analysis we need to collect some information from the student and then apply data mining algorithm on that dataset and hence predict the final result of the student in advance. Students have lots of attribute in their study period but we need to collect only those attributes only which are helpful for the prediction of the result. We are selecting only eleven attributes which we think are one of the most important in all the attributes. We was selecting student grade in high school and senior secondary school, gender, family size, family status, parents qualification, parents occupations and previous semester result [1]. Most the information which we collected is from the previous record of the students which are most probably available with the concerned institution. Most of the information was collect from the database of the institution. All the selected attributes with their response variables are listed in the table given below: Table 2: Selected attributes of students considered for the analysis purpose Attributes Description of the attributes Possible Values of the attribute Branch Students Branch {CS, ECE, ME, CE} Gender Student Gender {Male, Female} Grade_HS High School Grade {E – Above 90%, A – 81- 90%, B – 71-80%, C – 61- 70%, D – 51-60%, E – 40- 50%, F - < 40%} Grade_SS Senior { E – Above 90%, A – 81- Secondary Grade 90%, B – 71-80%, C – 61- 70%, D – 51-60%, E – 40- 50%, F - < 40%} Family_Size student’s family size {1, 2, 3, >3} Family_Status Students family status {Joint, Individual} Father_Qual Fathers qualification {no-education, elementary, secondary, UG, PG, Ph.D. NA} Mother_Qual Mother’s Qualification {no-education, elementary, secondary, UG, PG, Ph.D. NA} Father_Occ Father’s Occupation {Service, Business, Agriculture, Retired, NA} Mother_Occ Mother’s Occupation {House-wife (HW), Service, Retired, NA} Result Result in B. Tech Ist Year {Pass, Promoted, Fail} All the attributes selected above are taken into consideration for the purpose of prediction with data mining techniques. At the starting phase we start with twenty attributes but find some attribute irrelevant to predict the result. Due to this reason we just ignore those attributes for the final selection of the dataset for the analysis. VI. IMPLEMENTATION OF DATA MINING MODEL FOR PREDICTION As we already discuss that we will use WEKA tools for our implementation. Because it is open source and maximum classification algorithm are implemented on it. After collecting all the information above put it in SUDENTDATA.csv files. Before loading this file into the WEKA explorer make sure that all the information is correct according to the format of data collection. After loading STUDENTDATA.csv file into explorer, apply different classification algorithms on that data. There is more the sixteen Decision tree algorithm are available for the analysis [2]. In WEKA we are applying J48, RandomForest, REPTree and LADTree for over analysis here. After selecting these algorithms, next step is to select 10-fold cross-validation under “Test options” conditions. There is no separate data set for the testing of the algorithm, so it is necessary to get reasonable idea of accuracy for the generated algorithm. The predictive result provide use information that student will perform or not in the examination. VII. RESULTS AND DISCUSSION We are working on four decision trees for the prediction of final result from the student dataset by four machine learning algorithms: the J48, RandomForest, REPTree and LADTree respectively. These all are the important algorithm for the prediction purpose. IJTC.O RG](https://image.slidesharecdn.com/ijtc201610001-predictingstudentsperformanceusingclassificationtechniquesindatamining-s180-181116145903/75/Predicting-students-performance-using-classification-techniques-in-data-mining-3-2048.jpg)

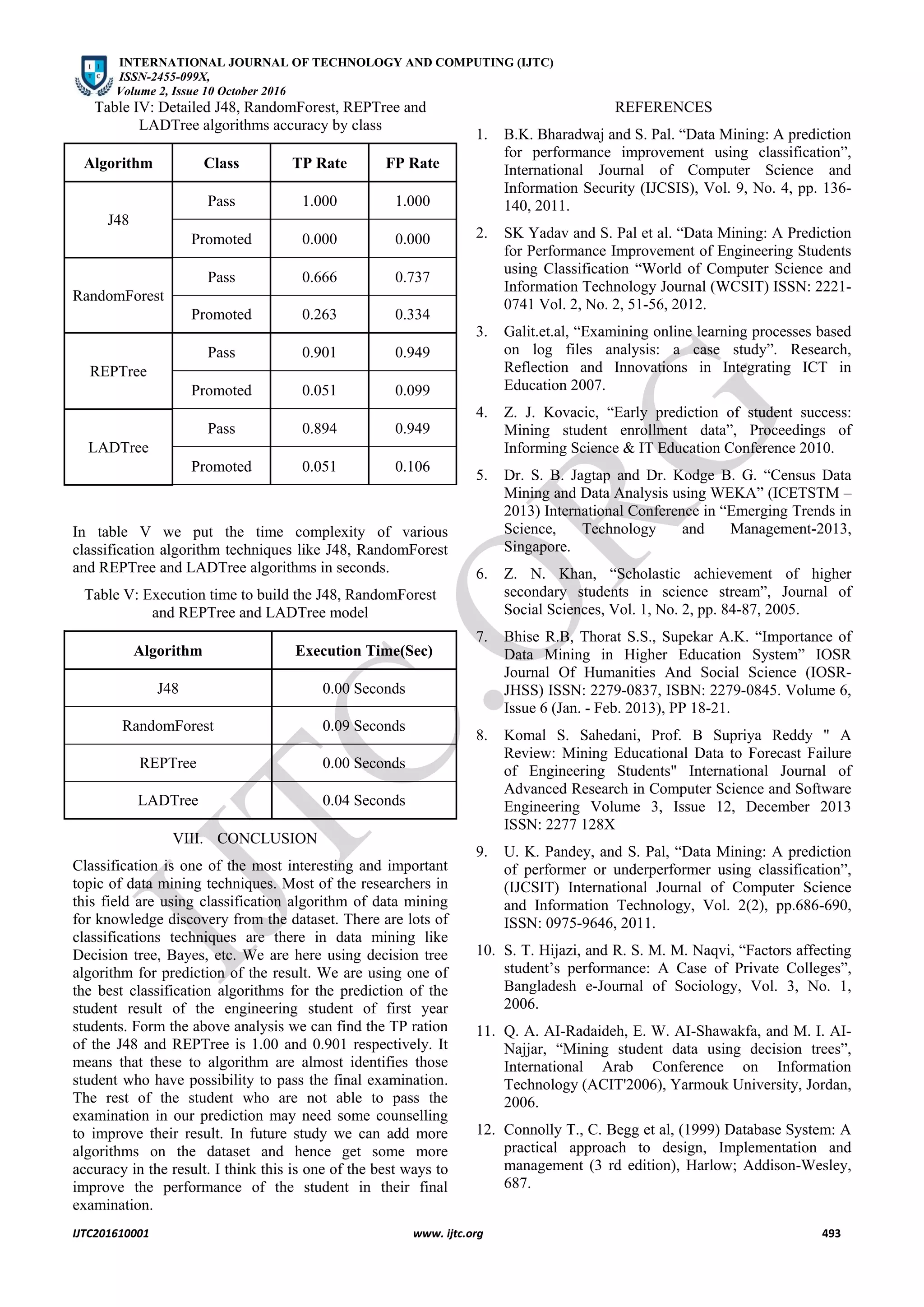


This document discusses the application of data mining techniques, specifically classification algorithms, to predict students' performance in education, focusing on an engineering college scenario. The study evaluates various algorithms such as J48, RandomForest, and ADTree to predict final examination results, ultimately aiding students who are at risk of failure. The findings indicate that classification through data mining can enhance overall student performance and improve educational outcomes.