Downloaded 21 times









![What happens inside a producer? 21 Producer Producer Record Topic [Partition] [Timestamp] Value Serializer Partitioner Topic A Partition 0 Batch 0 Batch 1 Batch 2 Topic B Partition 1 Batch 0 Batch 1 Batch 2 Kafka Broker Send() Retry ? Fail ? Yes No non-retriable exception success metadata Yes [Headers] [Key]](https://image.slidesharecdn.com/confluenton-premcomponentsintroduction-lme-18thnov-211122150559/75/Set-your-Data-in-Motion-with-Confluent-Apache-Kafka-Tech-Talk-Series-LME-17-2048.jpg)





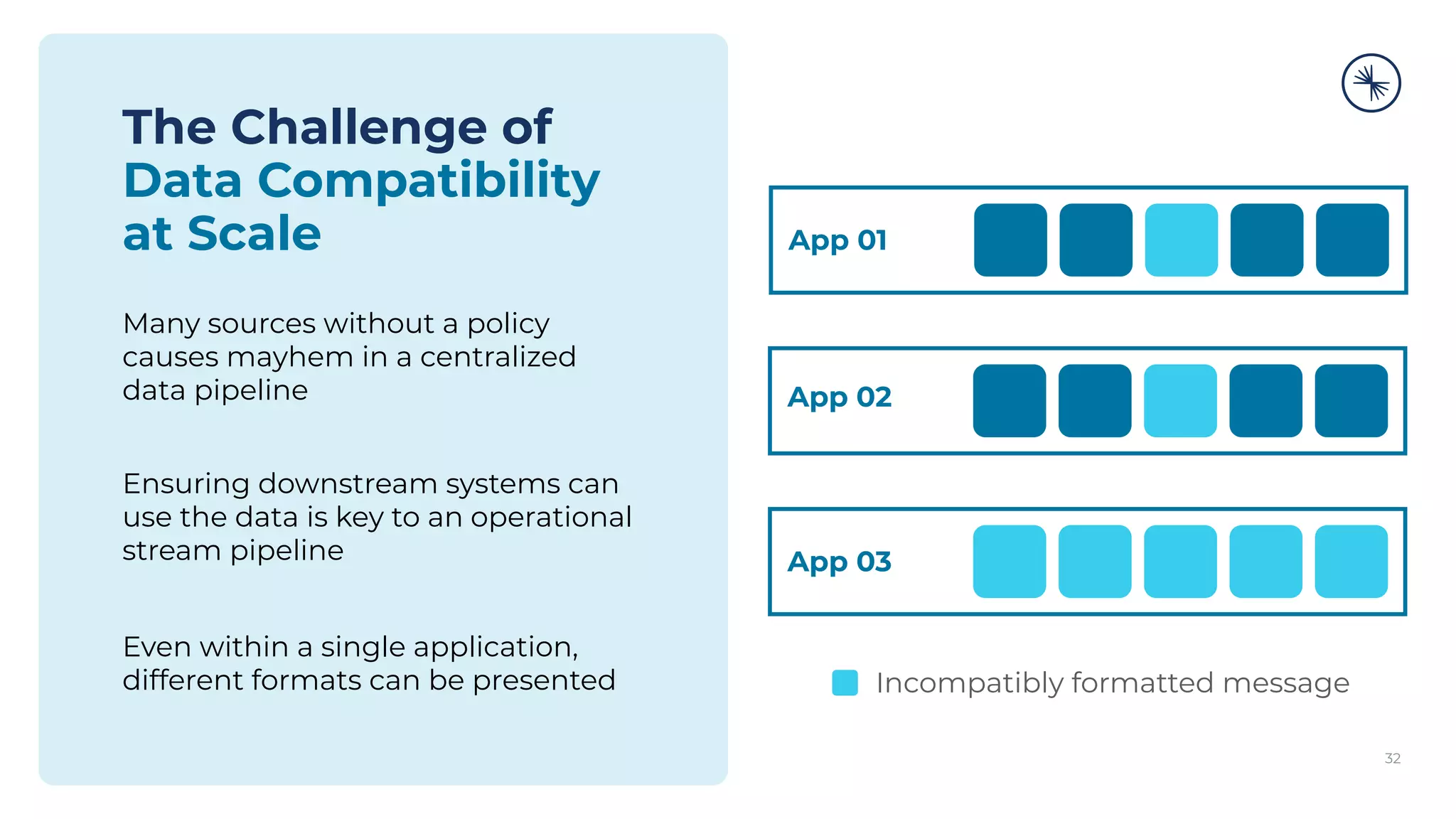
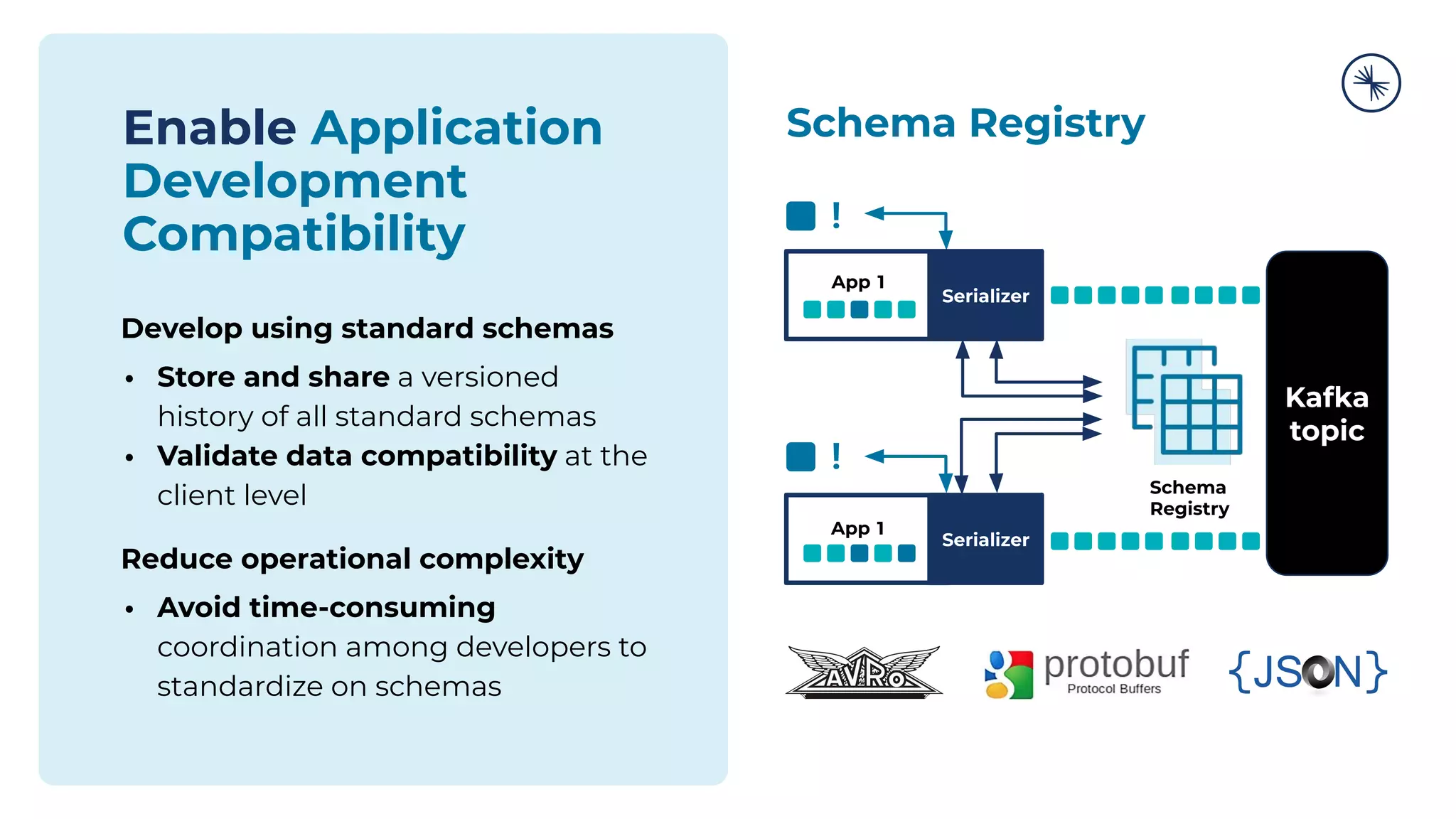


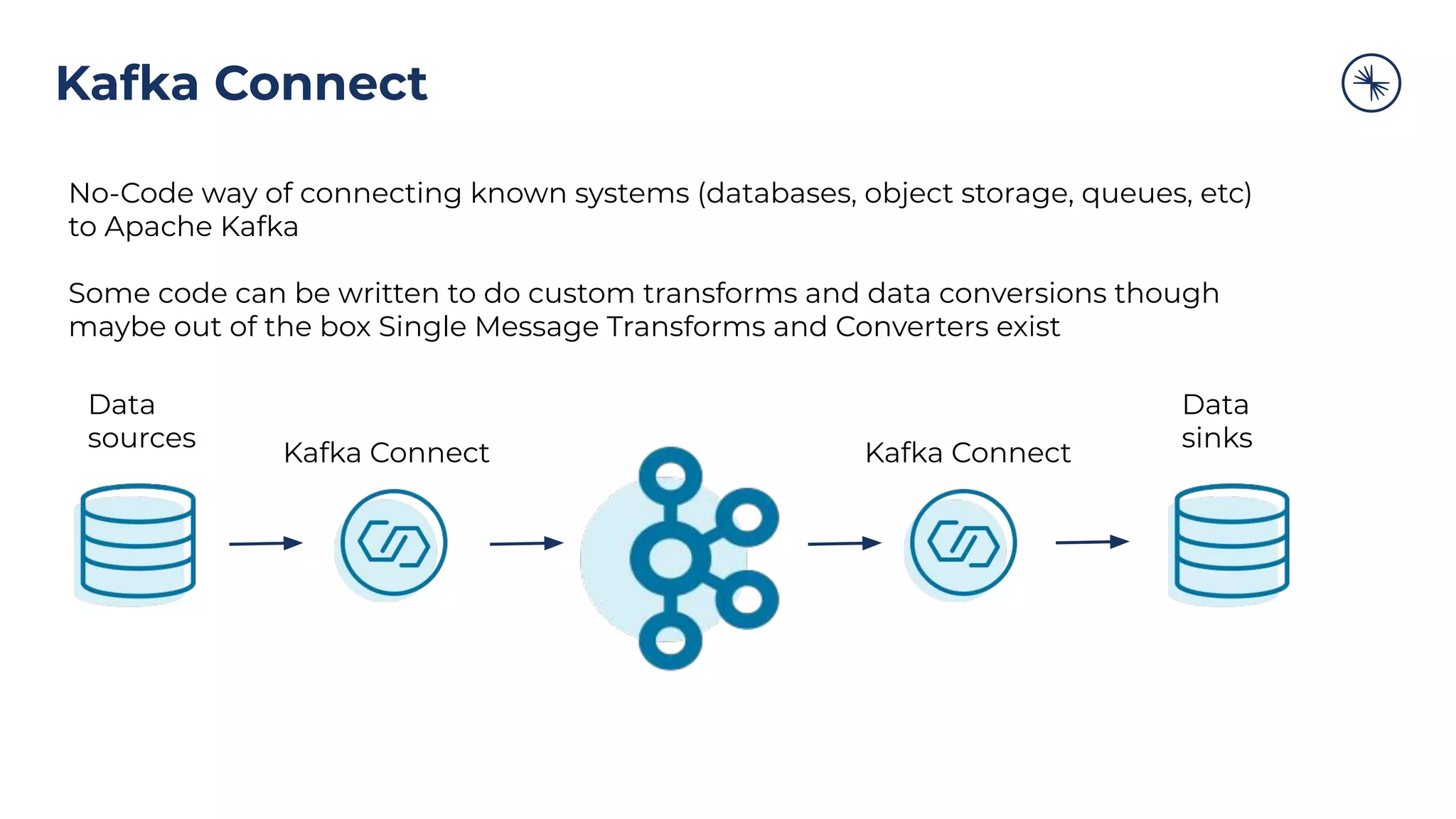
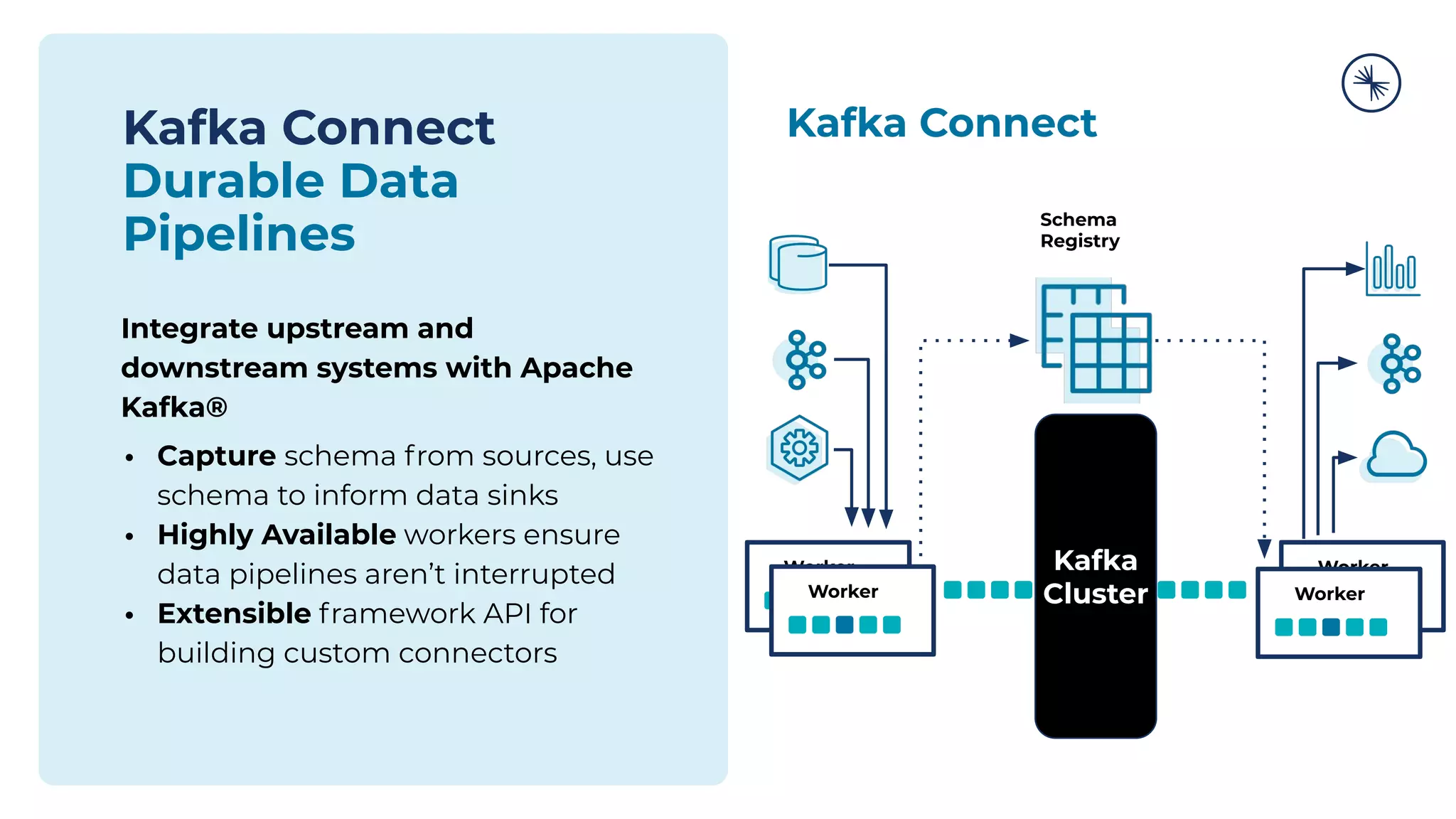



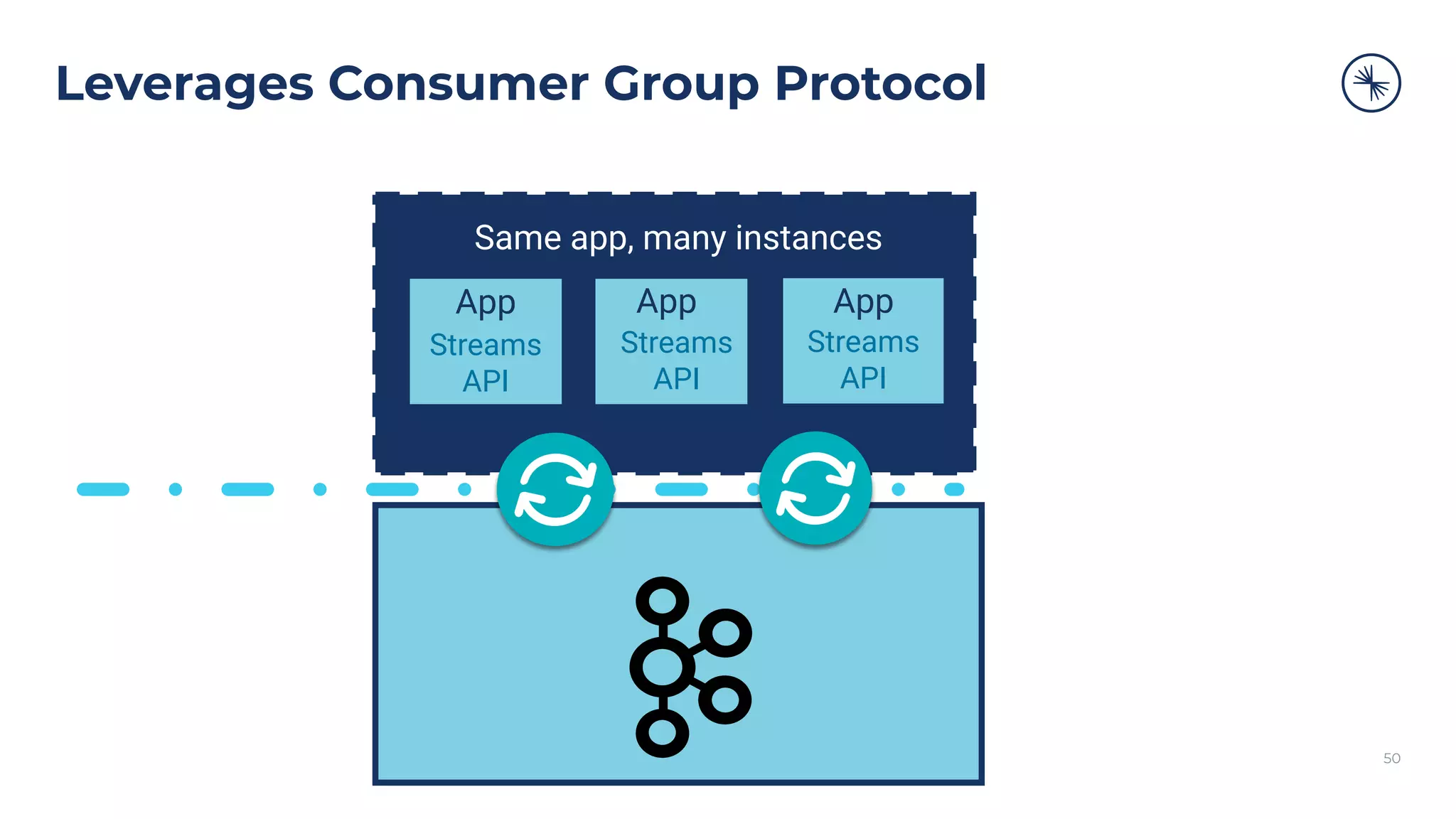

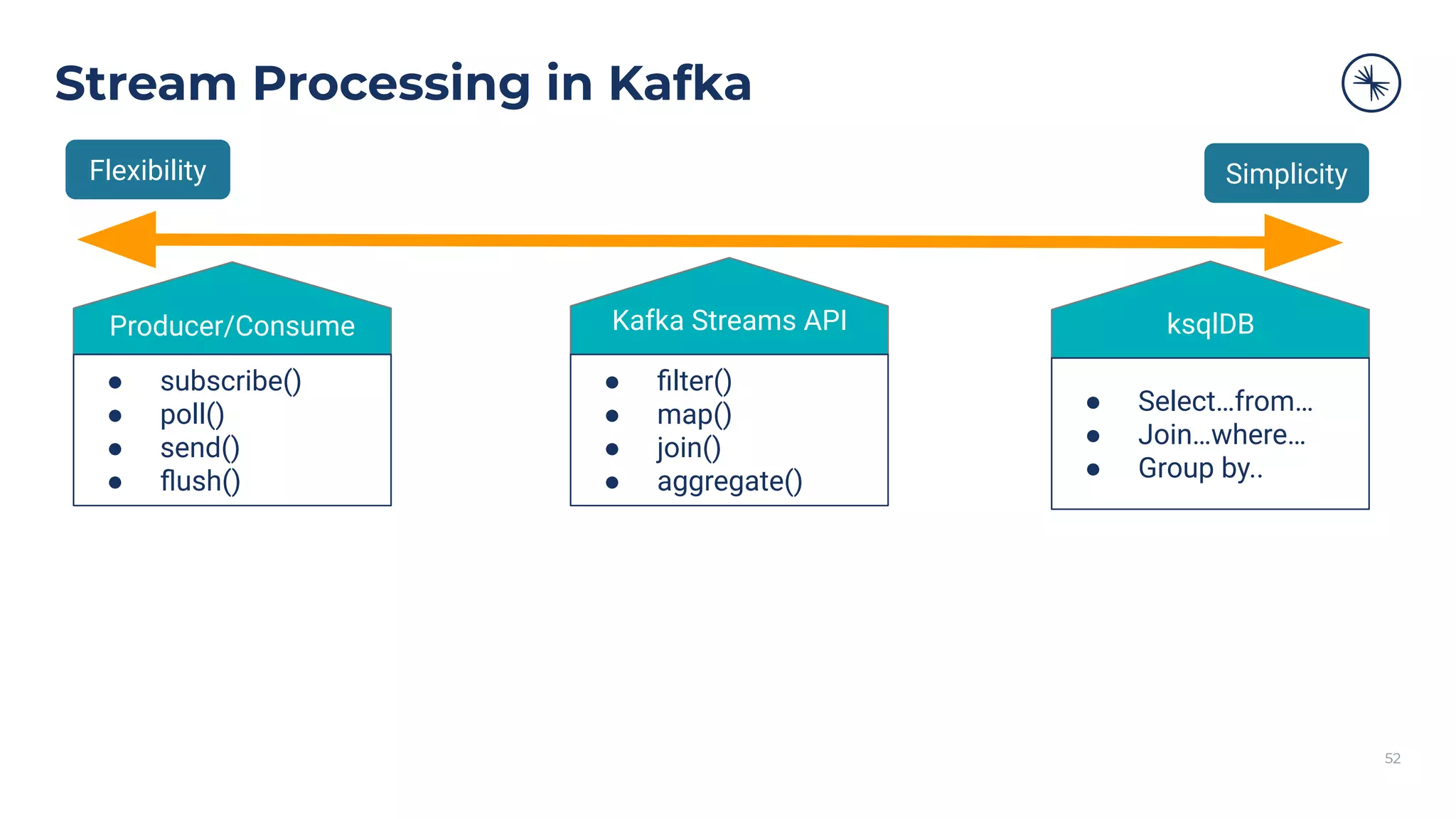
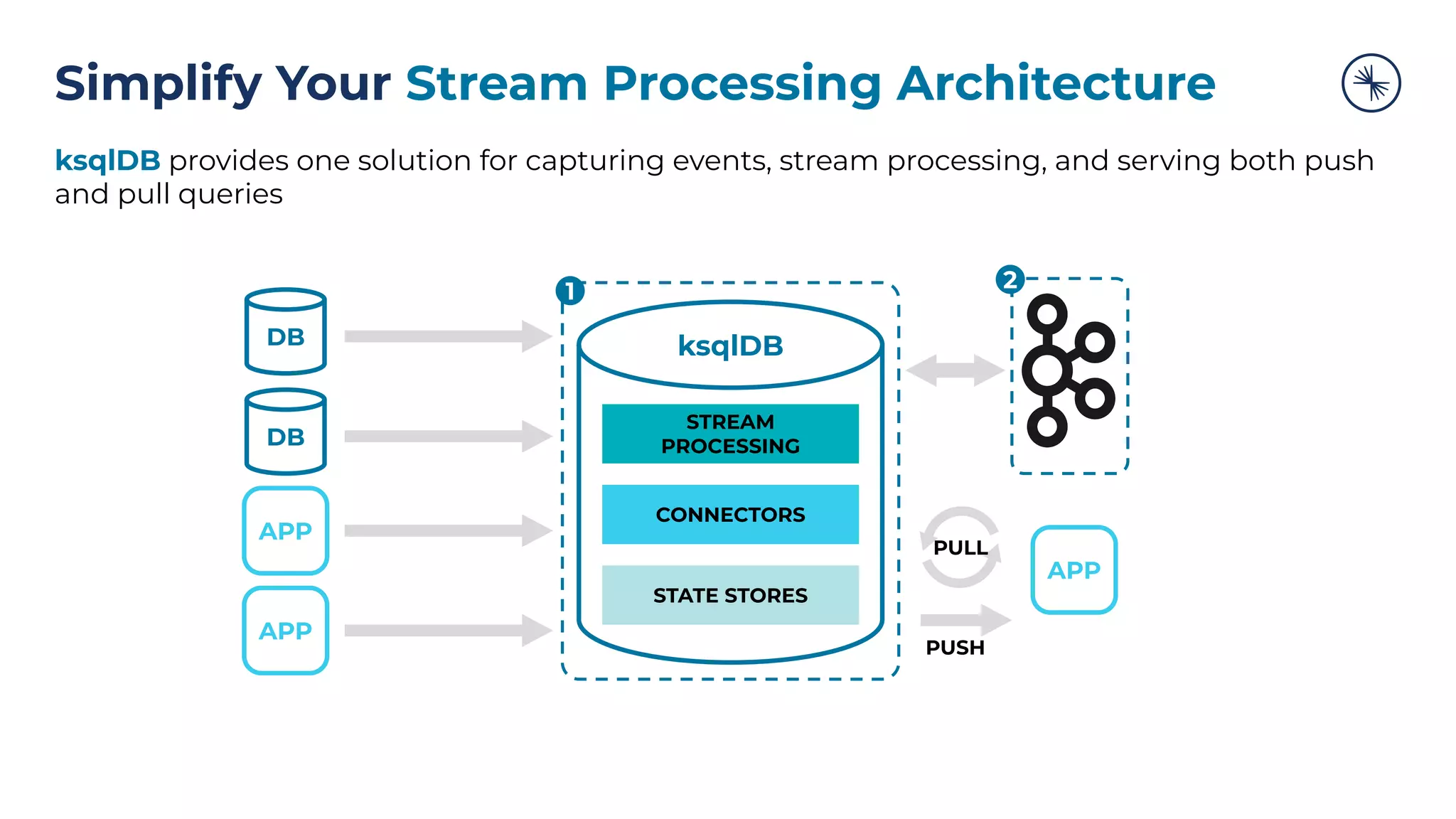




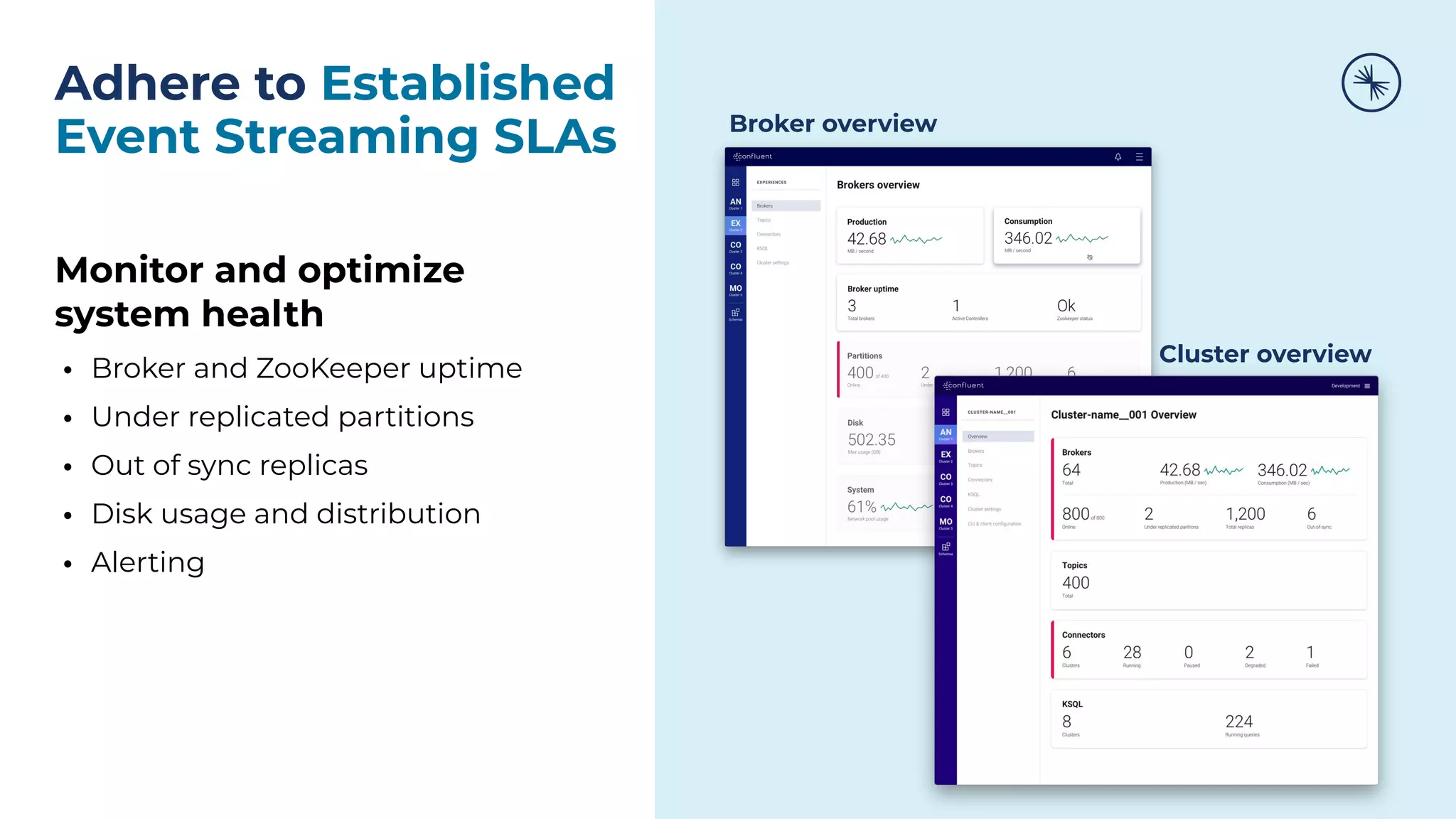





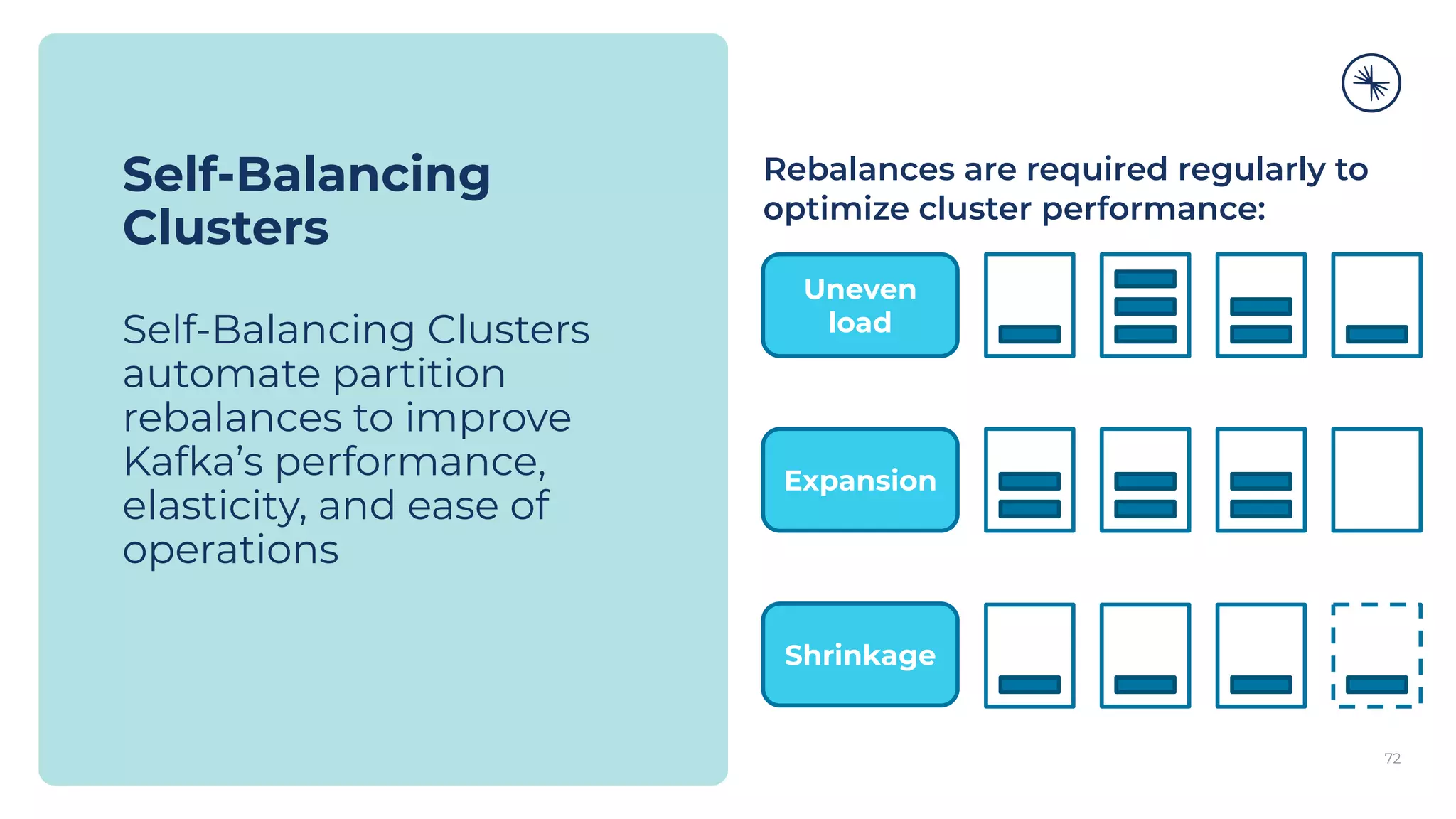
![73 Self-Balancing Clusters Self-Balancing Clusters automate partition rebalances to improve Kafka’s performance, elasticity, and ease of operations Manual Rebalance Process: $ cat partitions-to-move.json { "partitions": [{ "topic": "foo", "partition": 1, "replicas": [1, 2, 4] }, ...], "version": 1 } $ kafka-reassign-partitions ... Confluent Platform: No complex math, no risk of human error Self-Balancing](https://image.slidesharecdn.com/confluenton-premcomponentsintroduction-lme-18thnov-211122150559/75/Set-your-Data-in-Motion-with-Confluent-Apache-Kafka-Tech-Talk-Series-LME-53-2048.jpg)

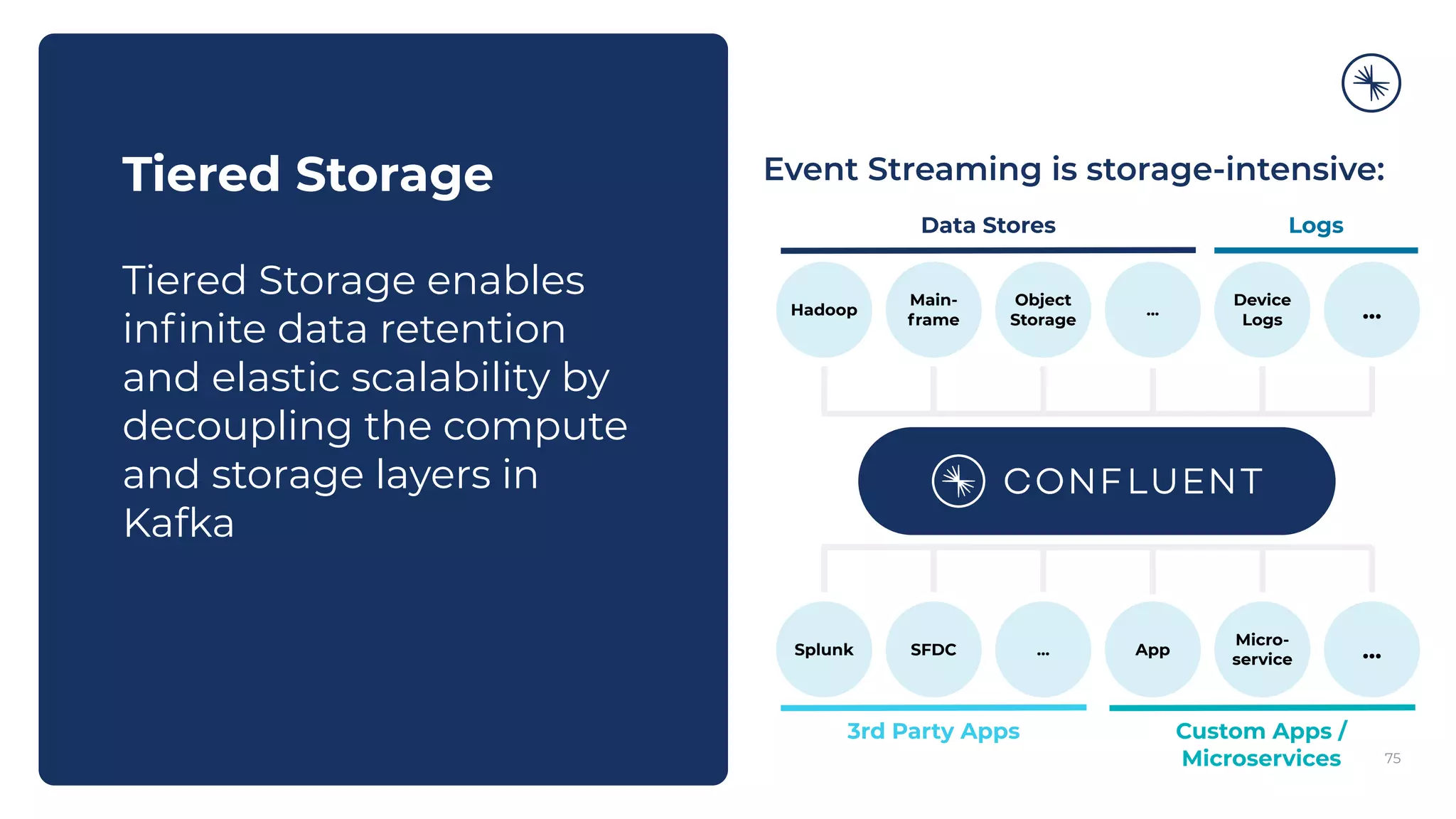
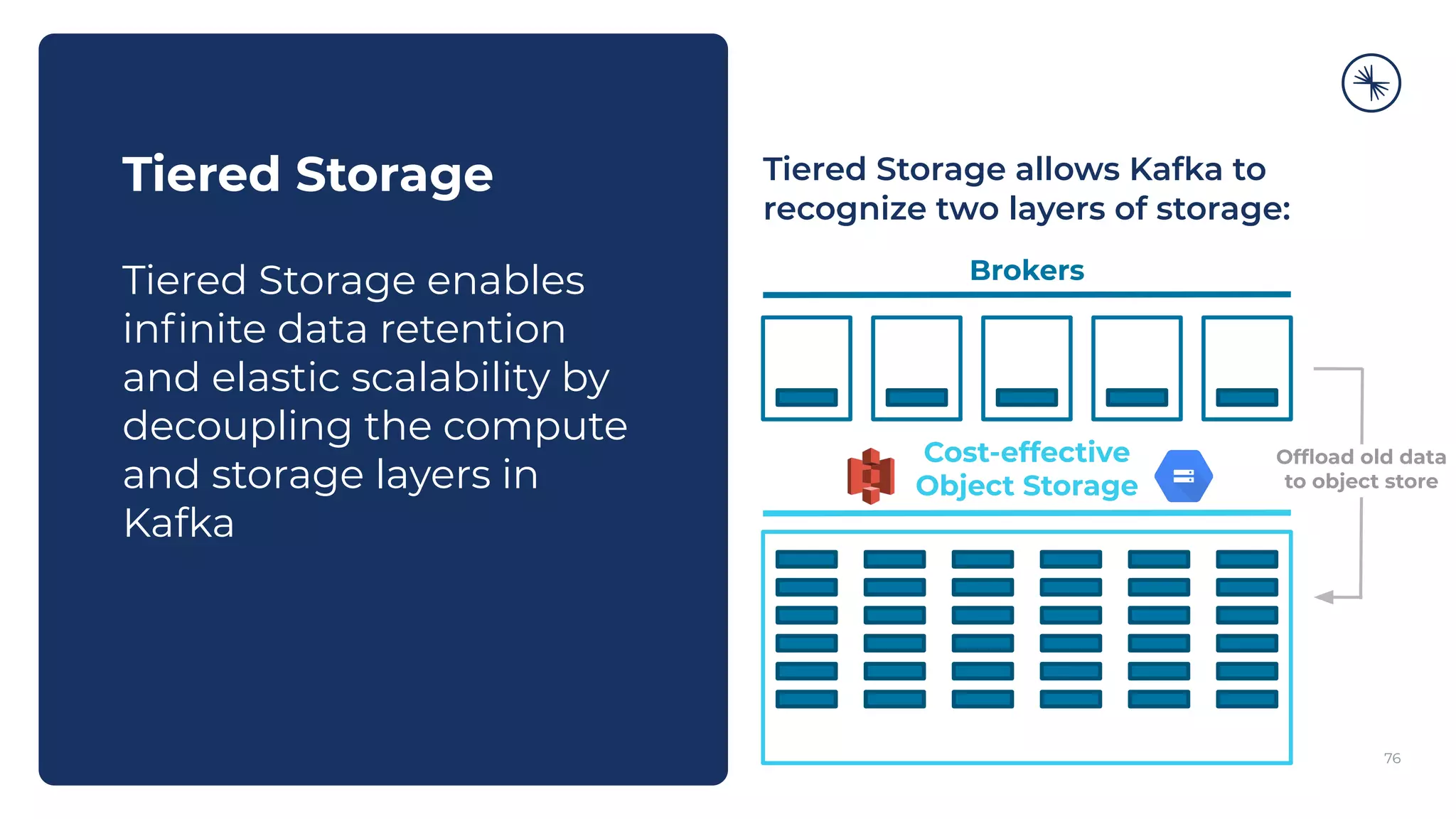


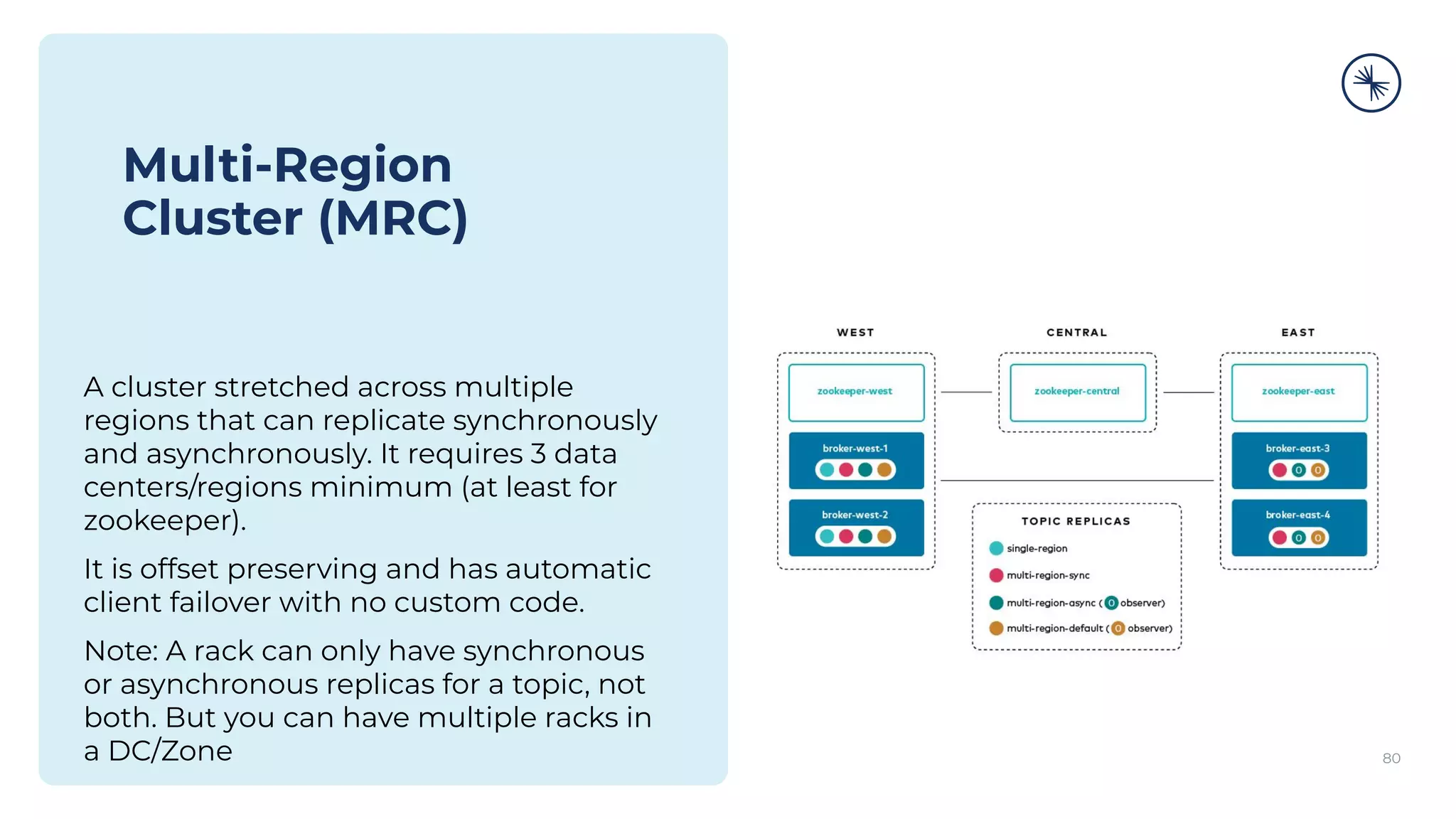

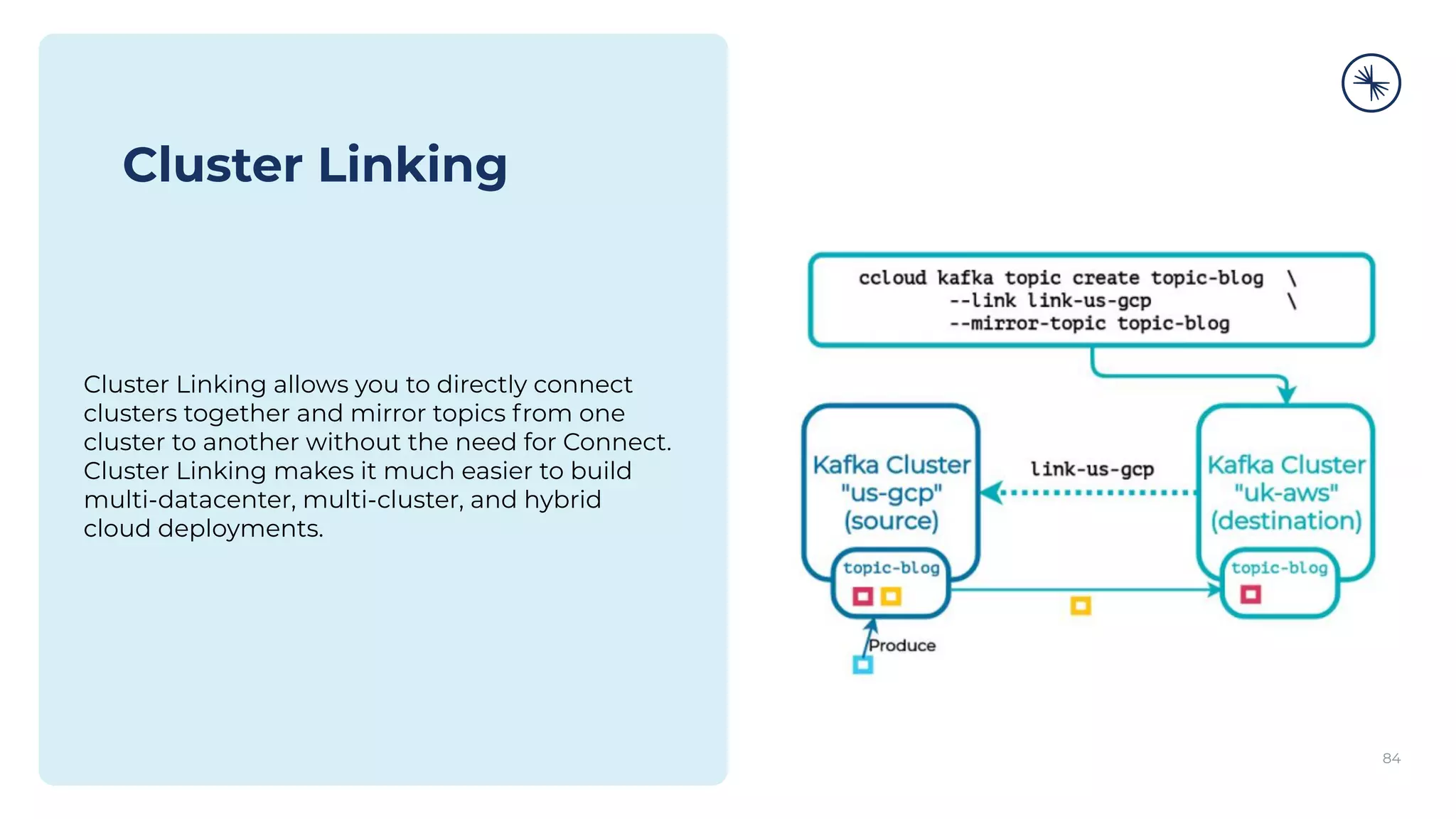

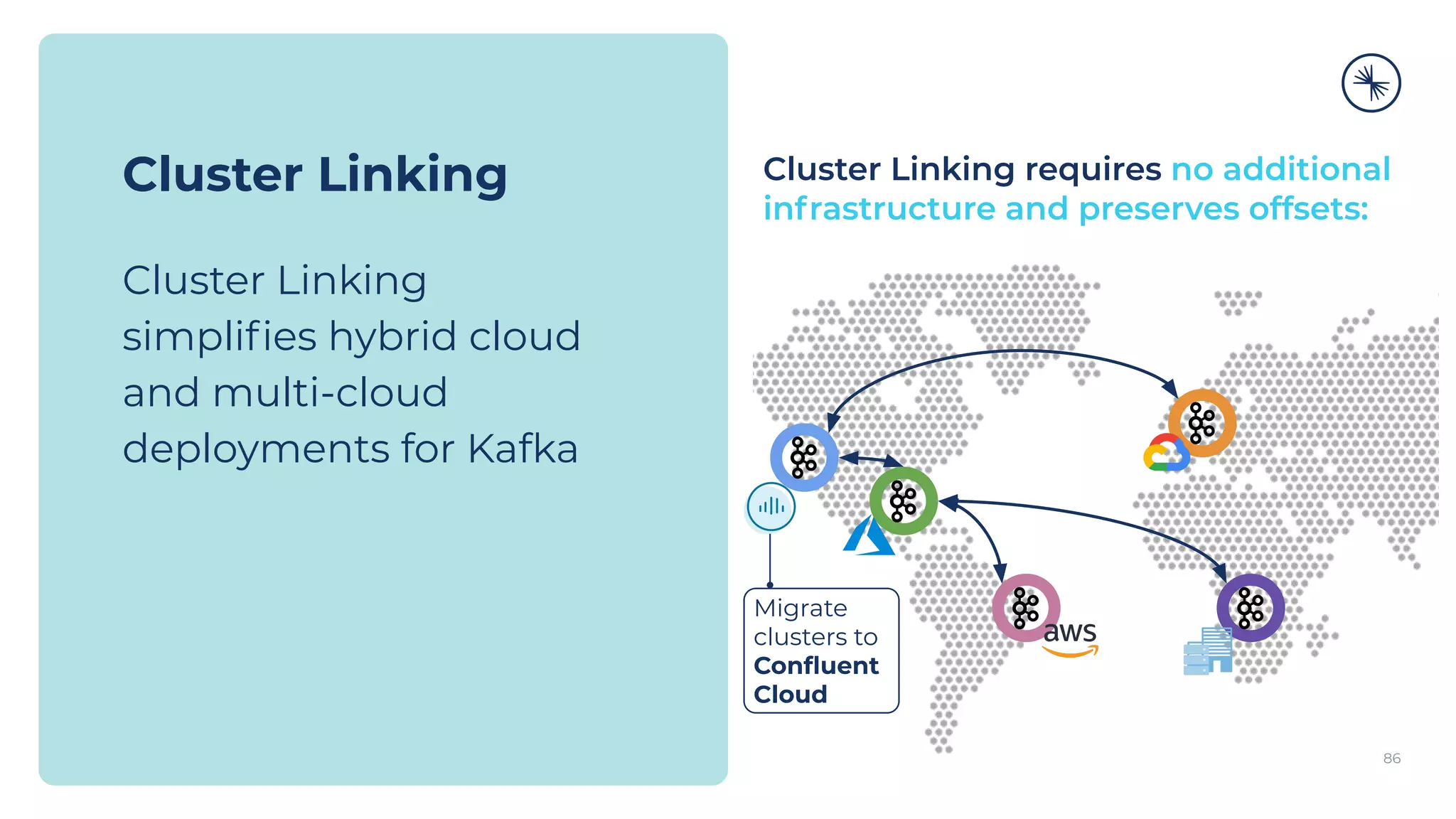



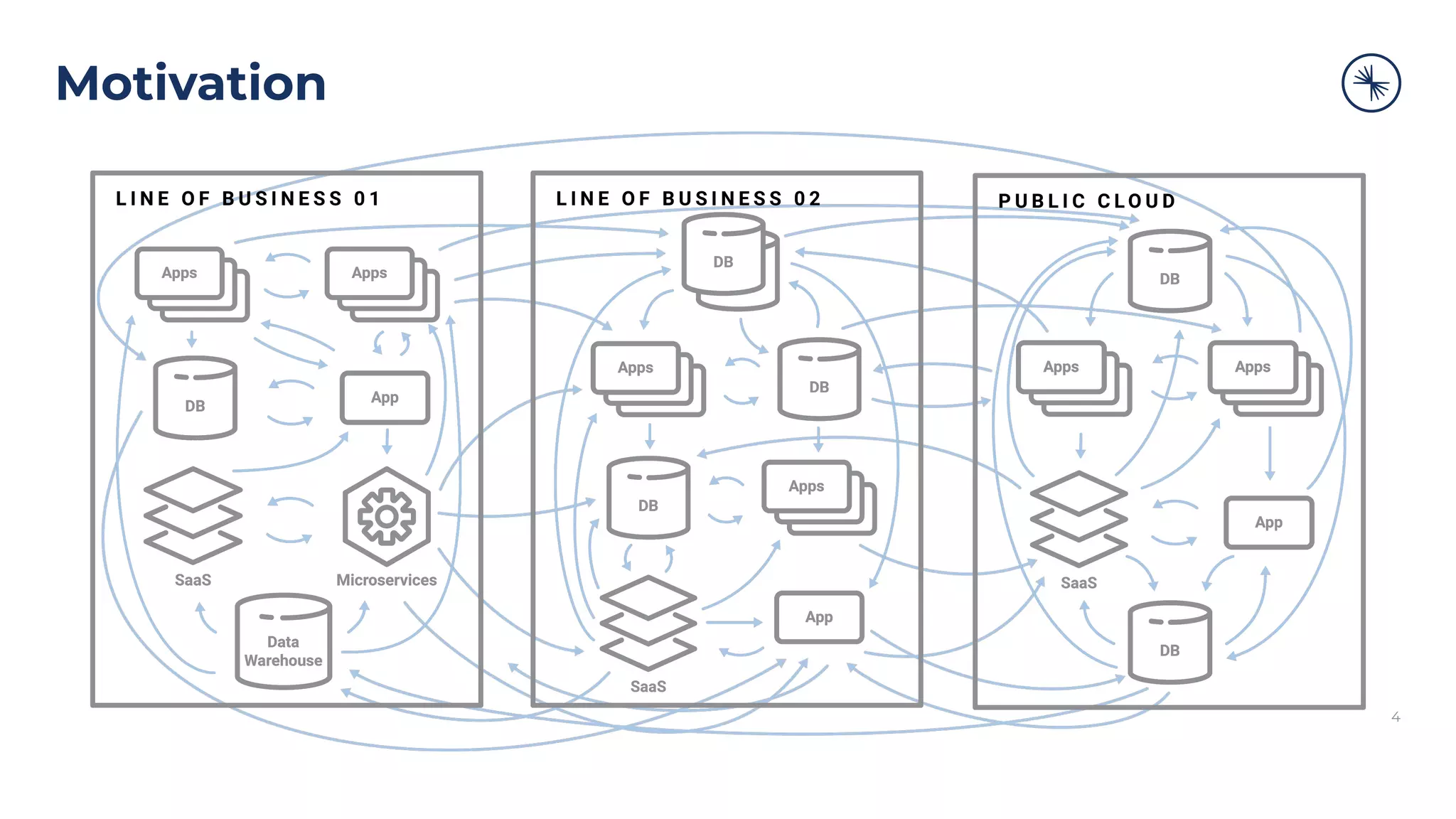
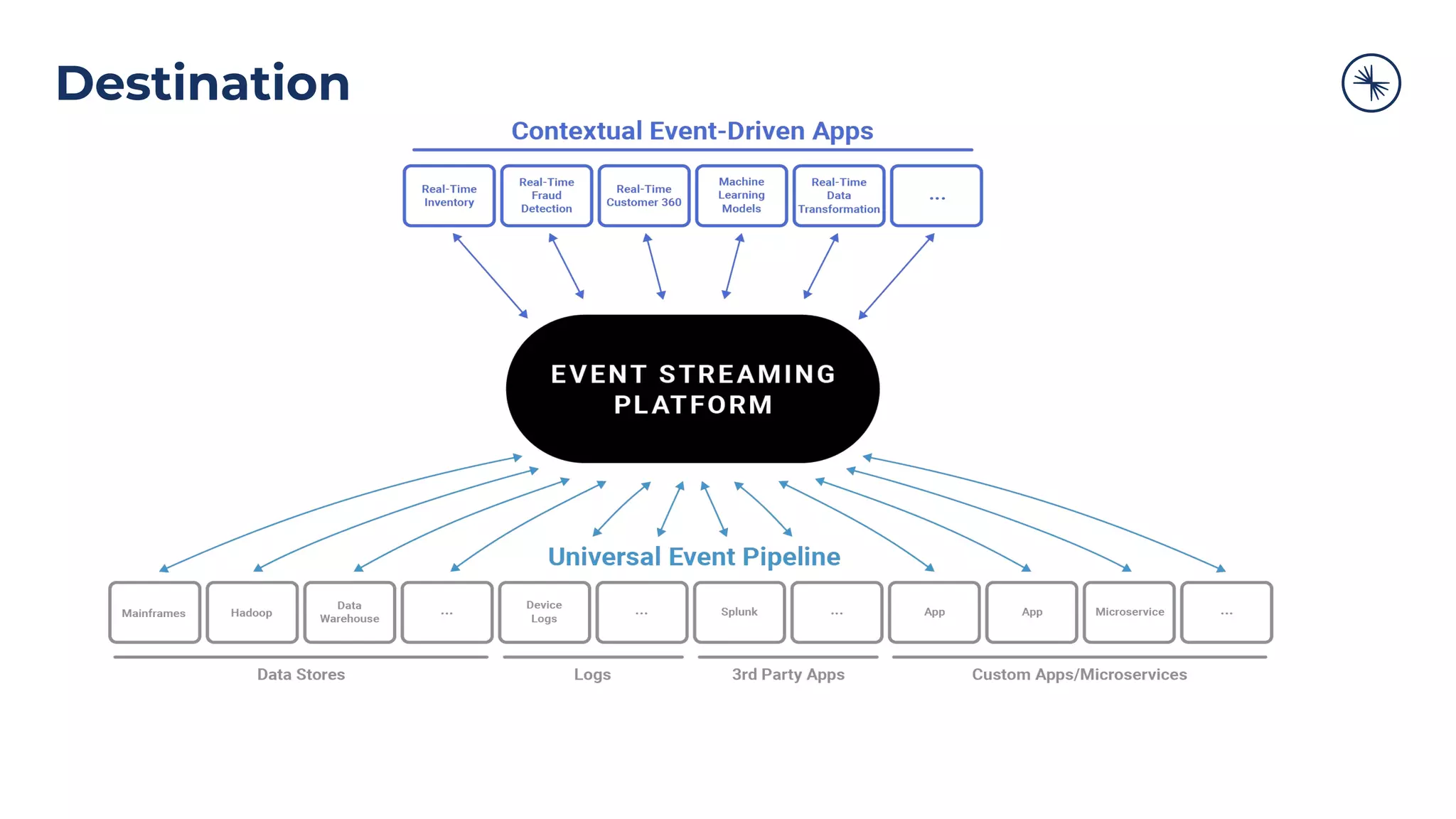
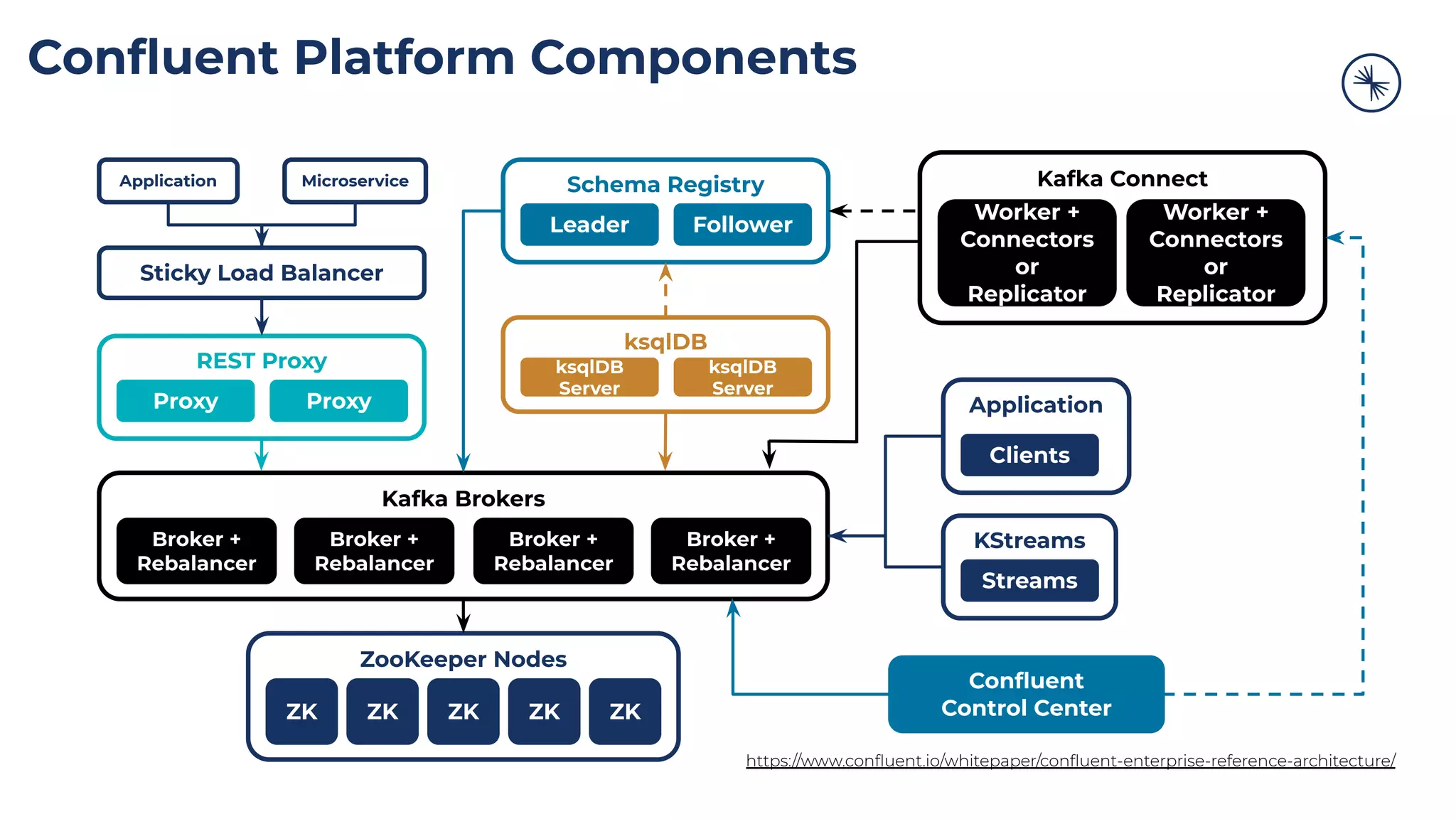
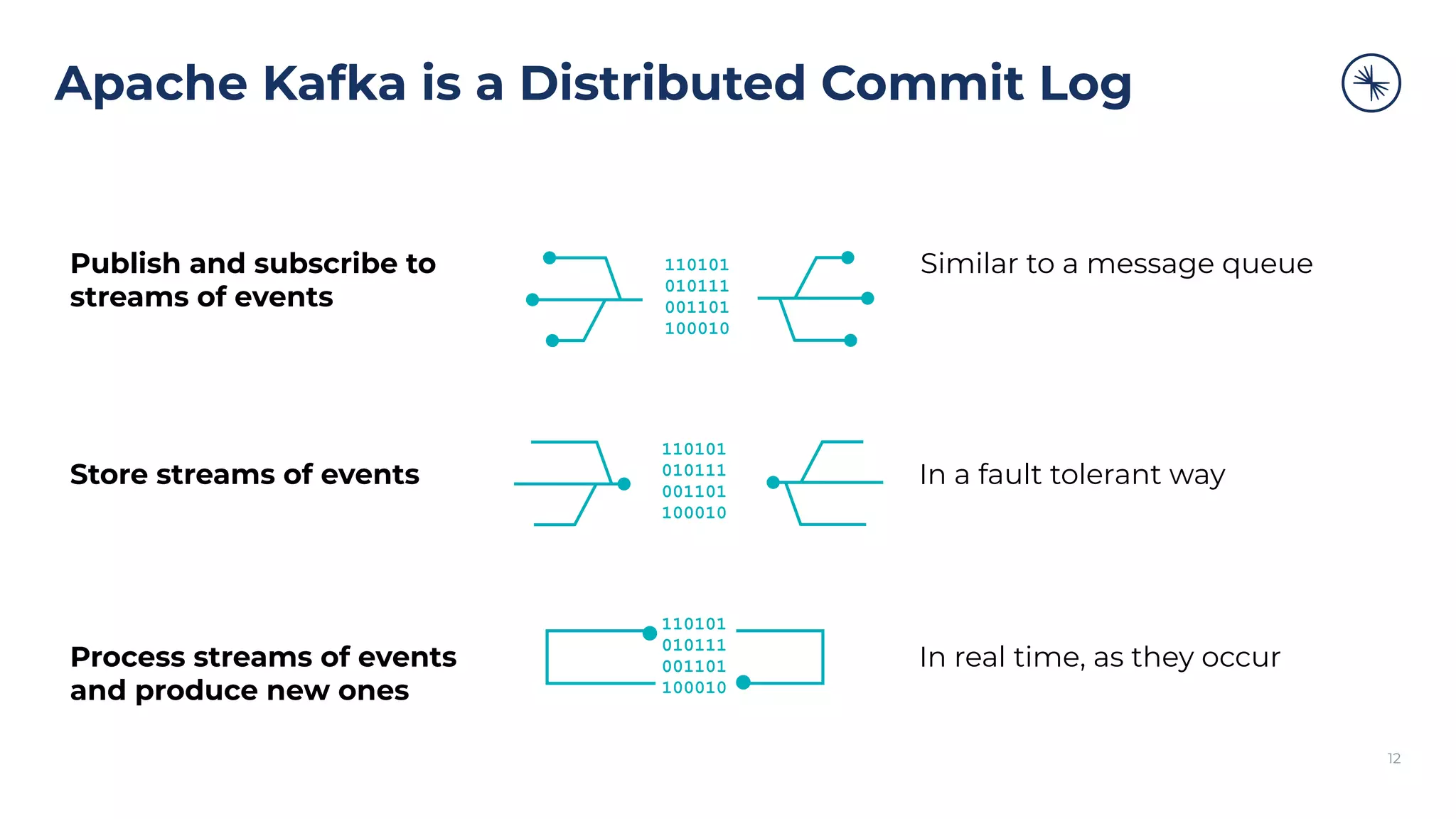
The Confluent Platform is an enterprise event streaming platform built around Apache Kafka, designed for dynamic performance and elasticity. It features components like brokers, Zookeeper, a schema registry, and tools for stream processing, data compatibility, and security to ensure efficient operations at scale. The platform also supports multi-region clusters and provides features for seamless integration, monitoring, and management via a comprehensive user interface.