Downloaded 192 times





















The document discusses Apache Flink, an open source stream processing framework. It provides high throughput and low latency processing of both streaming and batch data. Flink allows for explicit handling of event time, stateful stream processing with exactly-once semantics, and high performance. It also supports features like windowing, sessionization, and complex event processing that are useful for building streaming applications.
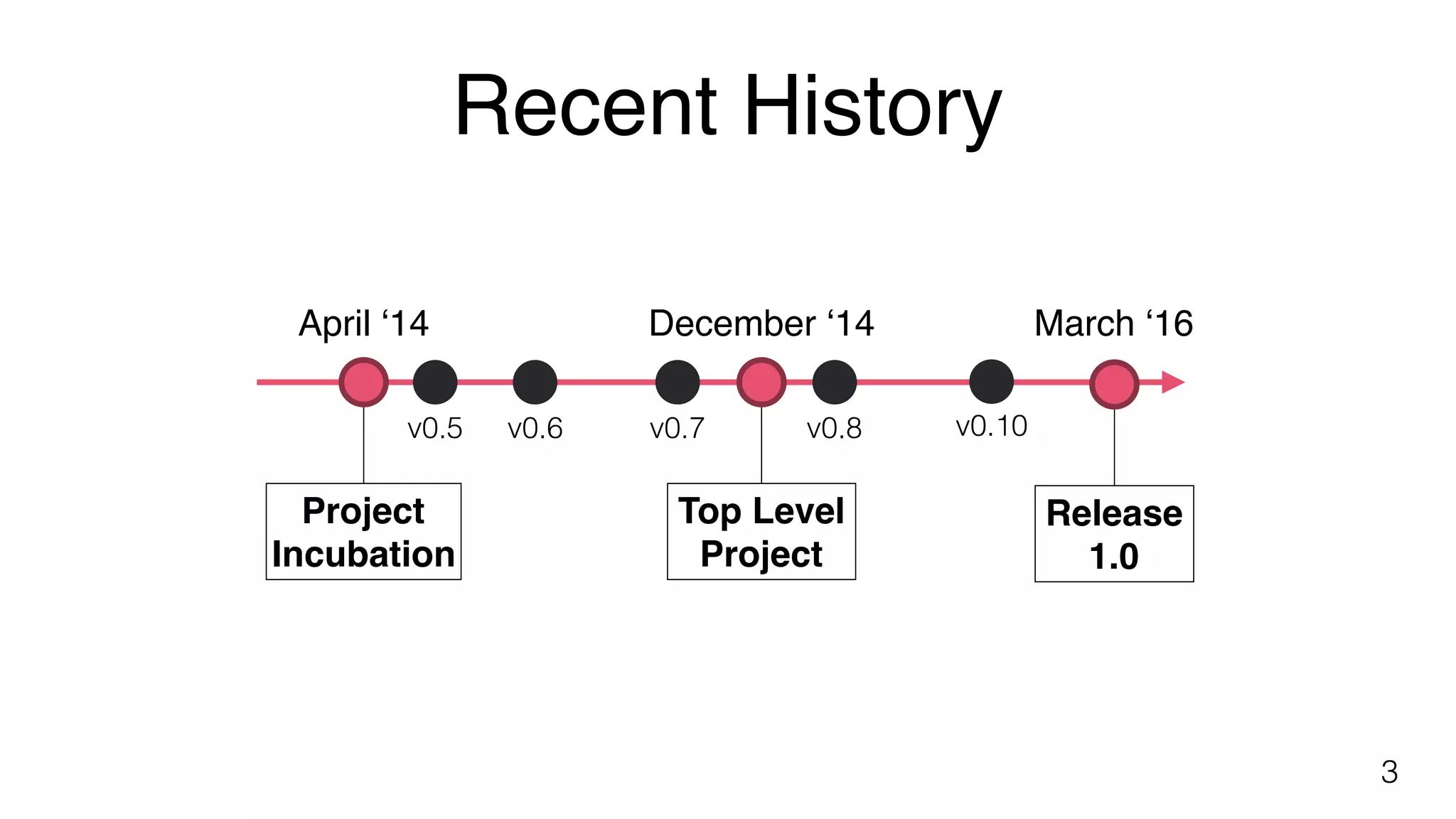
Presentation by Ufuk Celebi at Hadoop Summit Dublin on April 13, 2016, introduces Unified Stream & Batch Processing with Apache Flink.
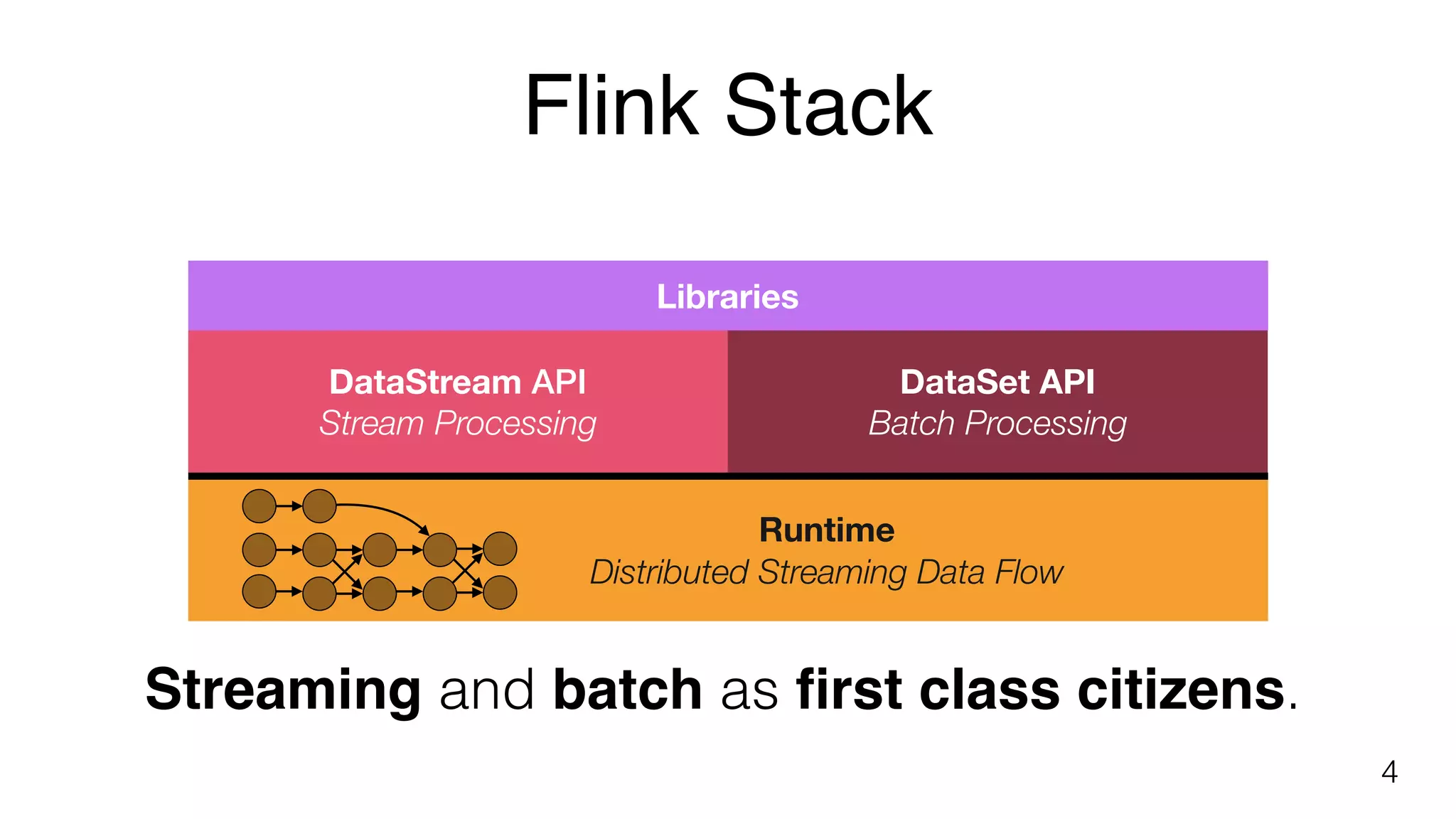
Apache Flink is an open-source stream processing framework notable for event time handling, state and fault tolerance, low latency, and high throughput.
Example of a basic counting application to track visitors and ads, which provides a foundation for generalizable solutions.
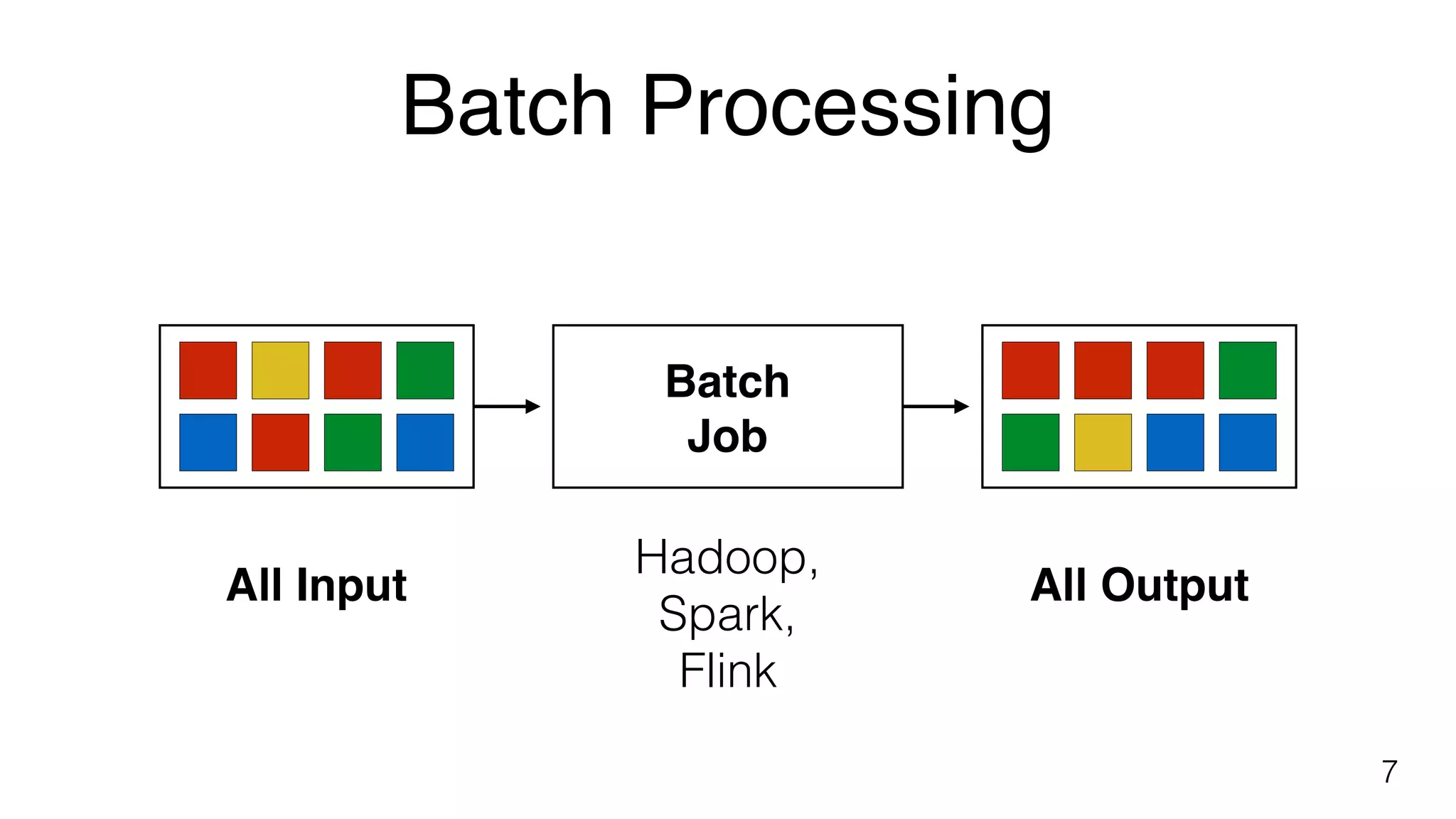
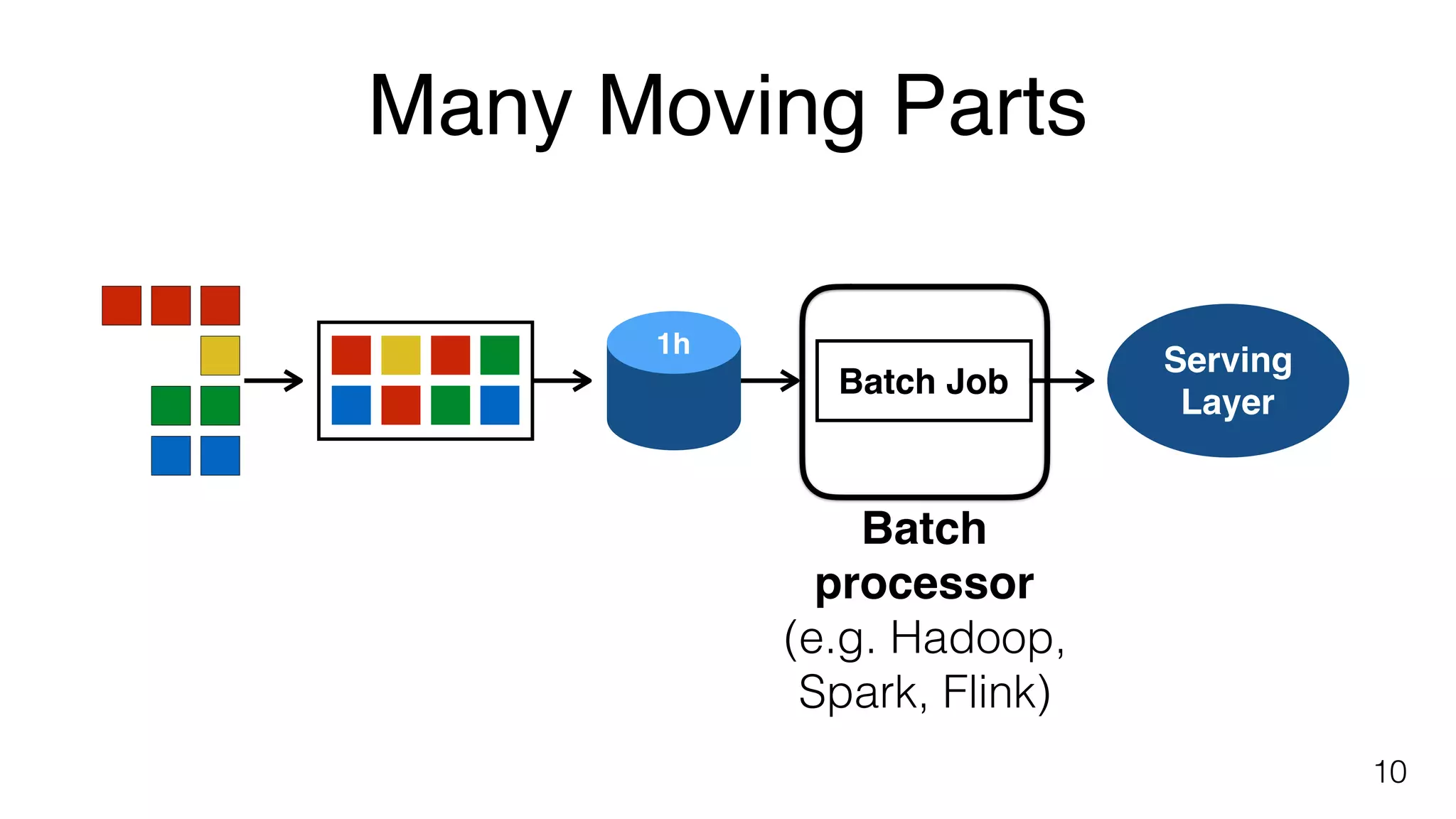
Batch processing overview using various platforms like Hadoop, Spark, and Flink, illustrated by counting events in a dataset.
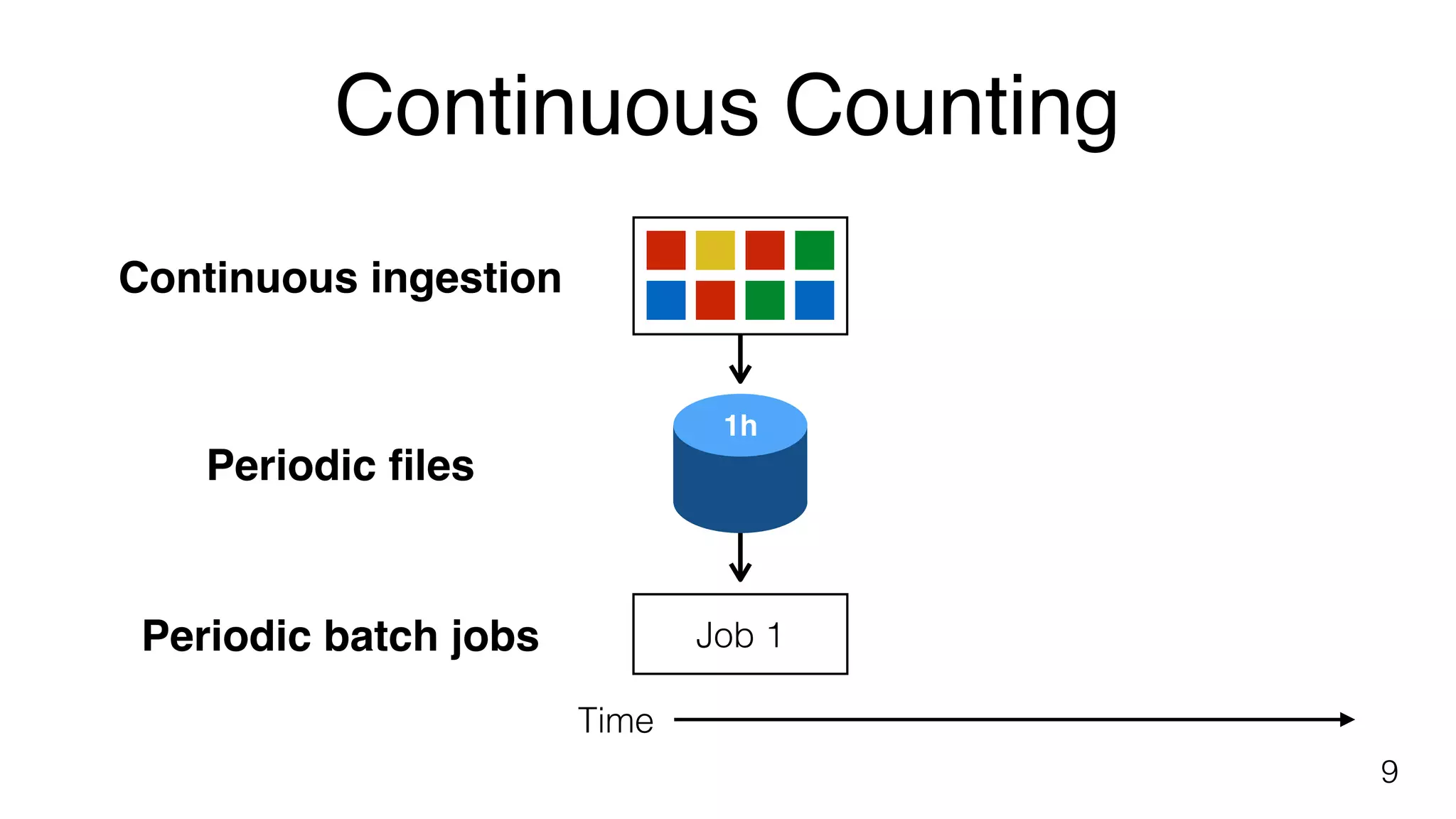
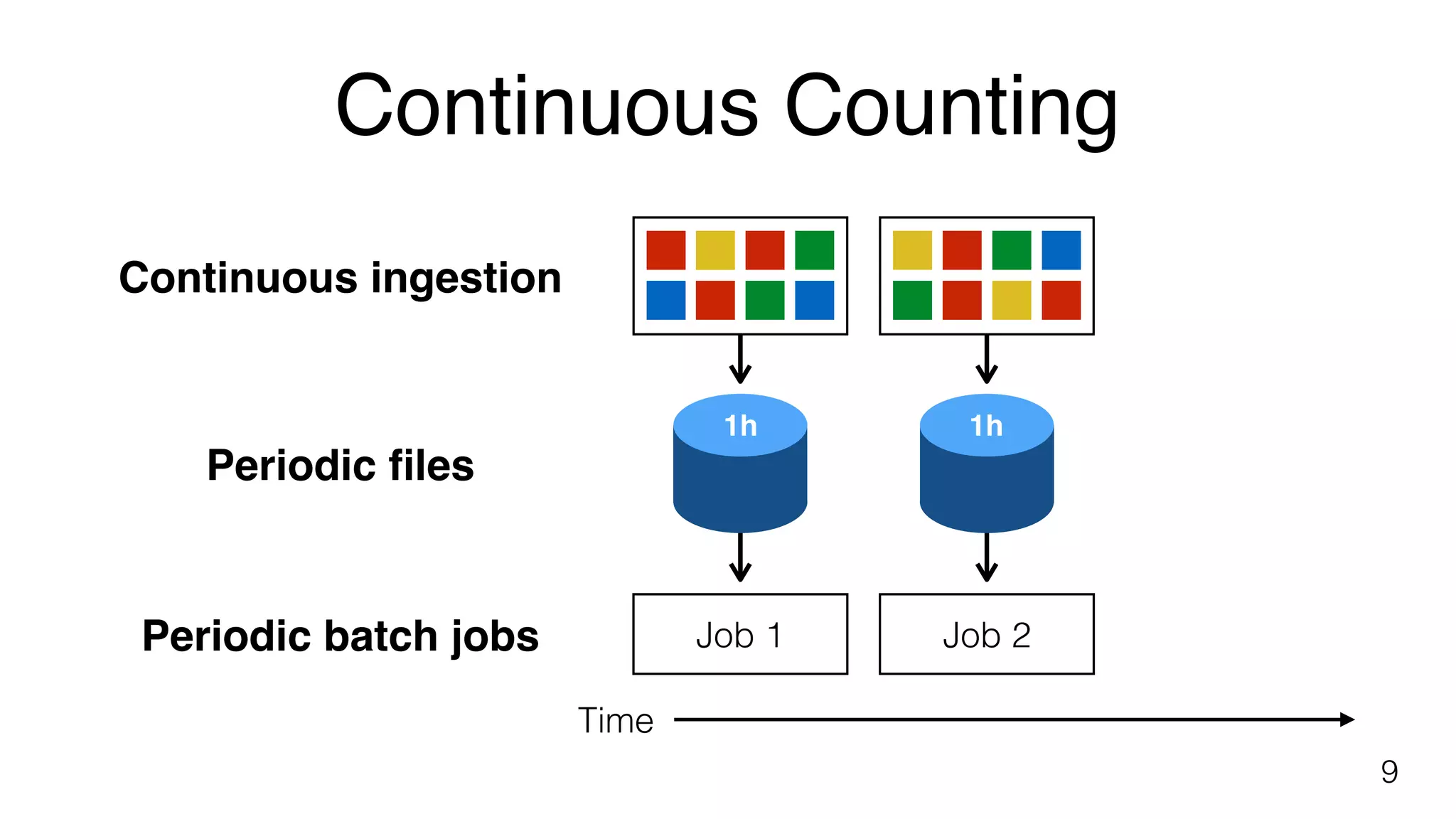
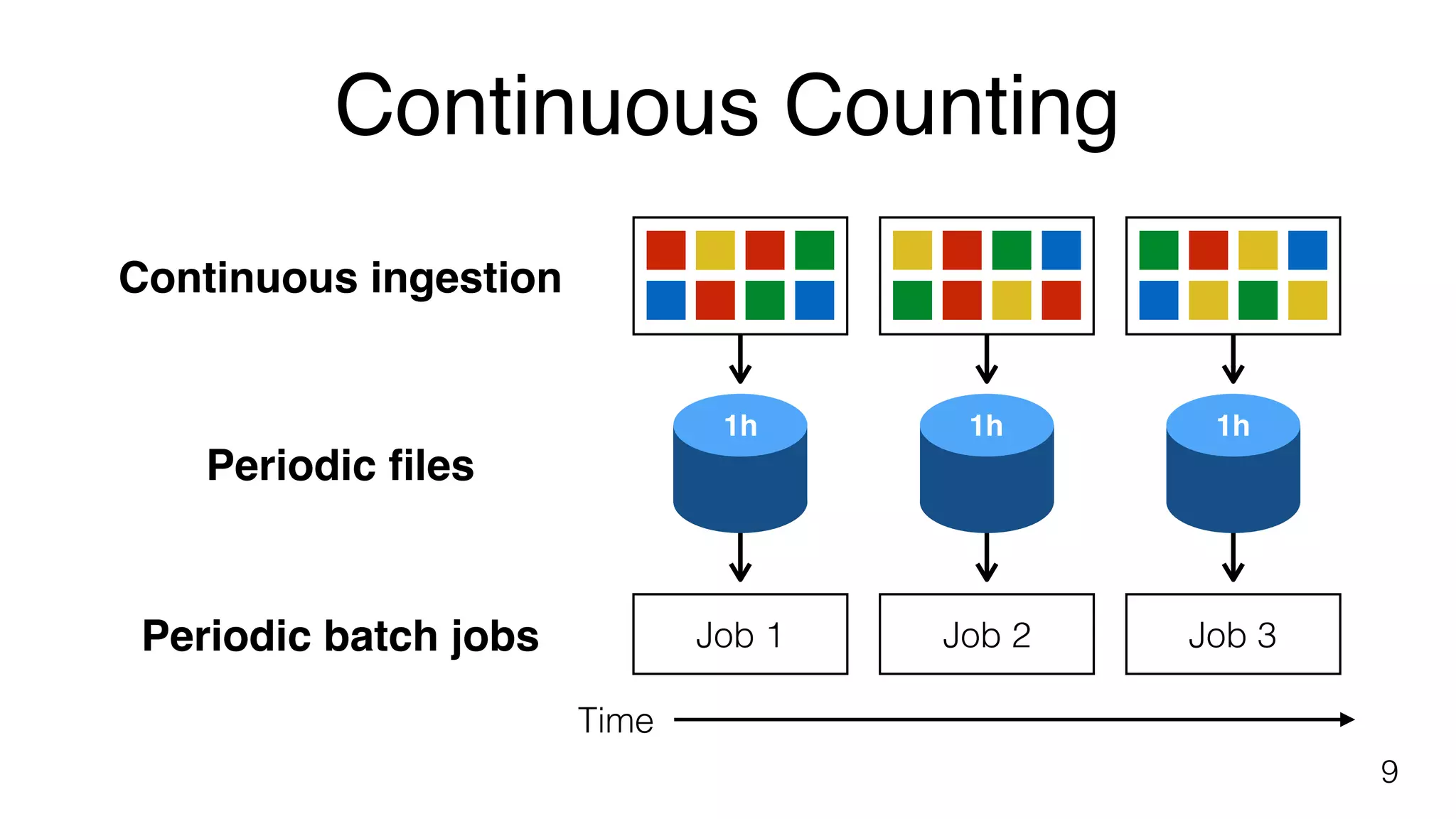
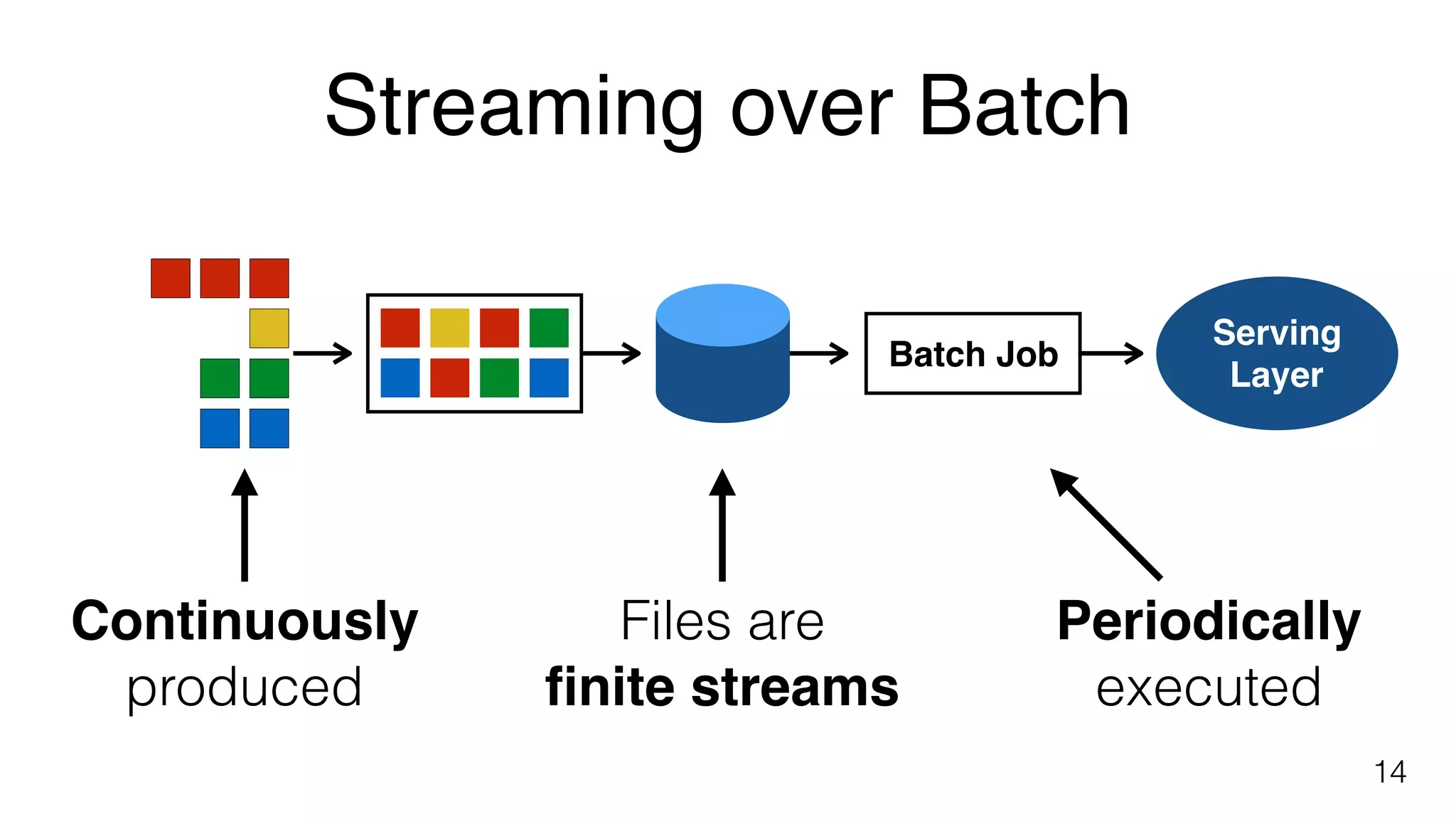
Concept of continuous counting with periodic batch jobs to manage incoming data over defined time intervals.
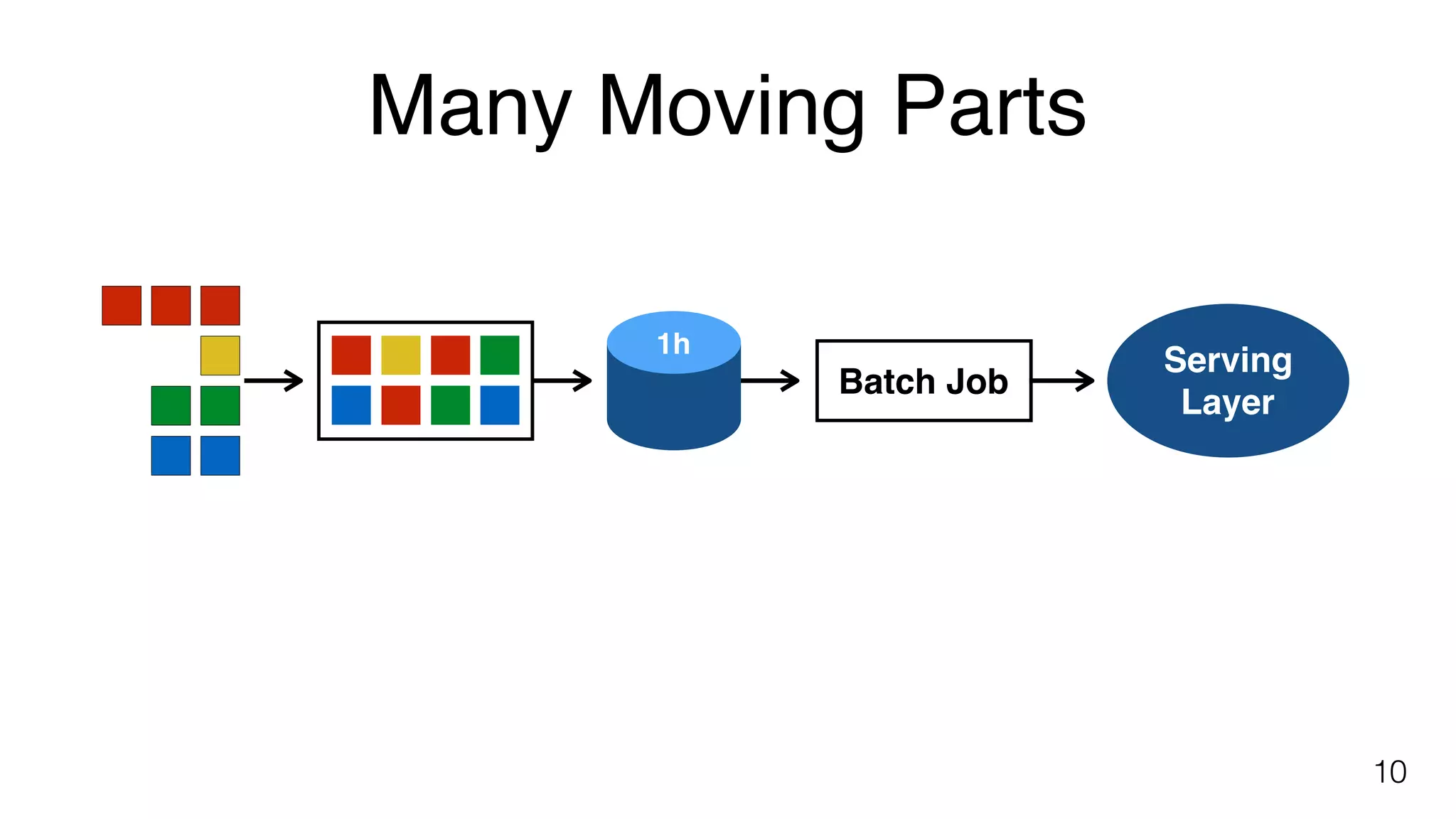
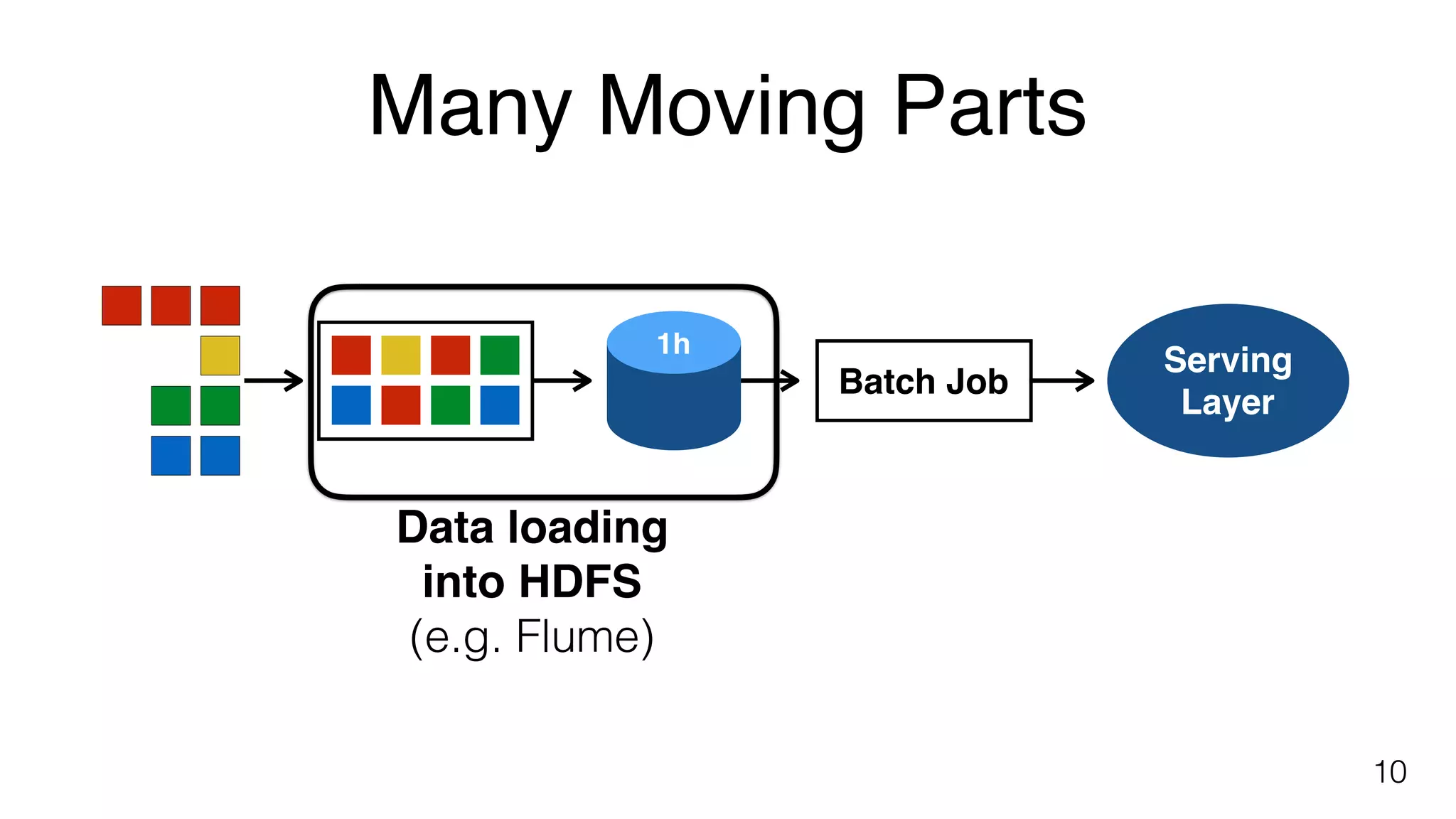
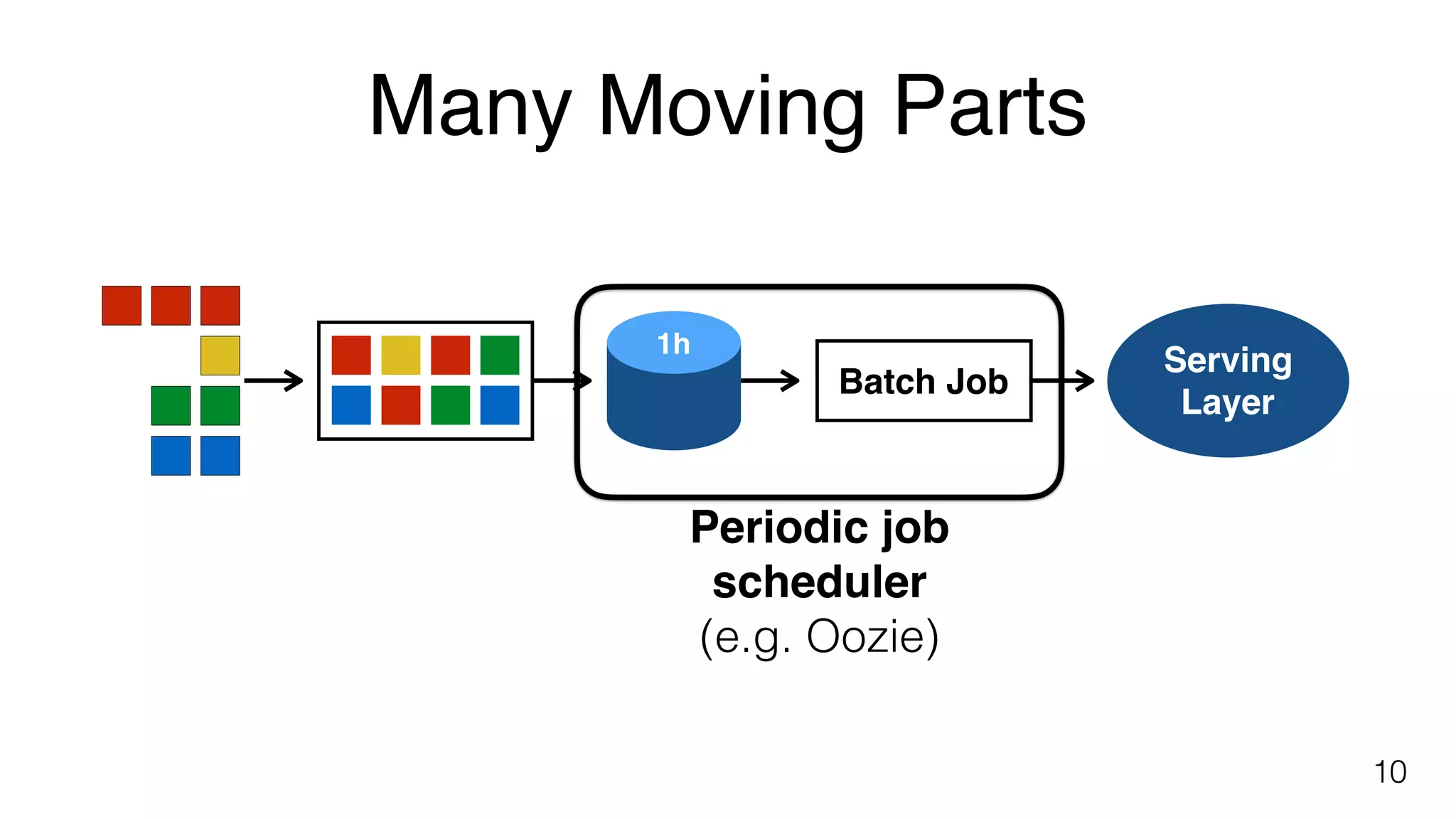
Explains complexities in batch processing including data loading, job scheduling, and using processors like Hadoop, Spark, and Flink.
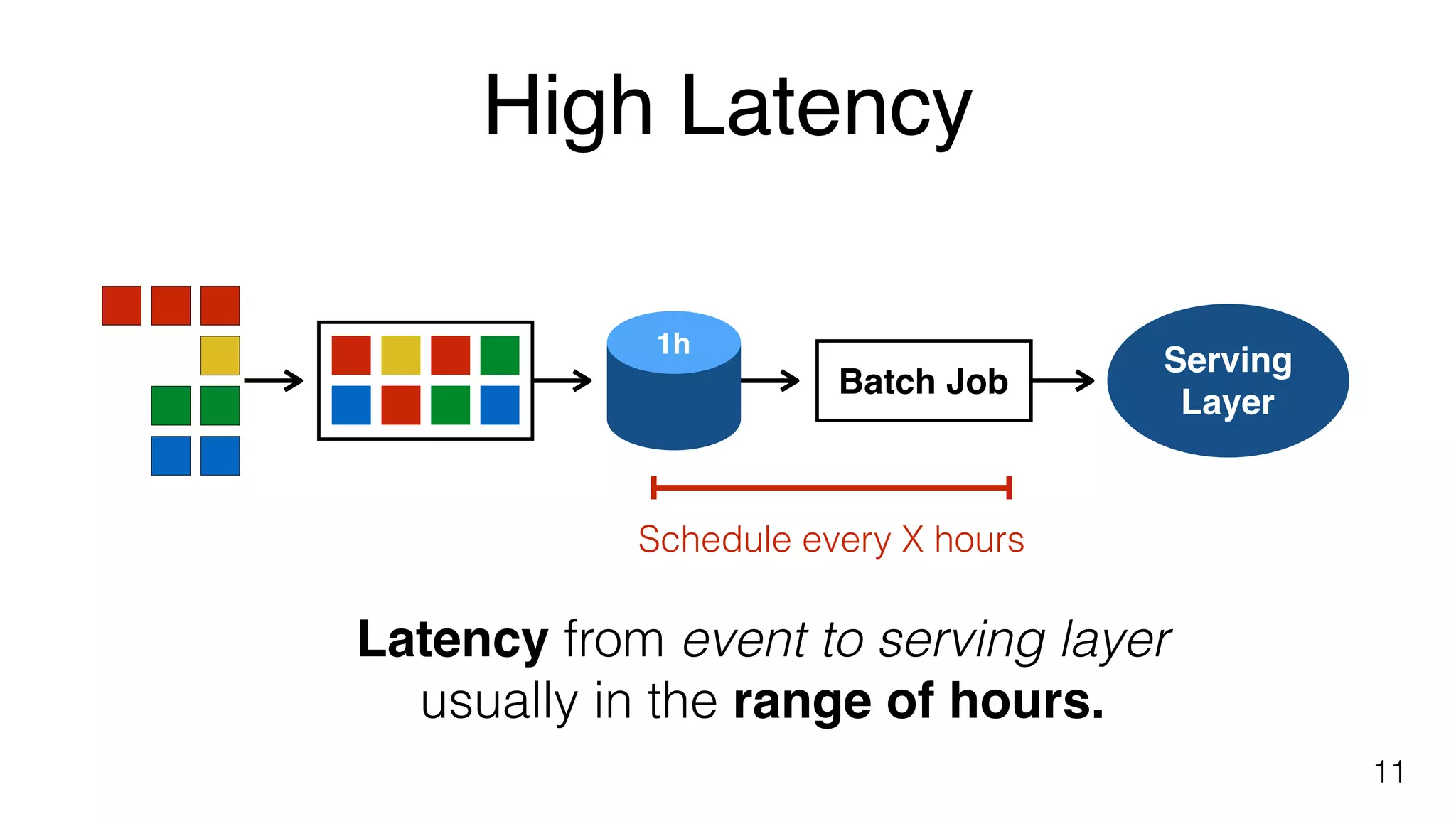
High latency issues in batch jobs discussed, highlighting the delay from event processing to serving layer.
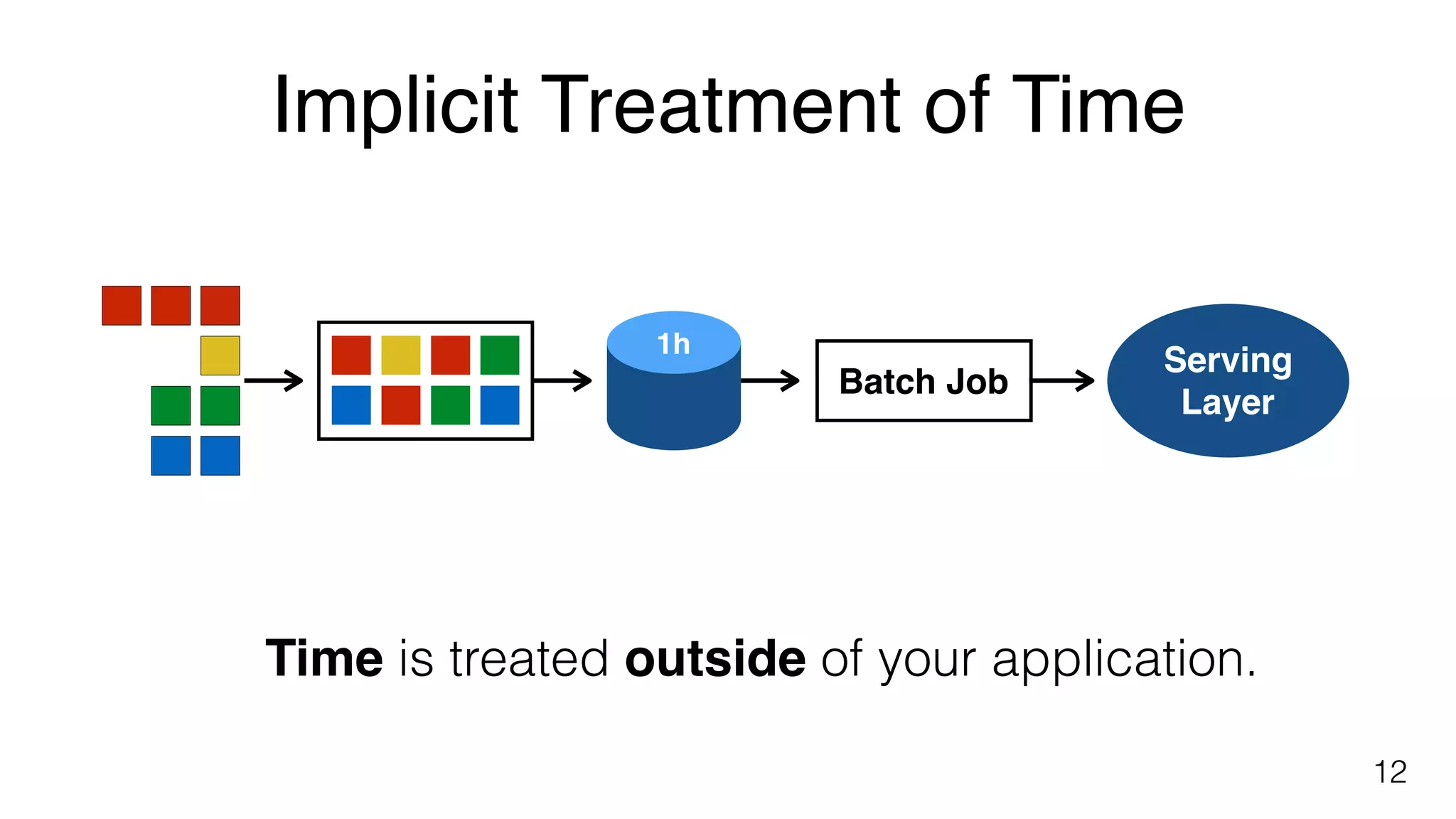
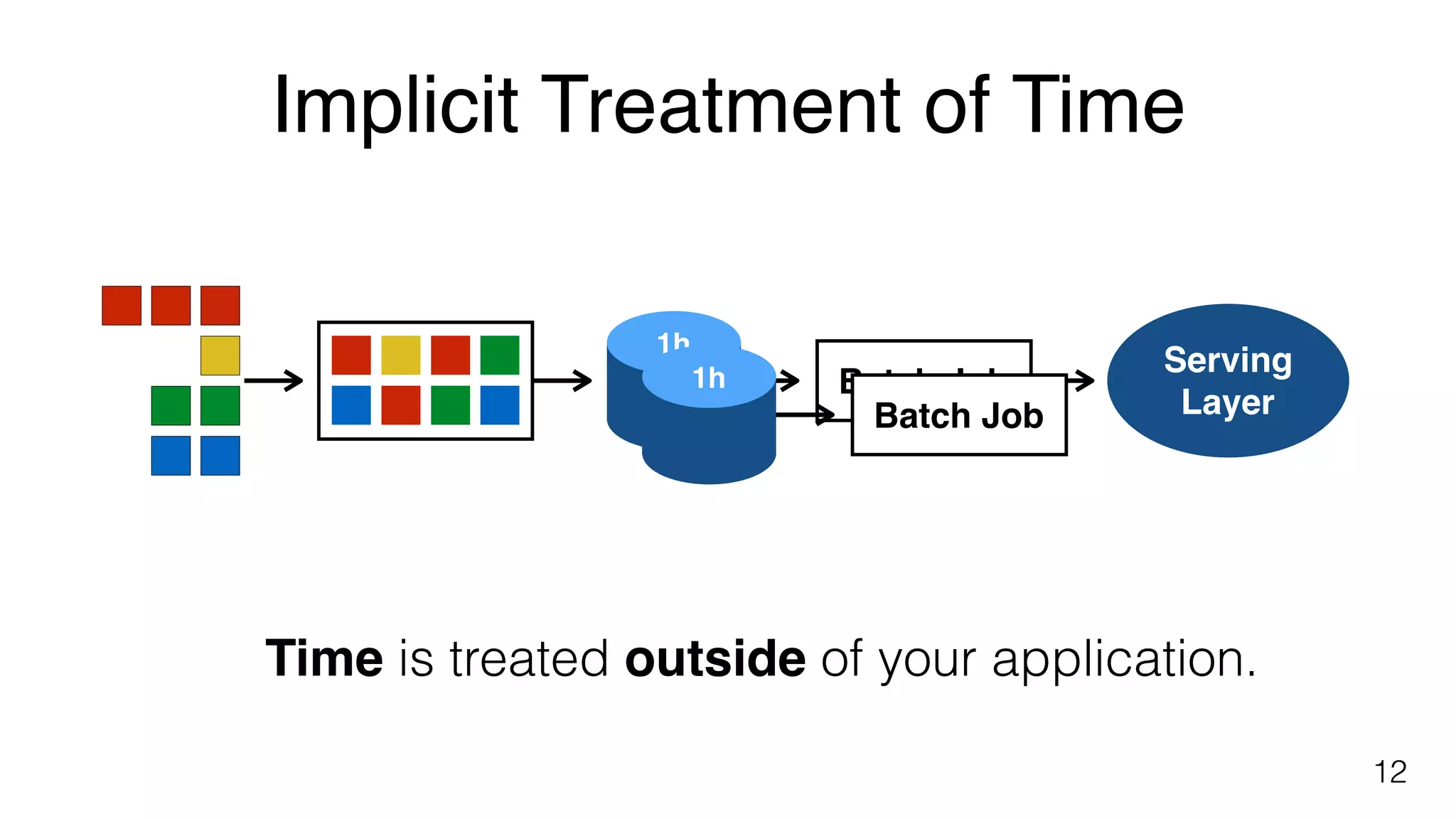
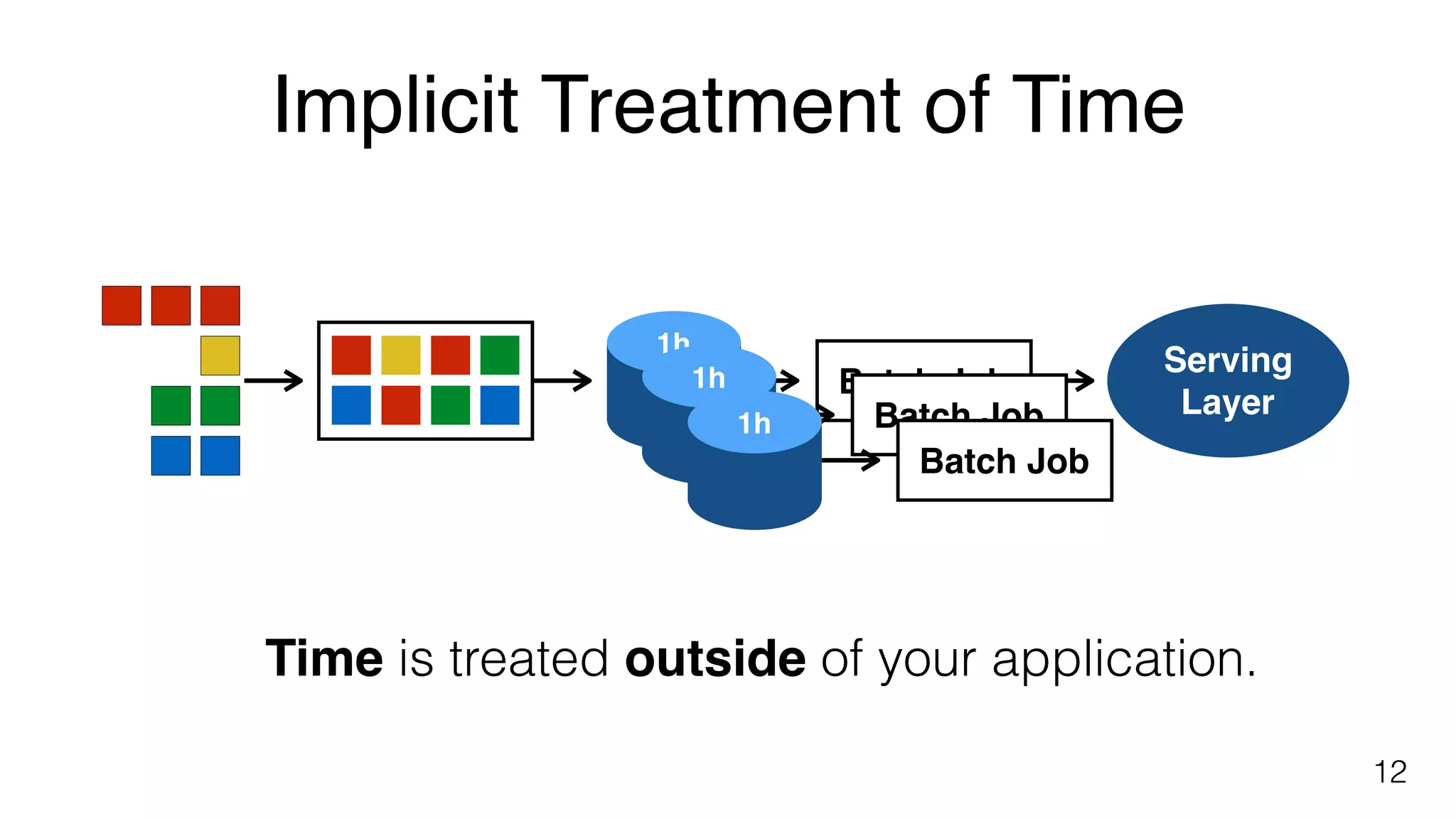
Treatment of time in batch jobs illustrated through examples, emphasizing the implicit nature of time within files.
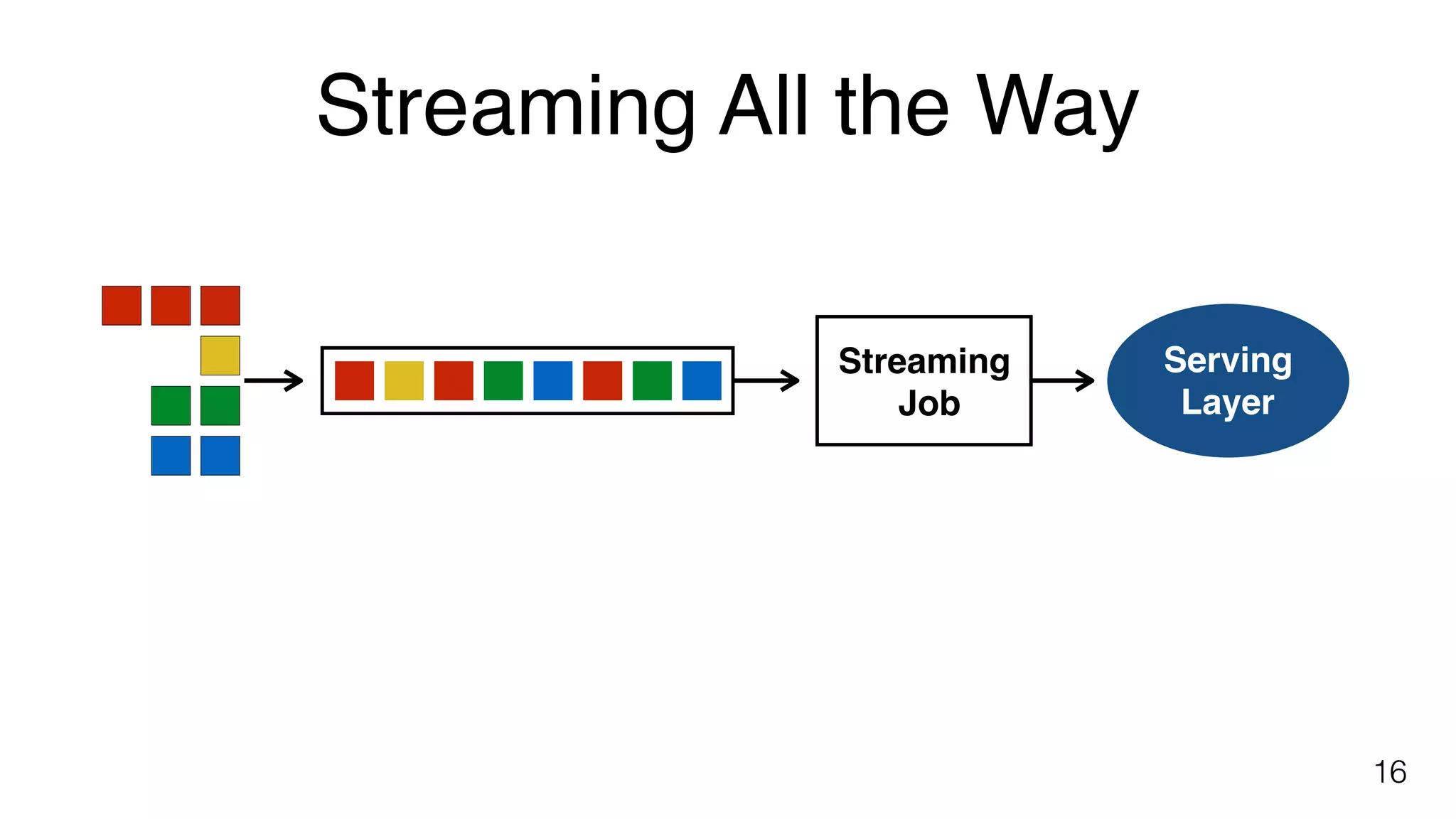
Shift towards dedicated stream processing, reducing reliance on batch processors and avoiding lambda architectures, enhanced by modern solutions like Flink.
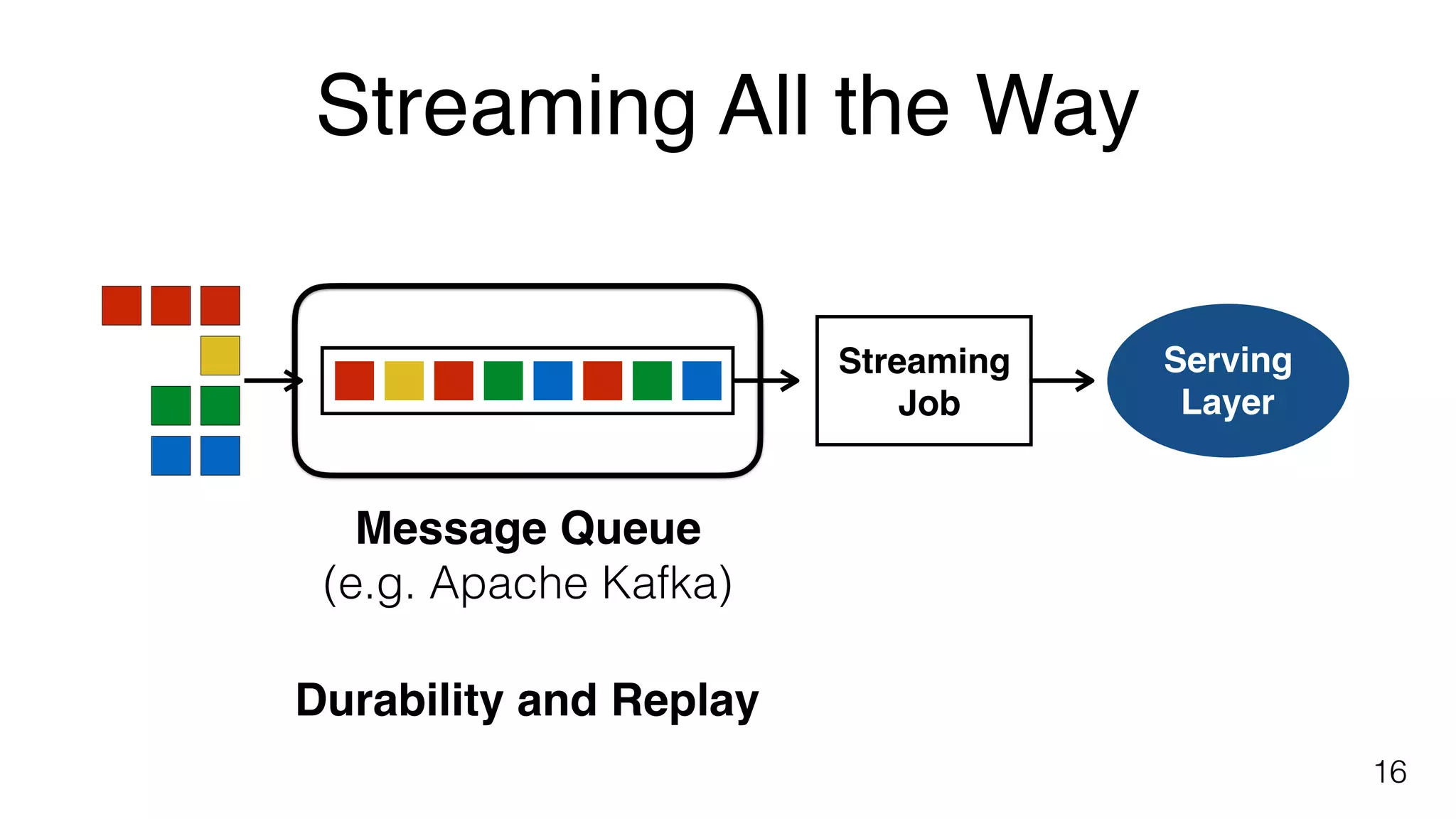
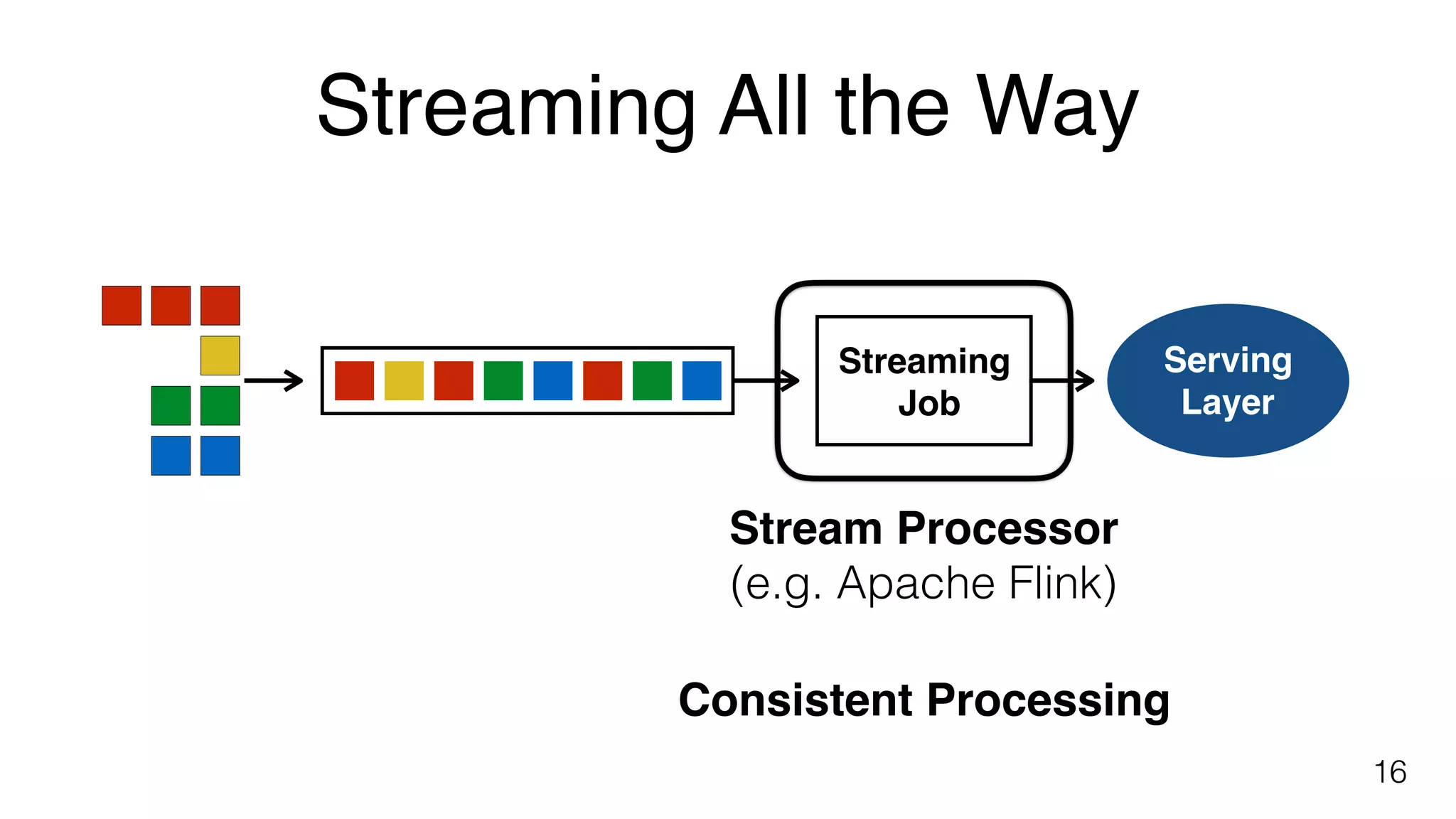
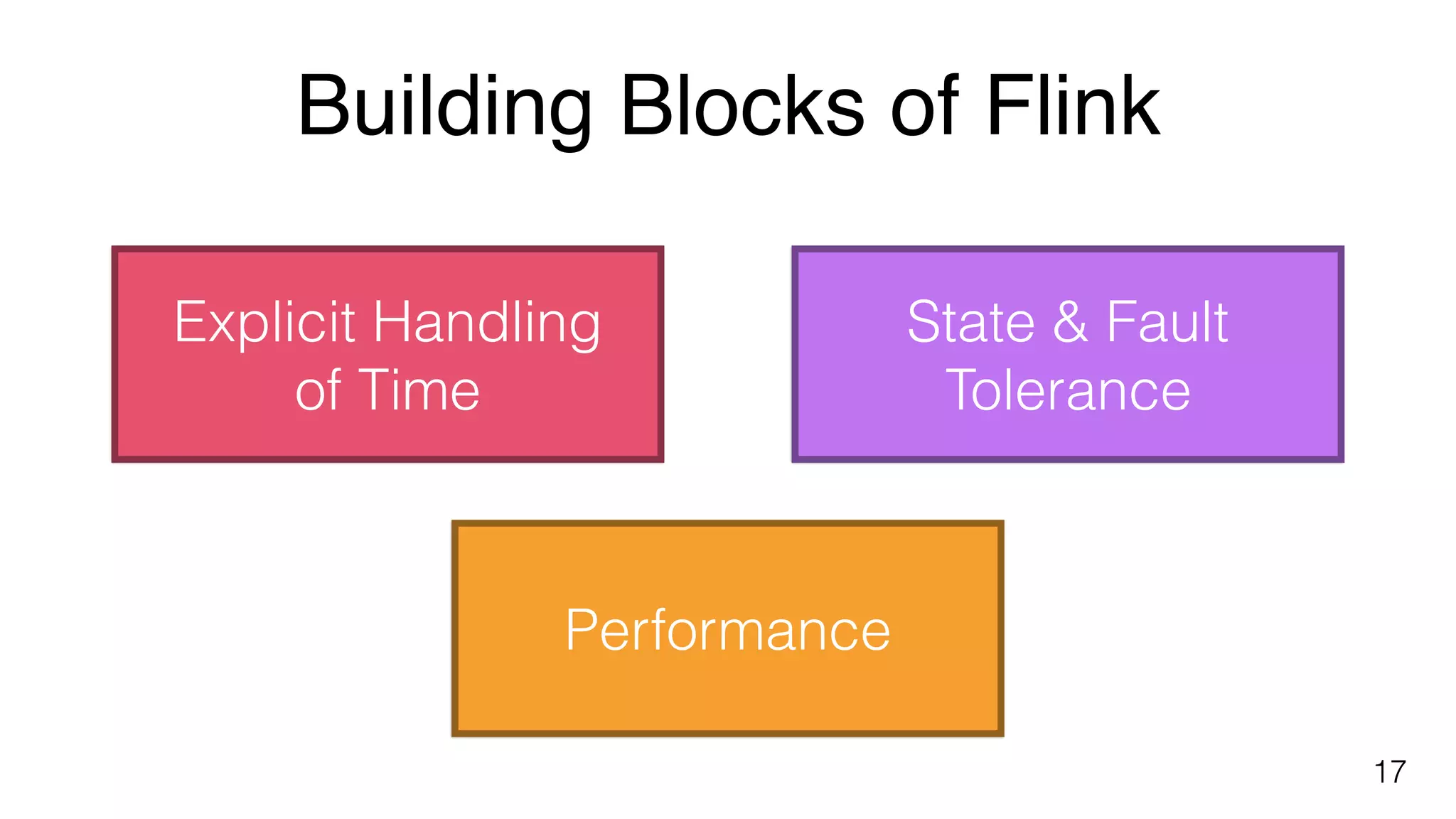
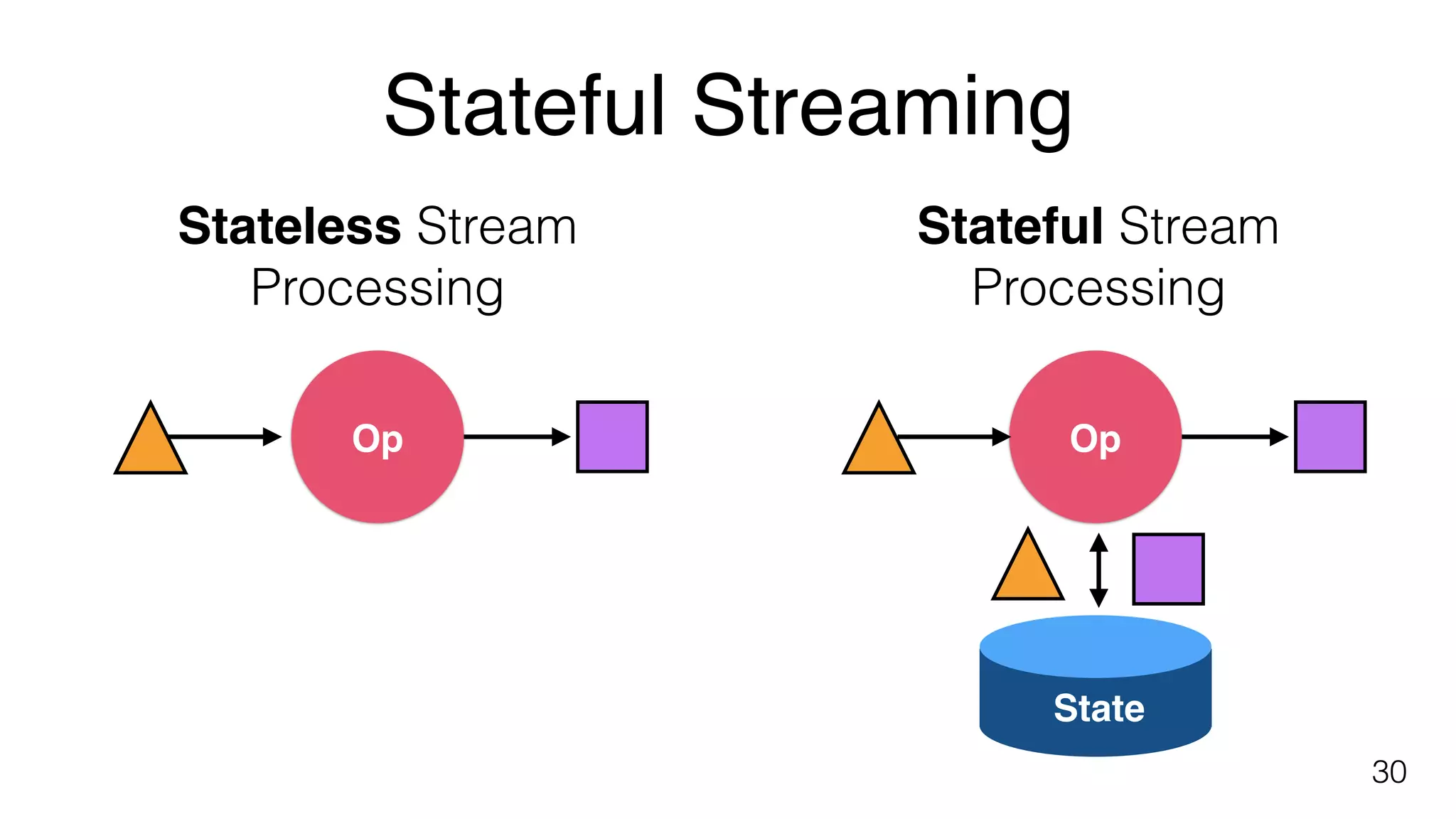
Key components of stream processing in Flink, such as message queues and stream processors that ensure durability and consistent processing.Building blocks of Flink include explicit handling of time, state and fault tolerance, and performance metrics for streaming applications.
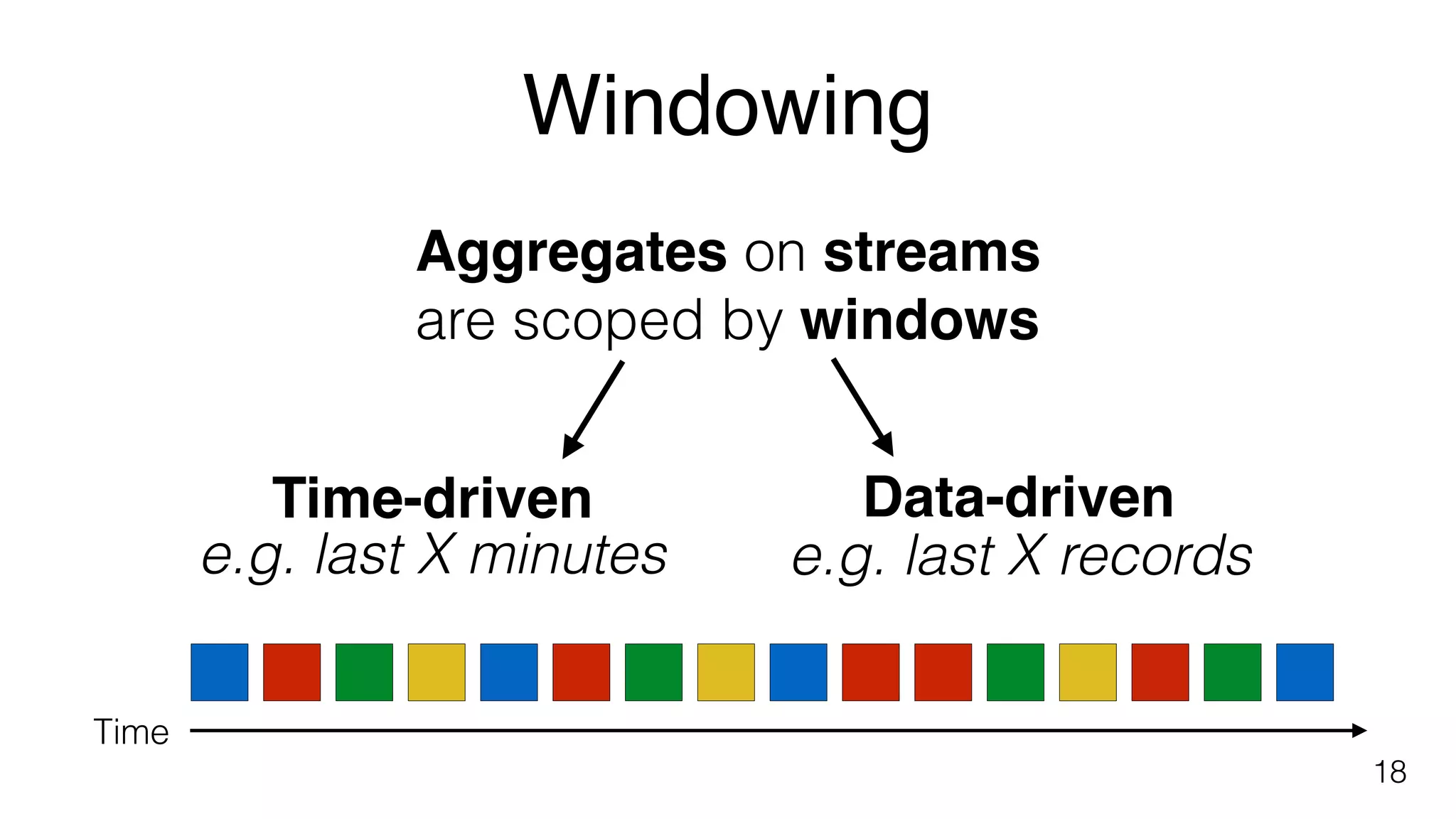
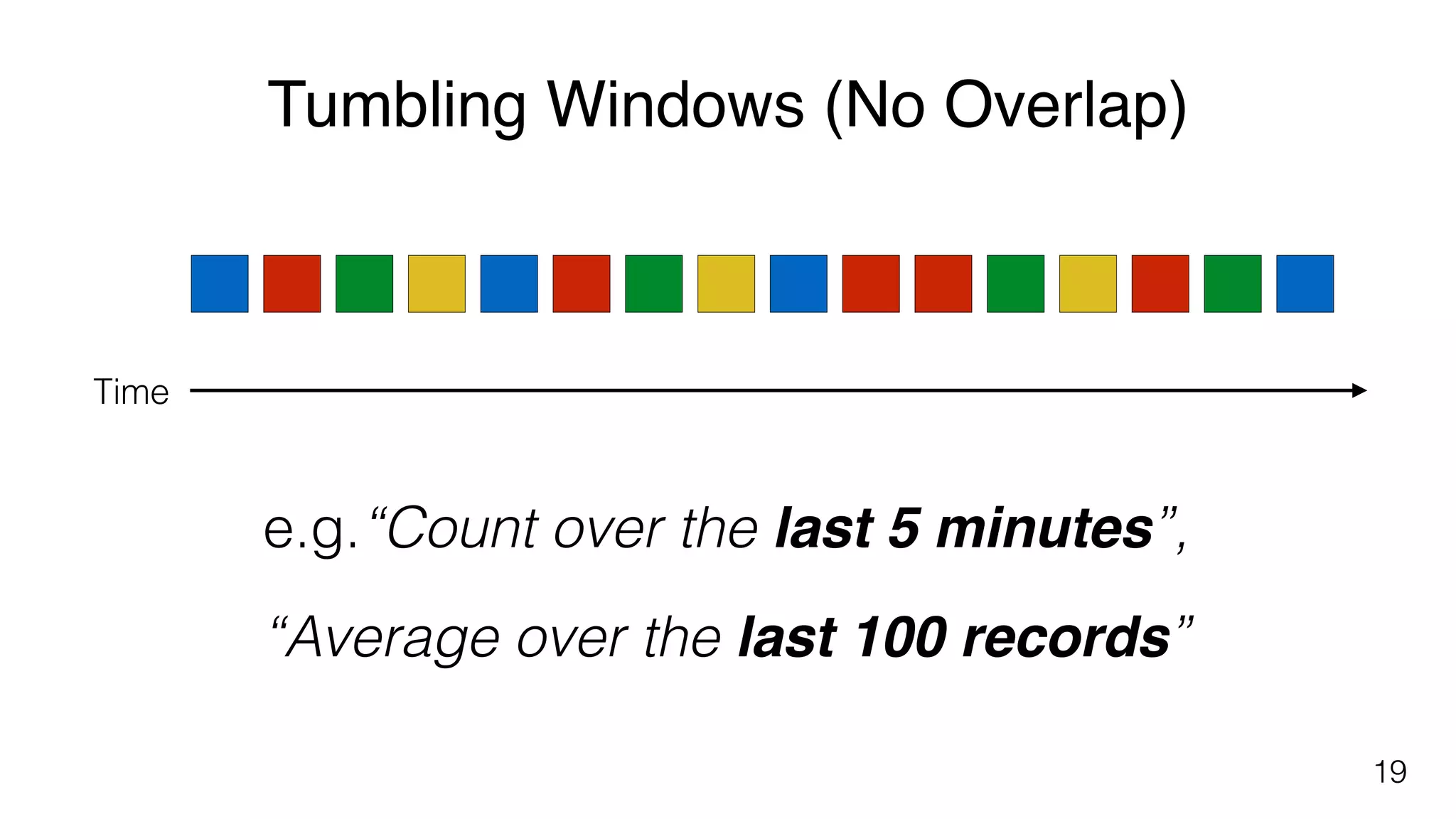
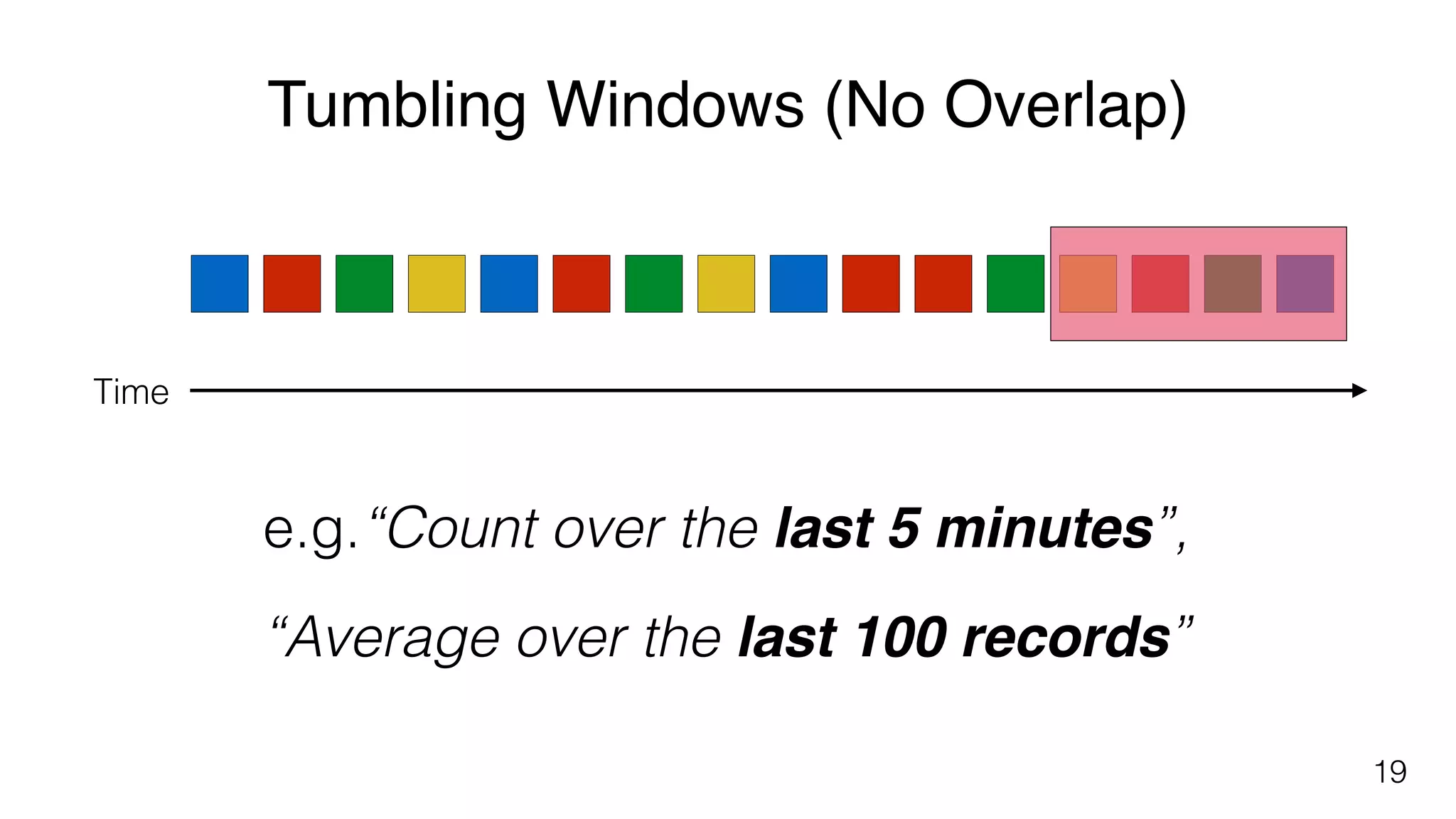
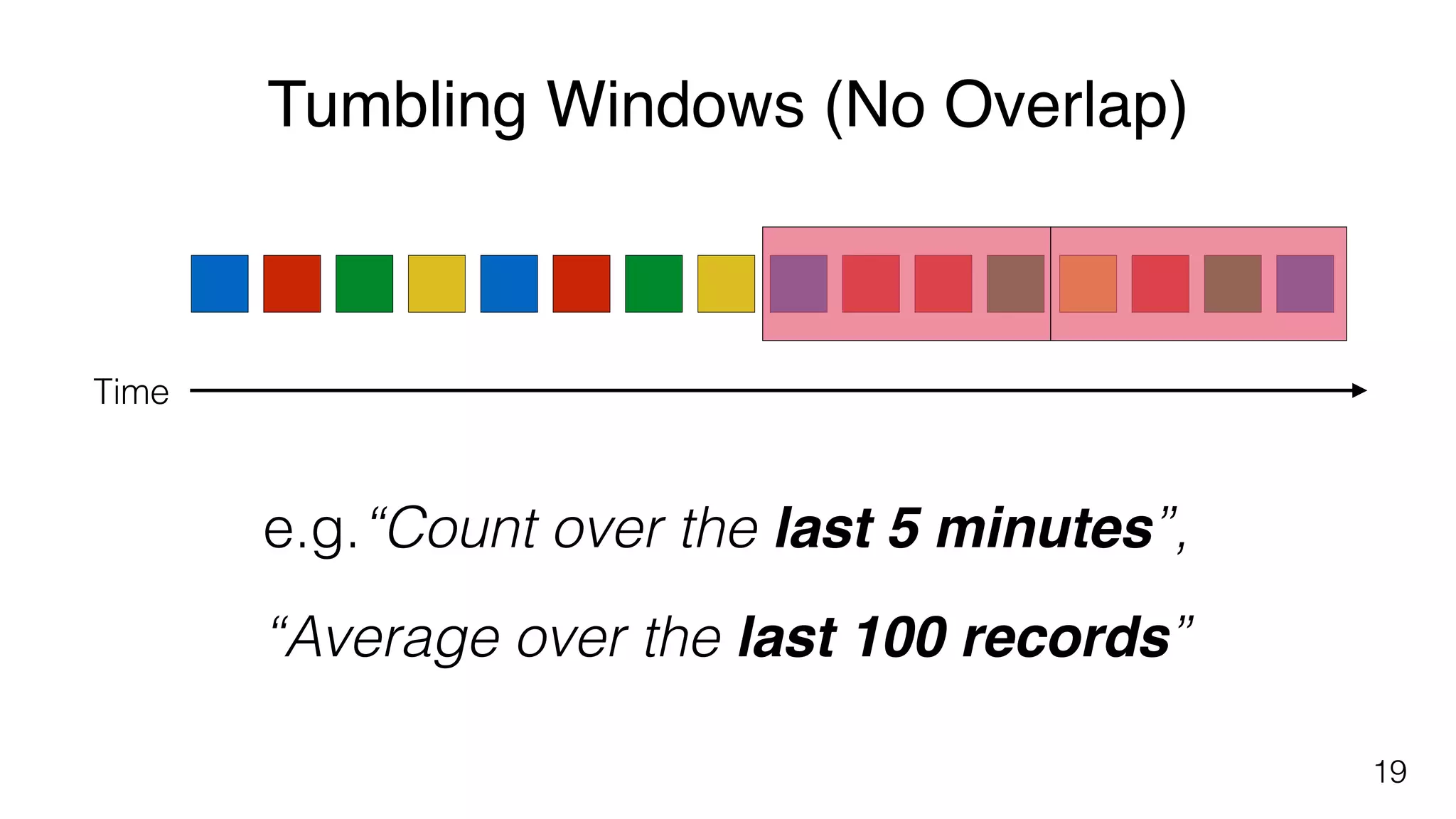
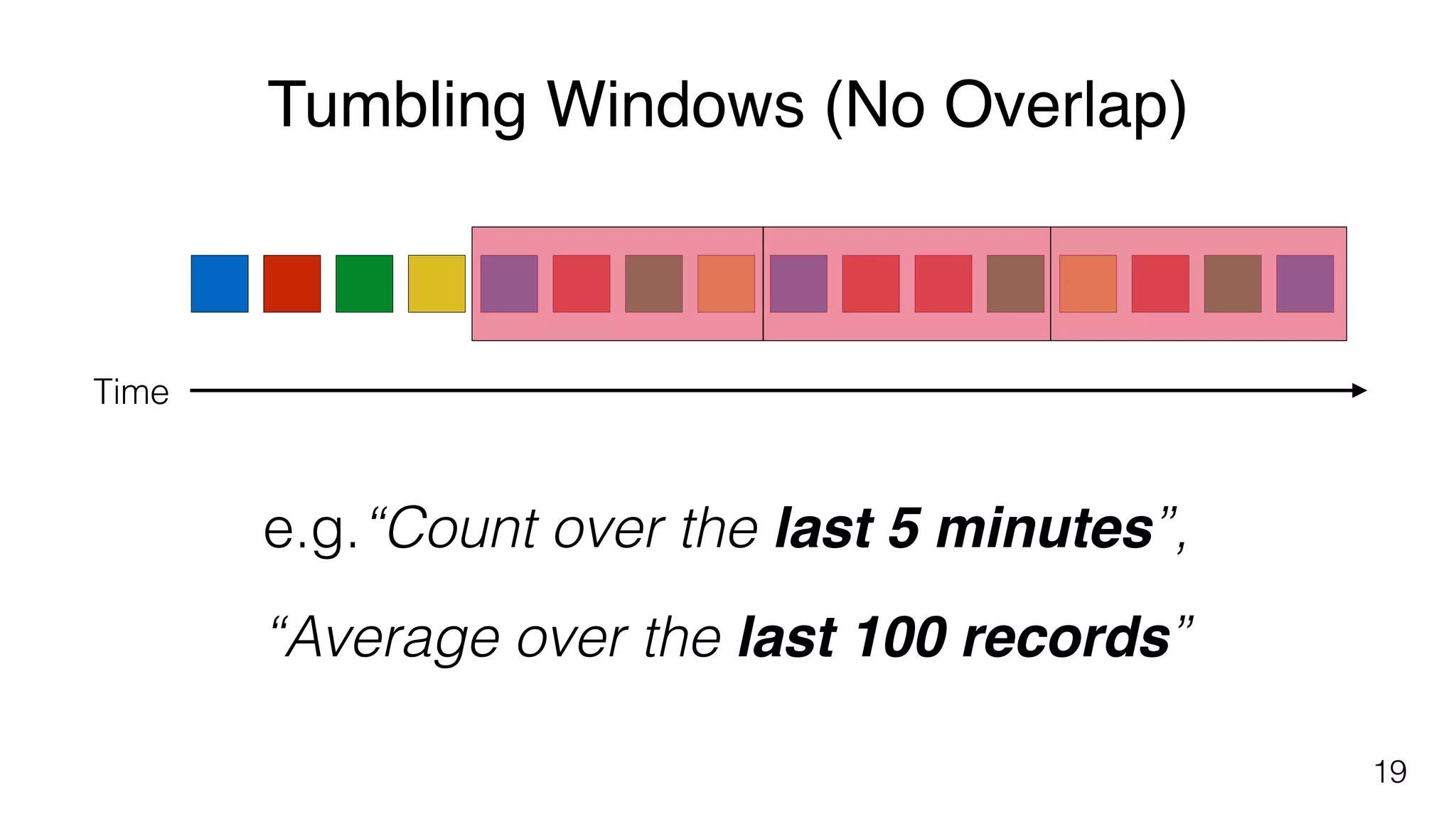
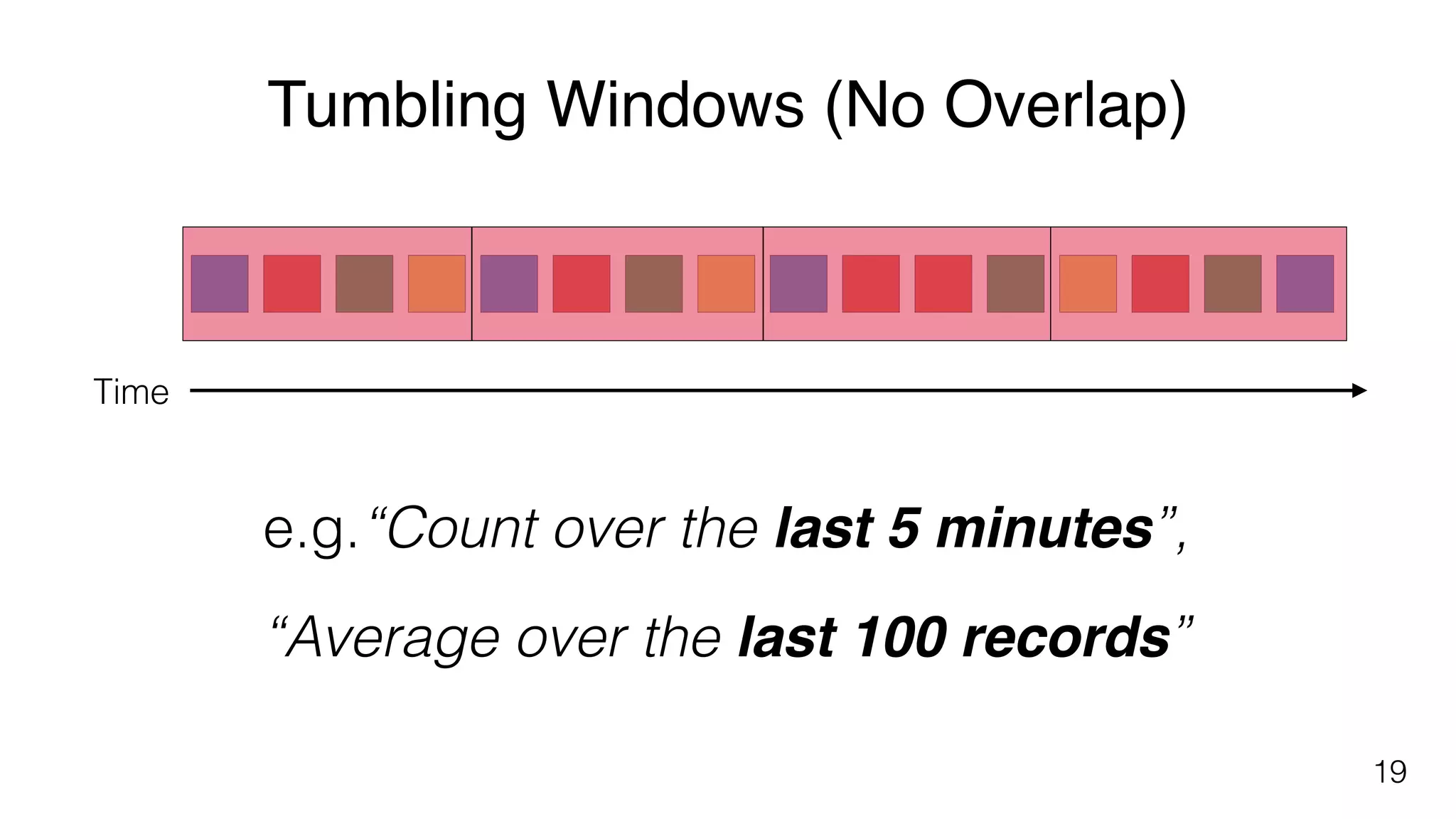
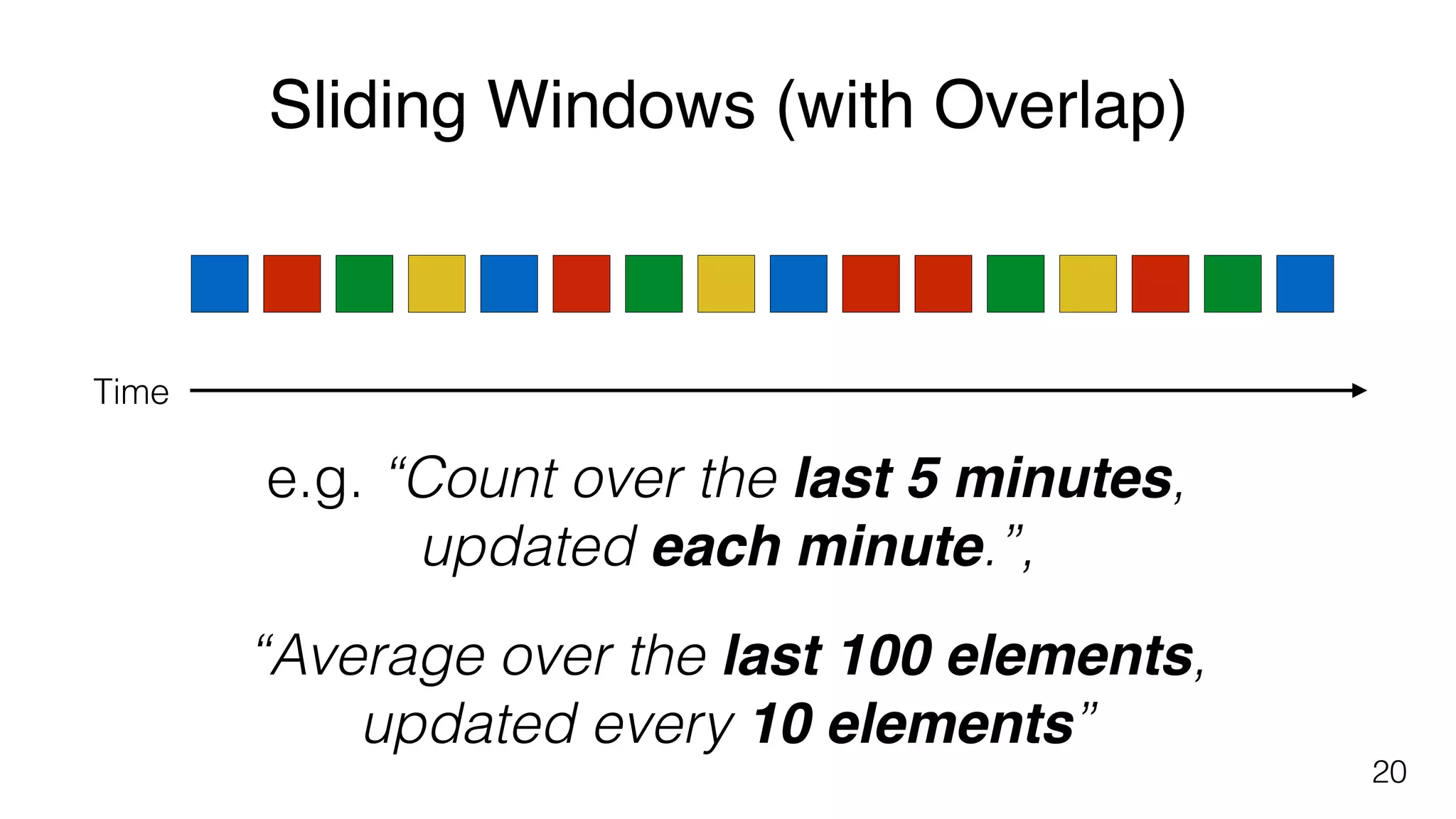
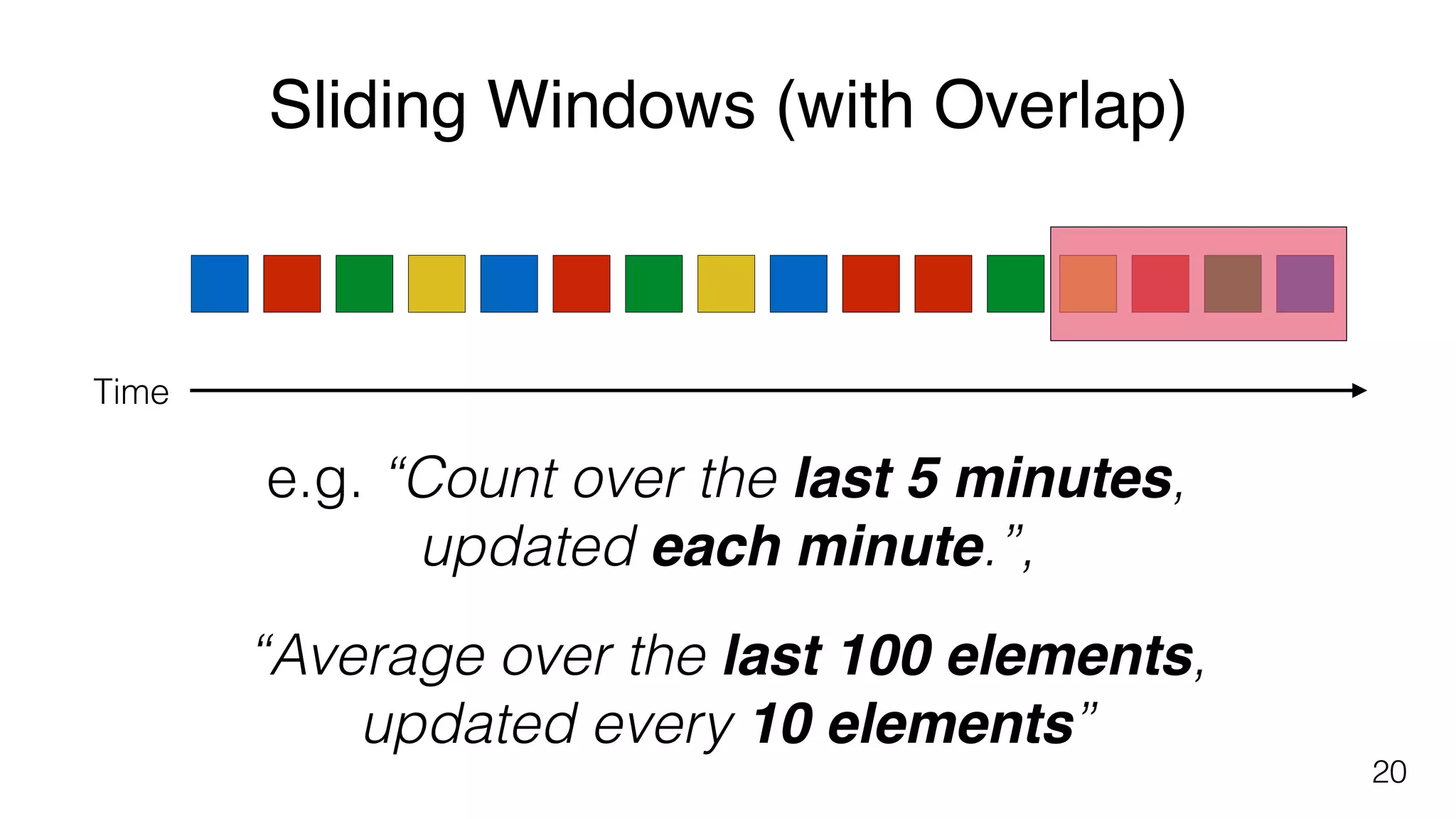
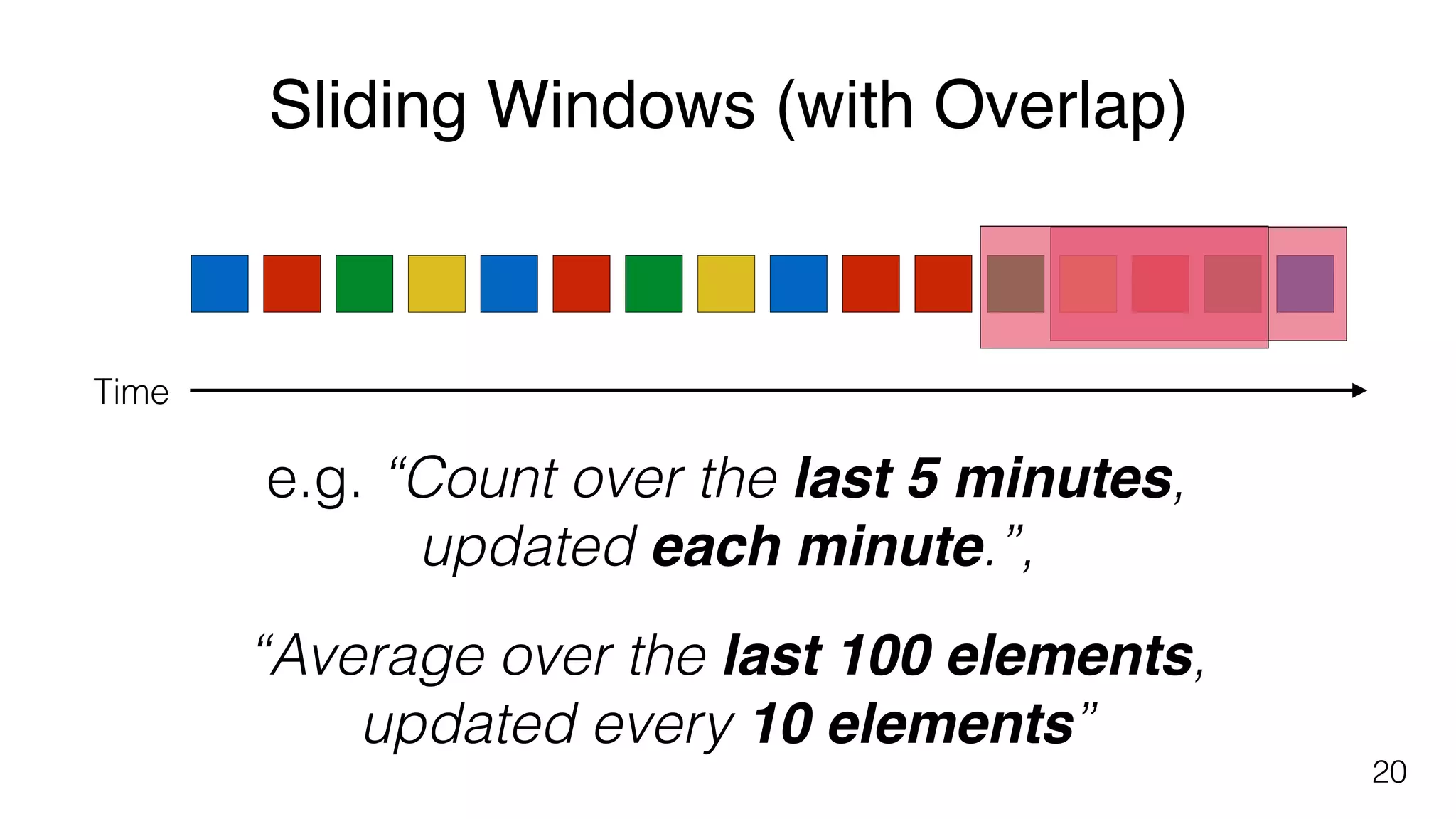
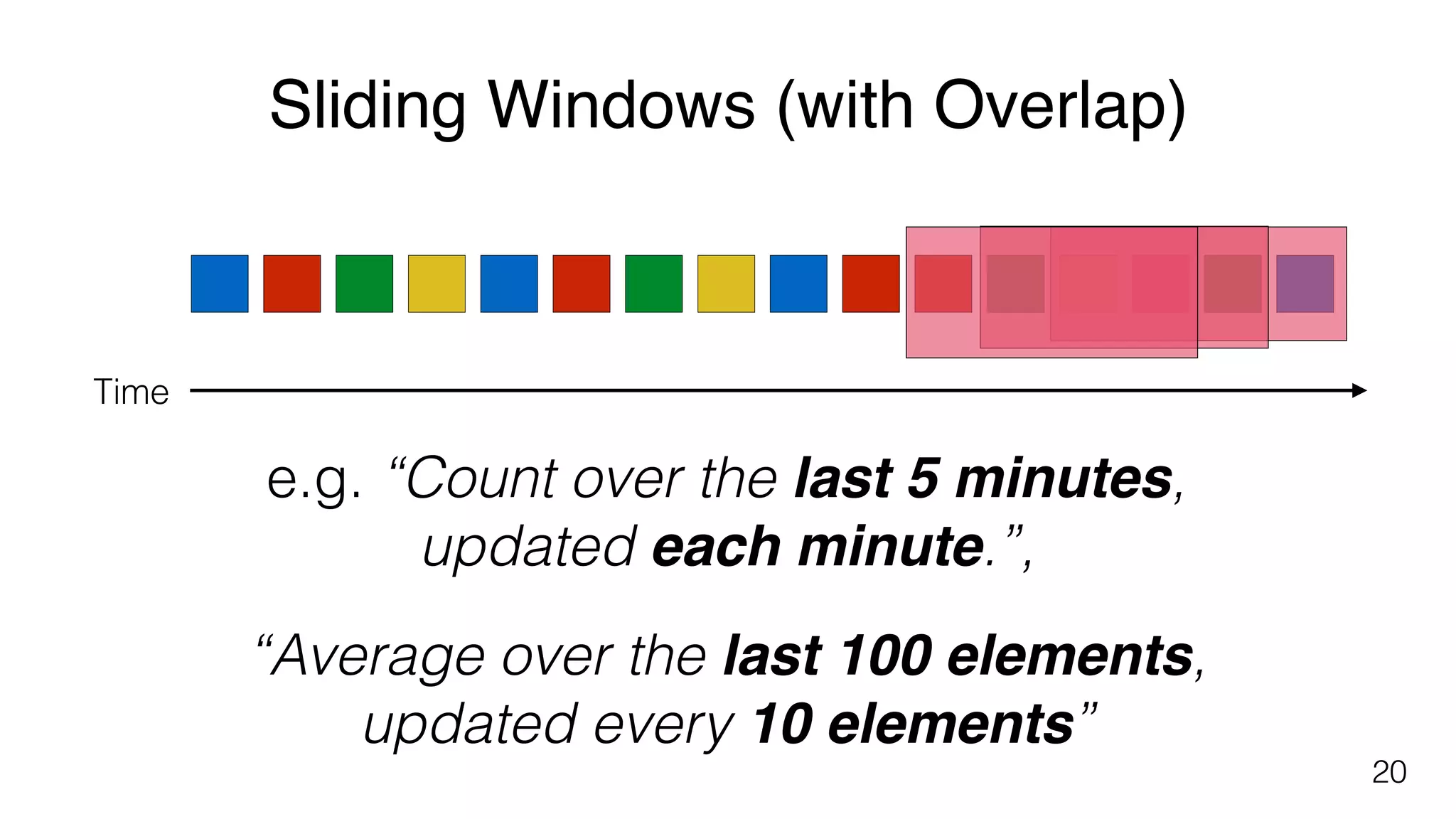
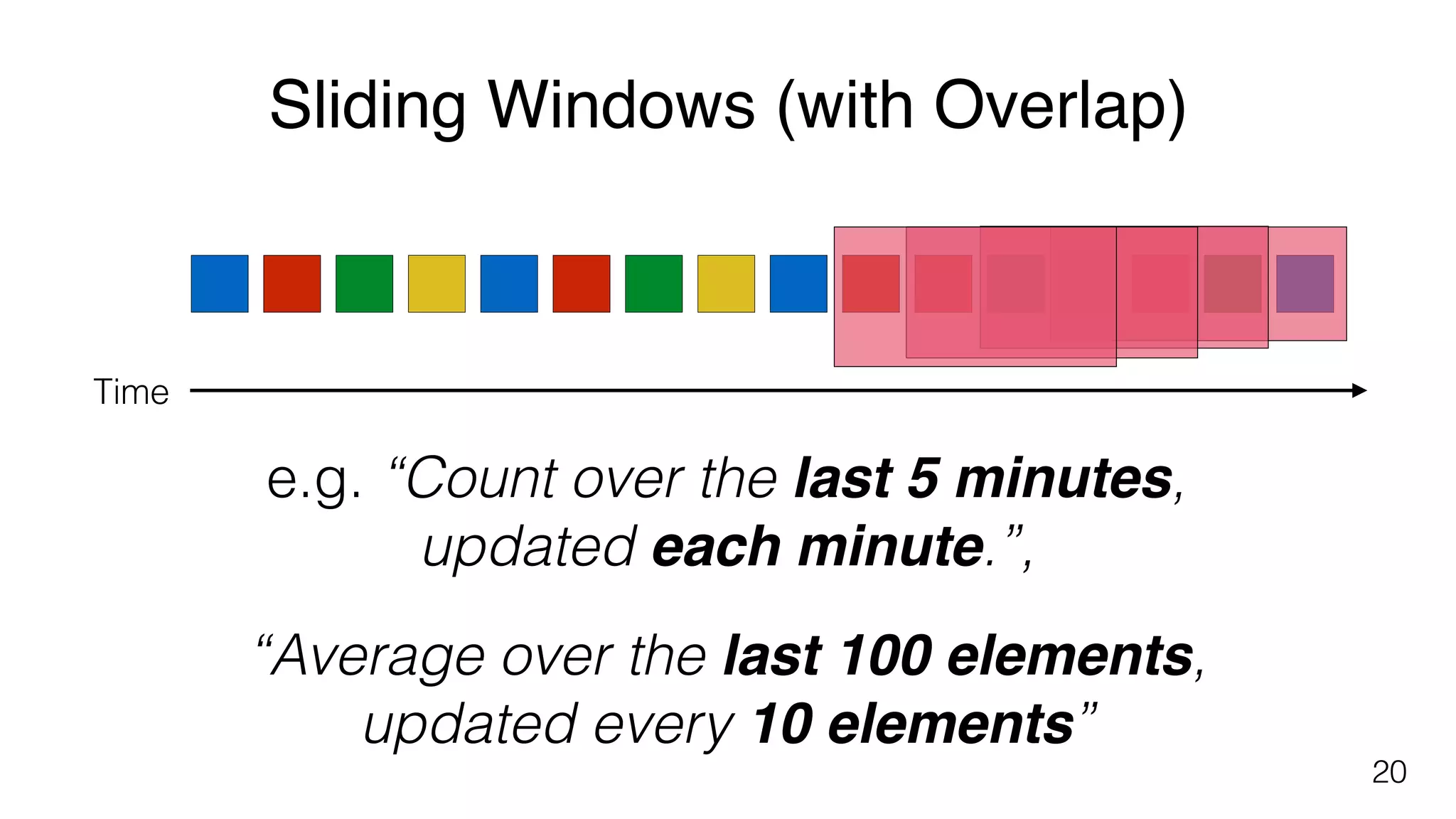
Different windowing techniques in Flink, including tumbling and sliding windows for time-based and data-based aggregations.
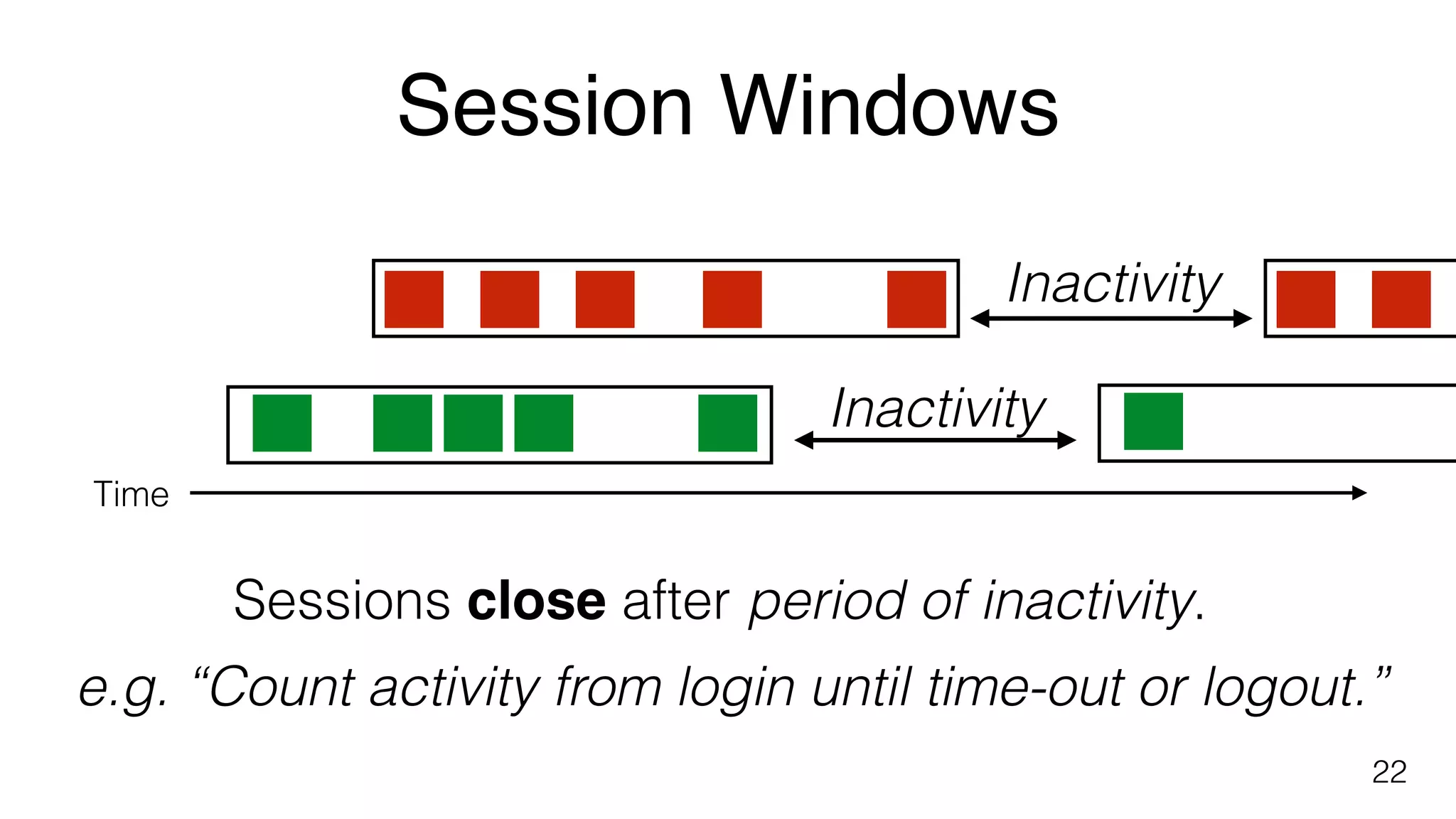
Flink's approach to explicit time handling, including session windows that close after periods of inactivity.
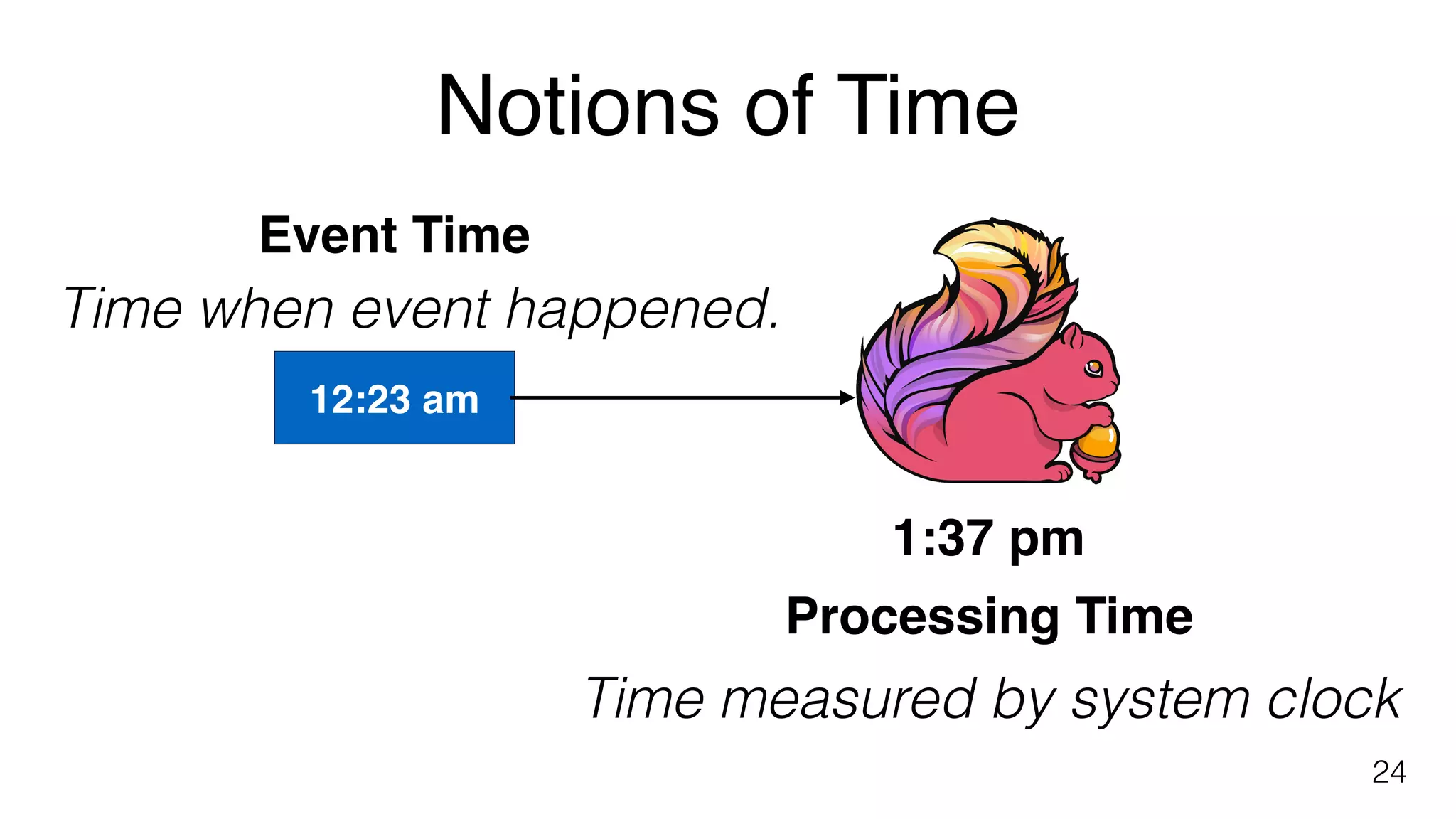
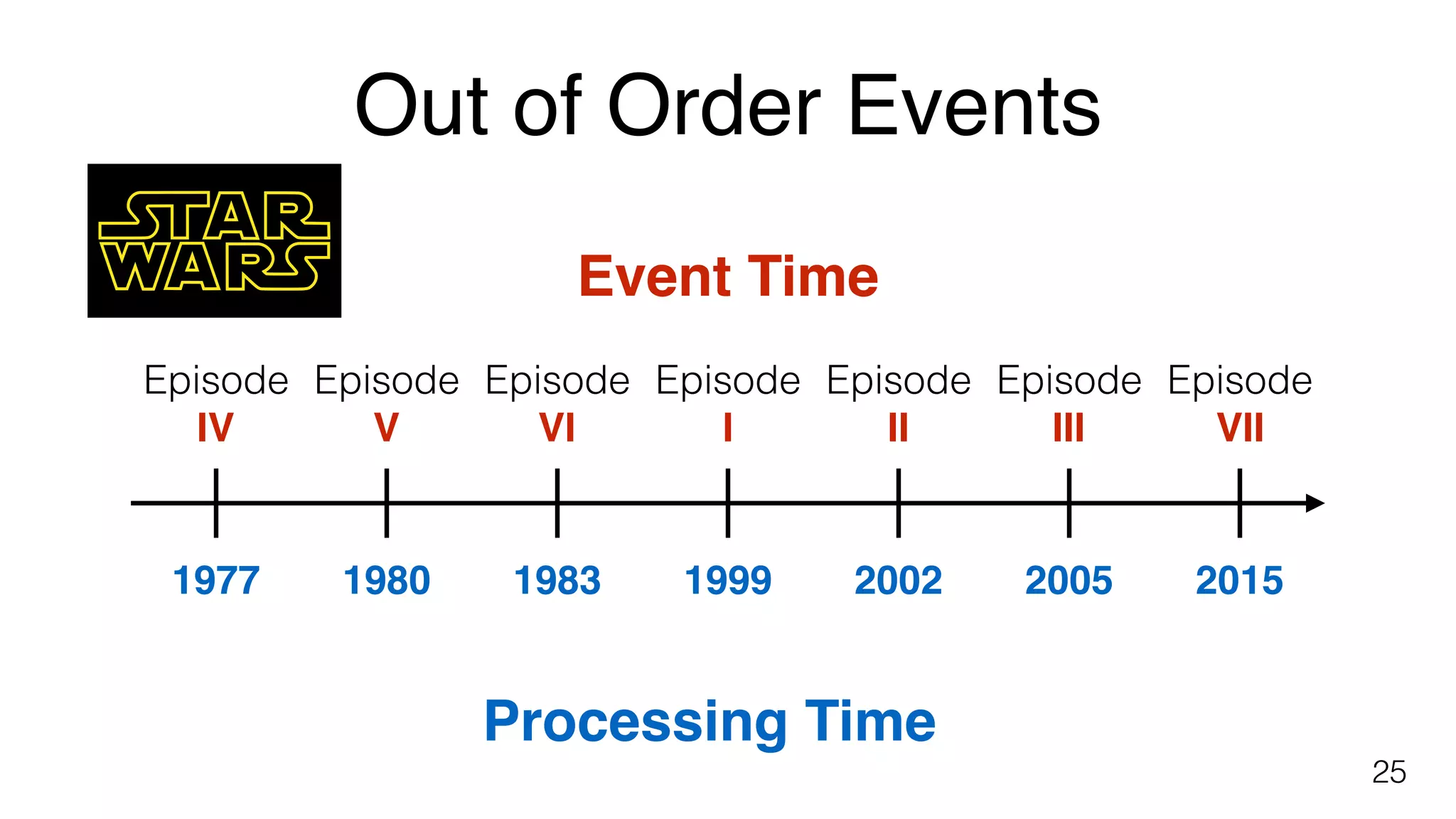
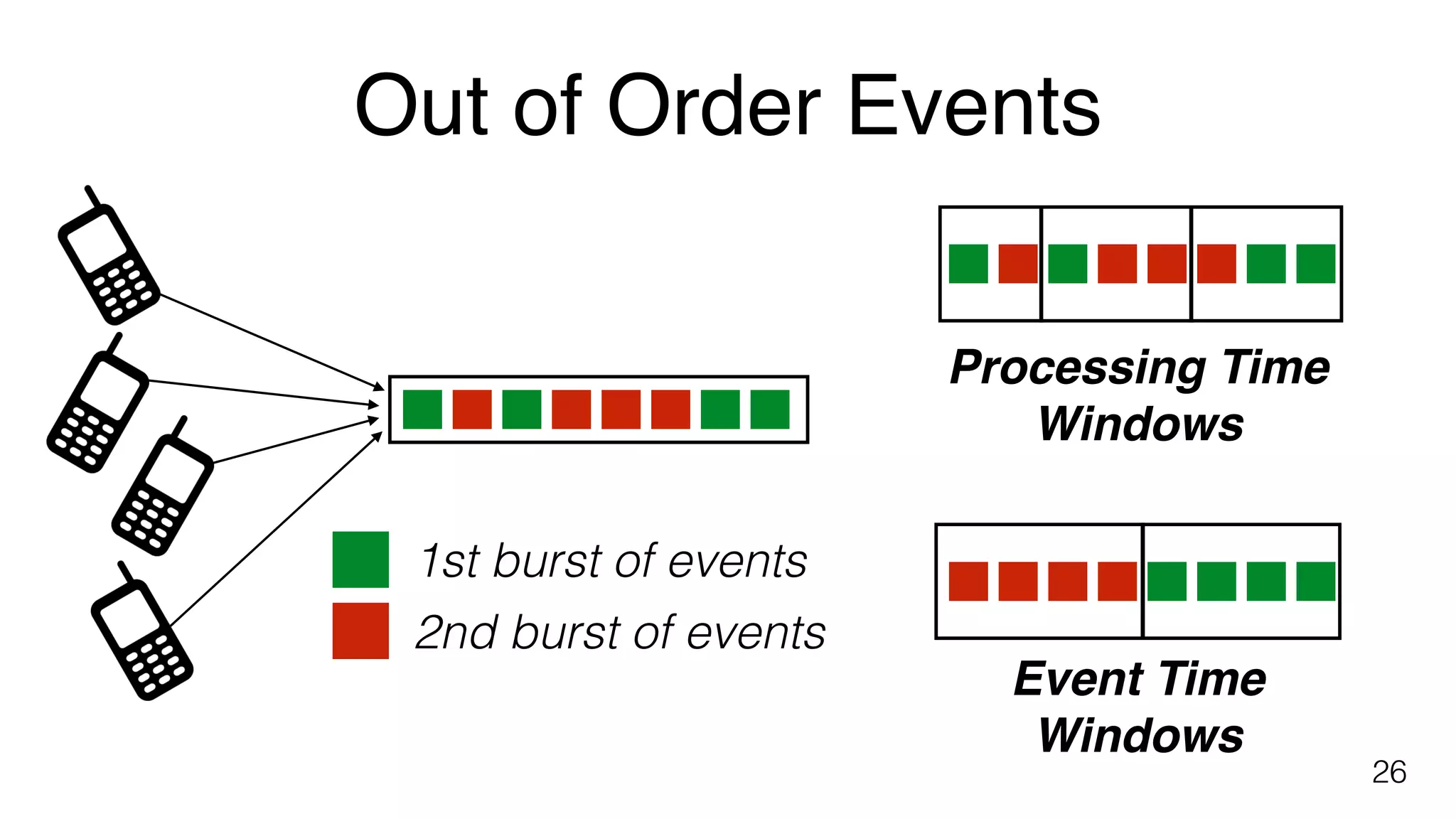
Differentiates between event time and processing time in data streams and the handling of out-of-order events.
Explains processing semantics in Flink emphasizing 'at-least once', 'exactly once', and their implications for state consistency.
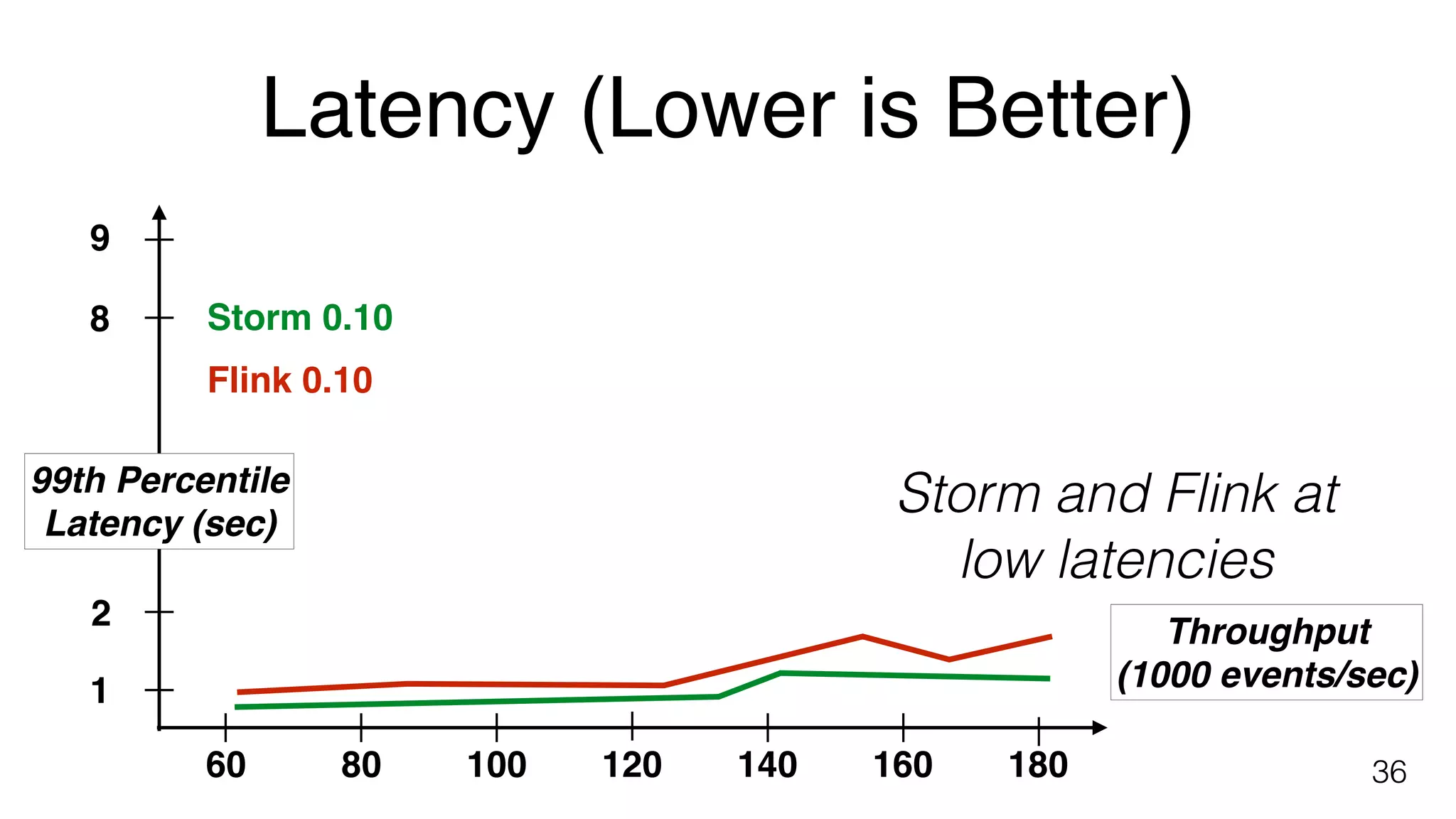
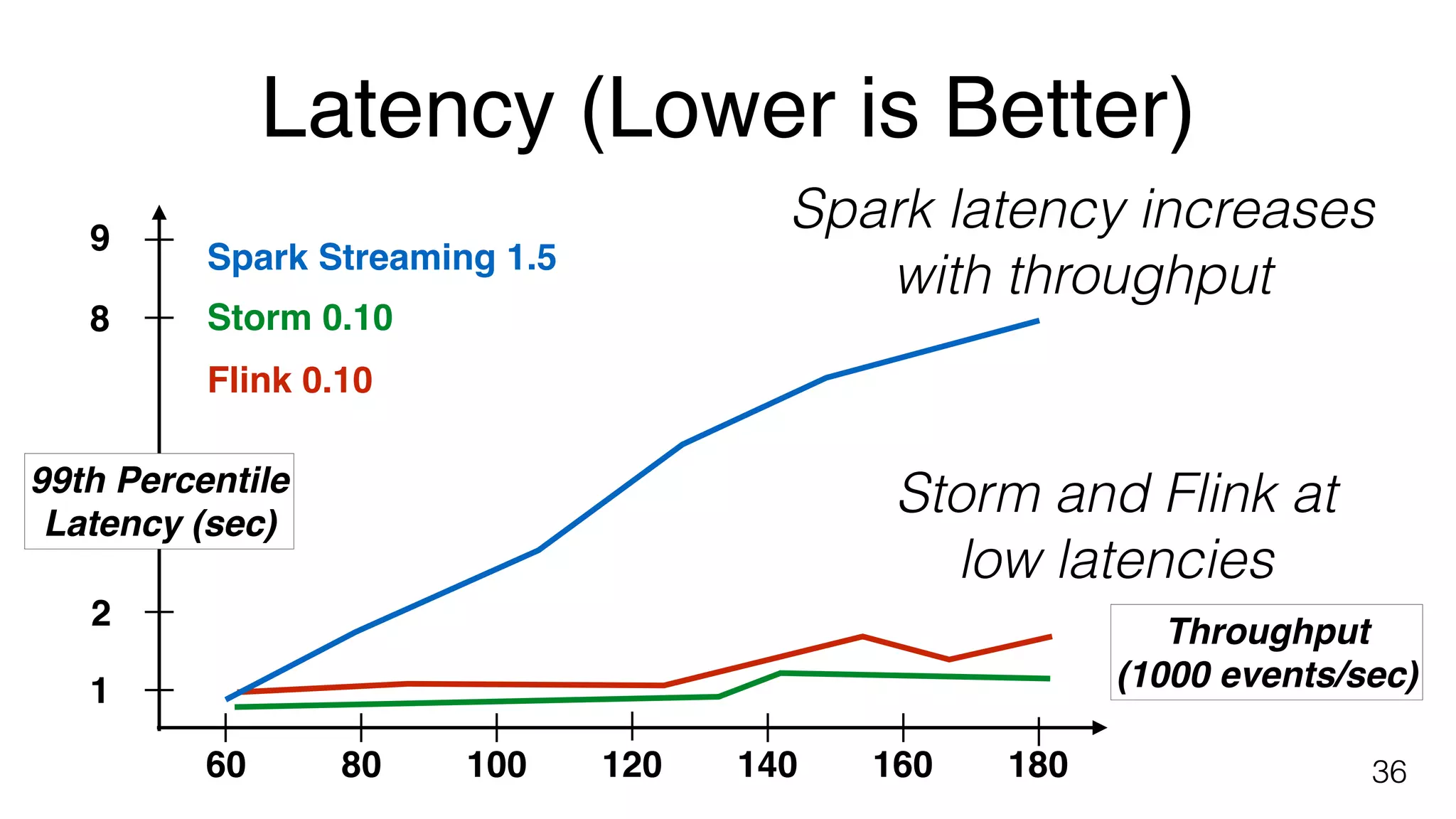
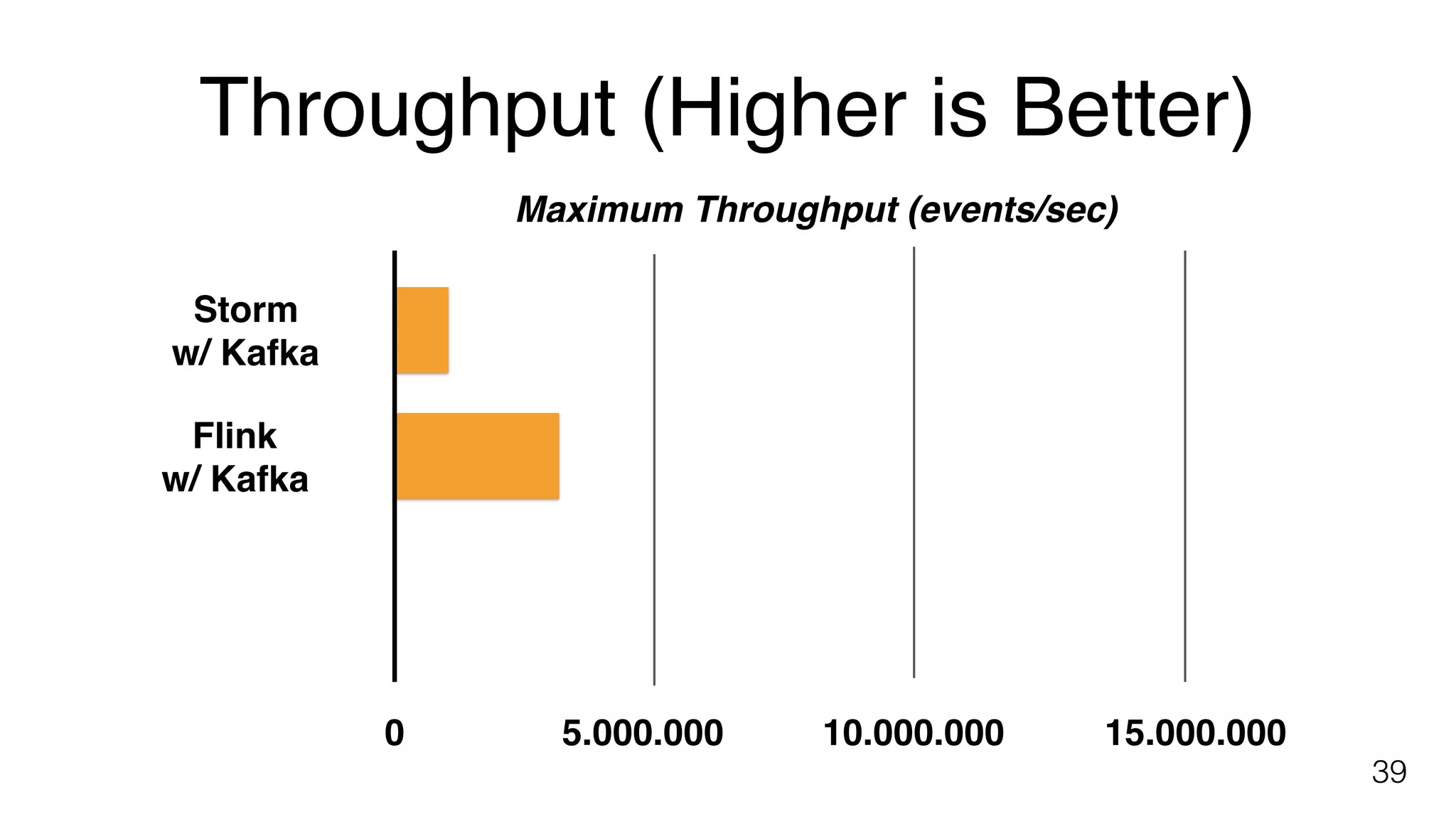
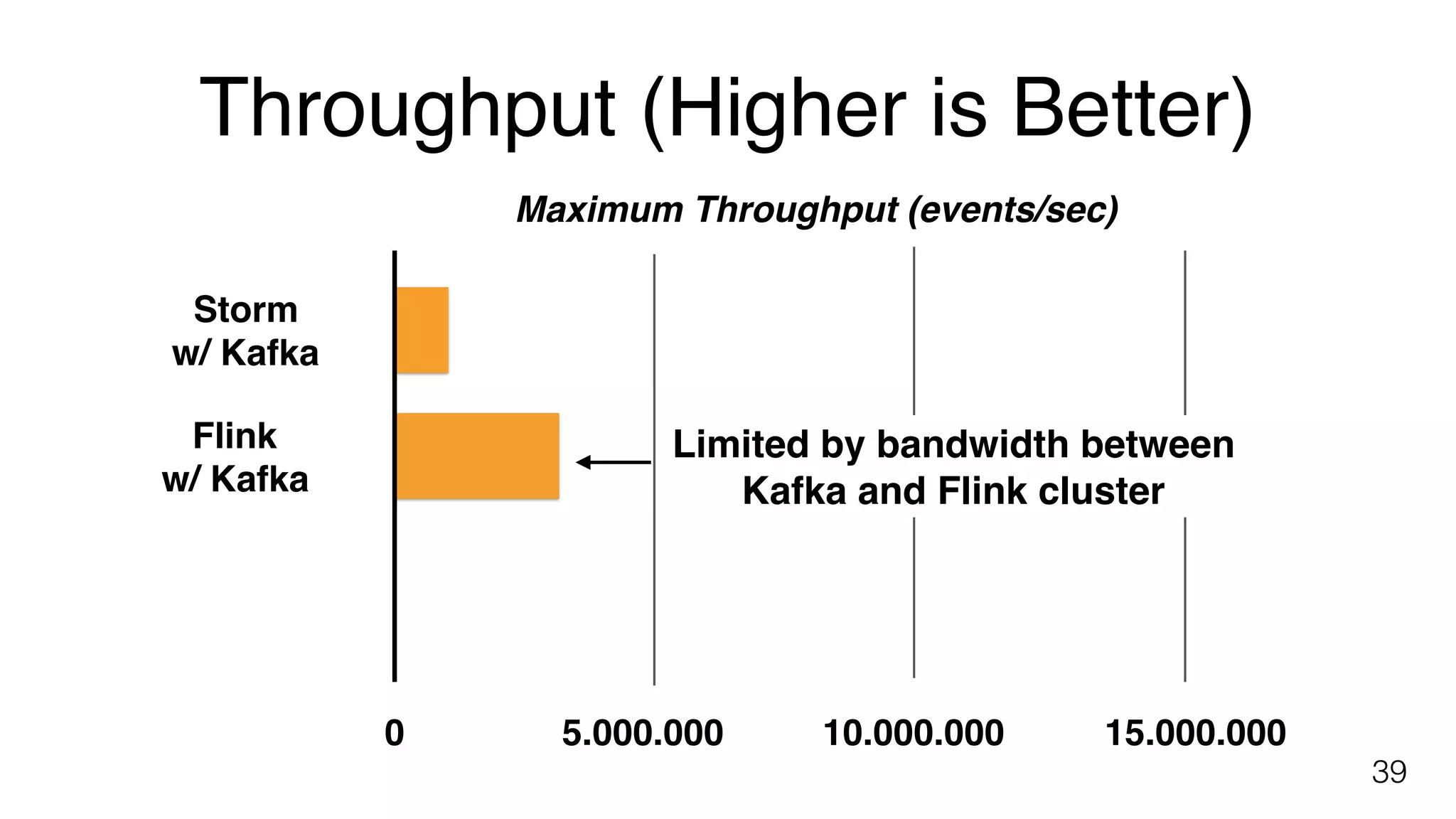
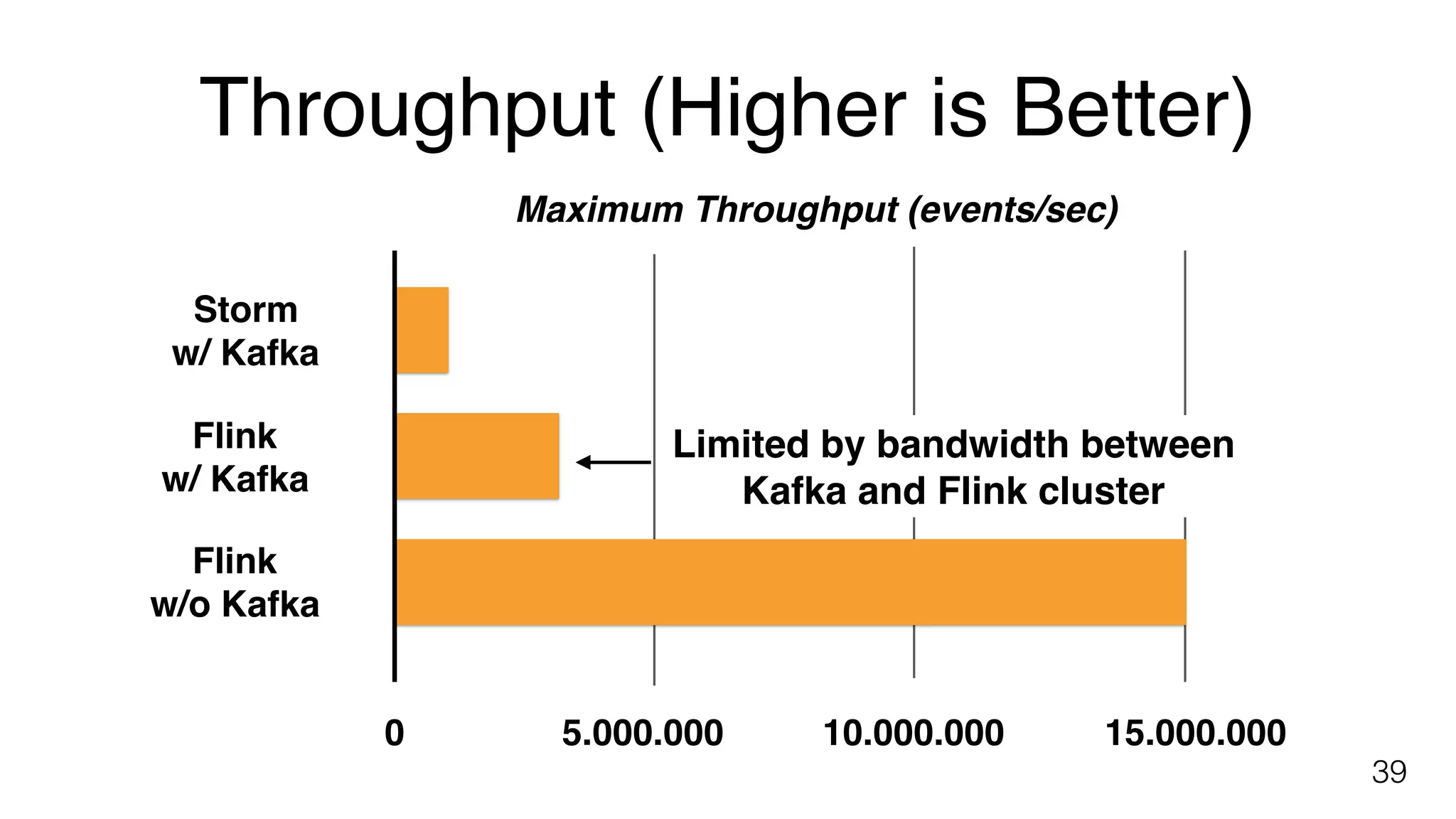
Yahoo! benchmark results comparing Flink, Storm, and Spark Streaming focused on end-to-end latency and throughput.
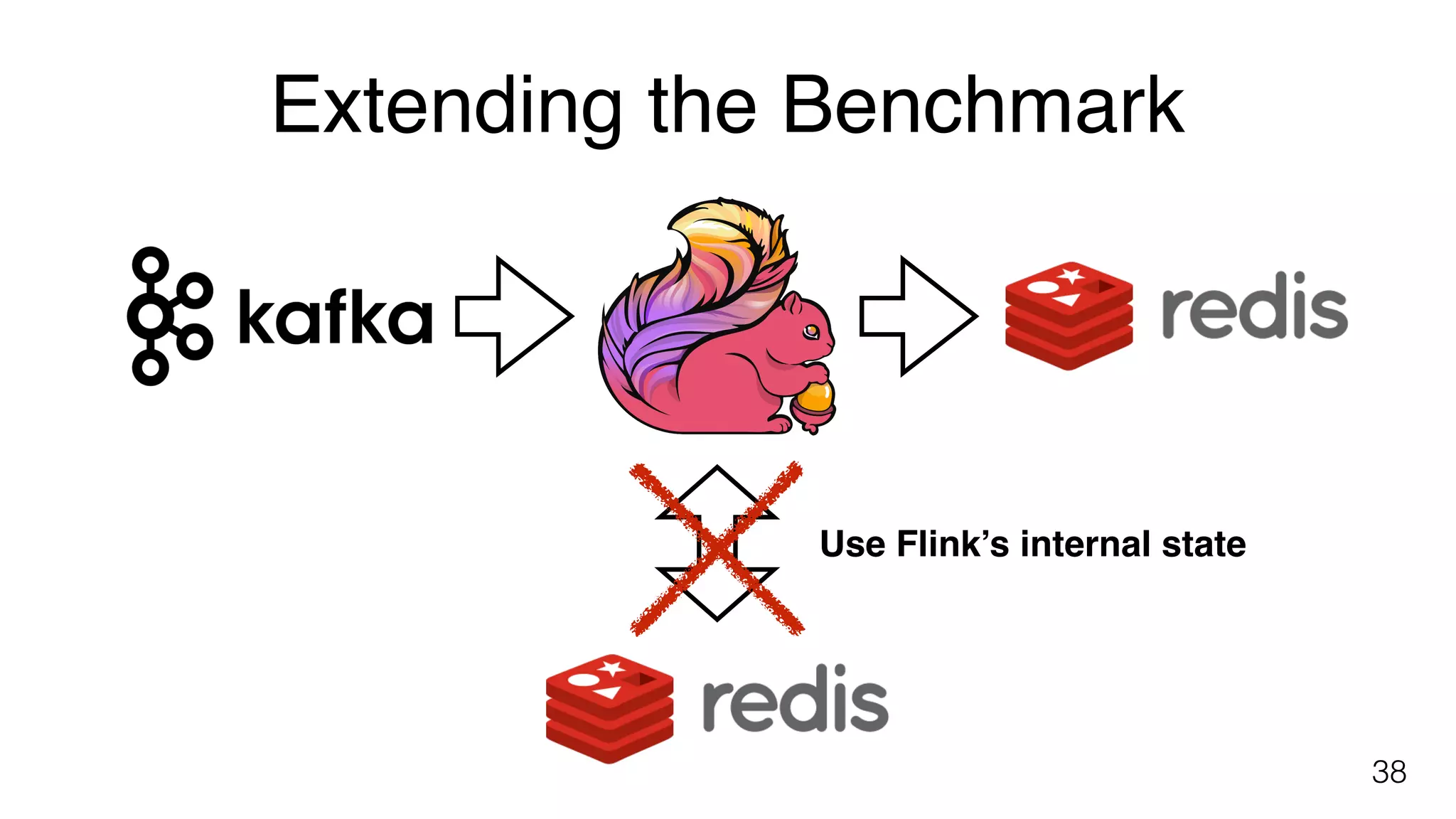
Suggestions on extending existing benchmarks to account for high write throughput and Flink's fault tolerance features.
Highlights advantages of Flink in stream processing for continuous data applications and the importance of framework choice.
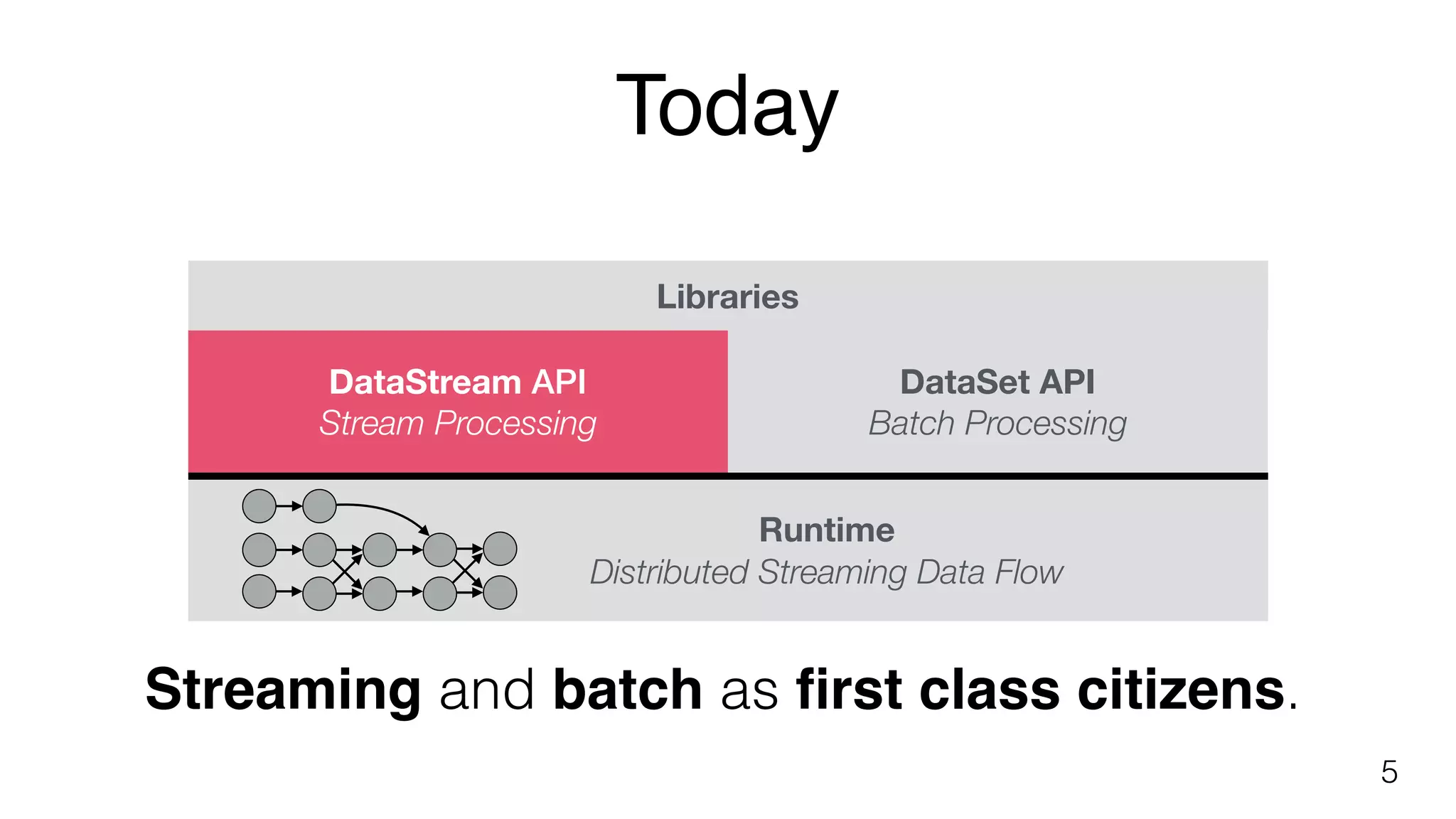
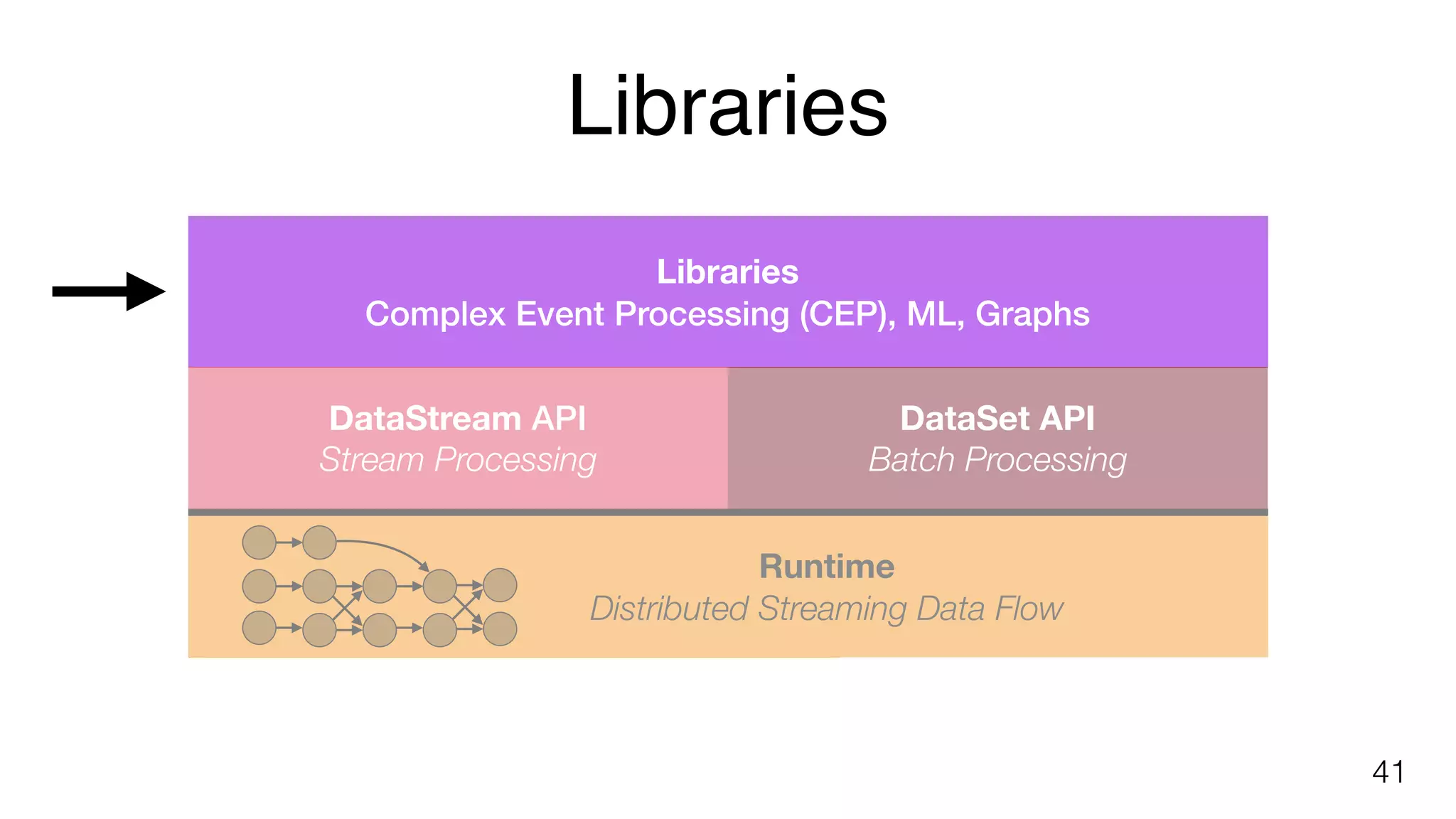
Describes Flink libraries for complex event processing and various APIs for stream and batch processing.
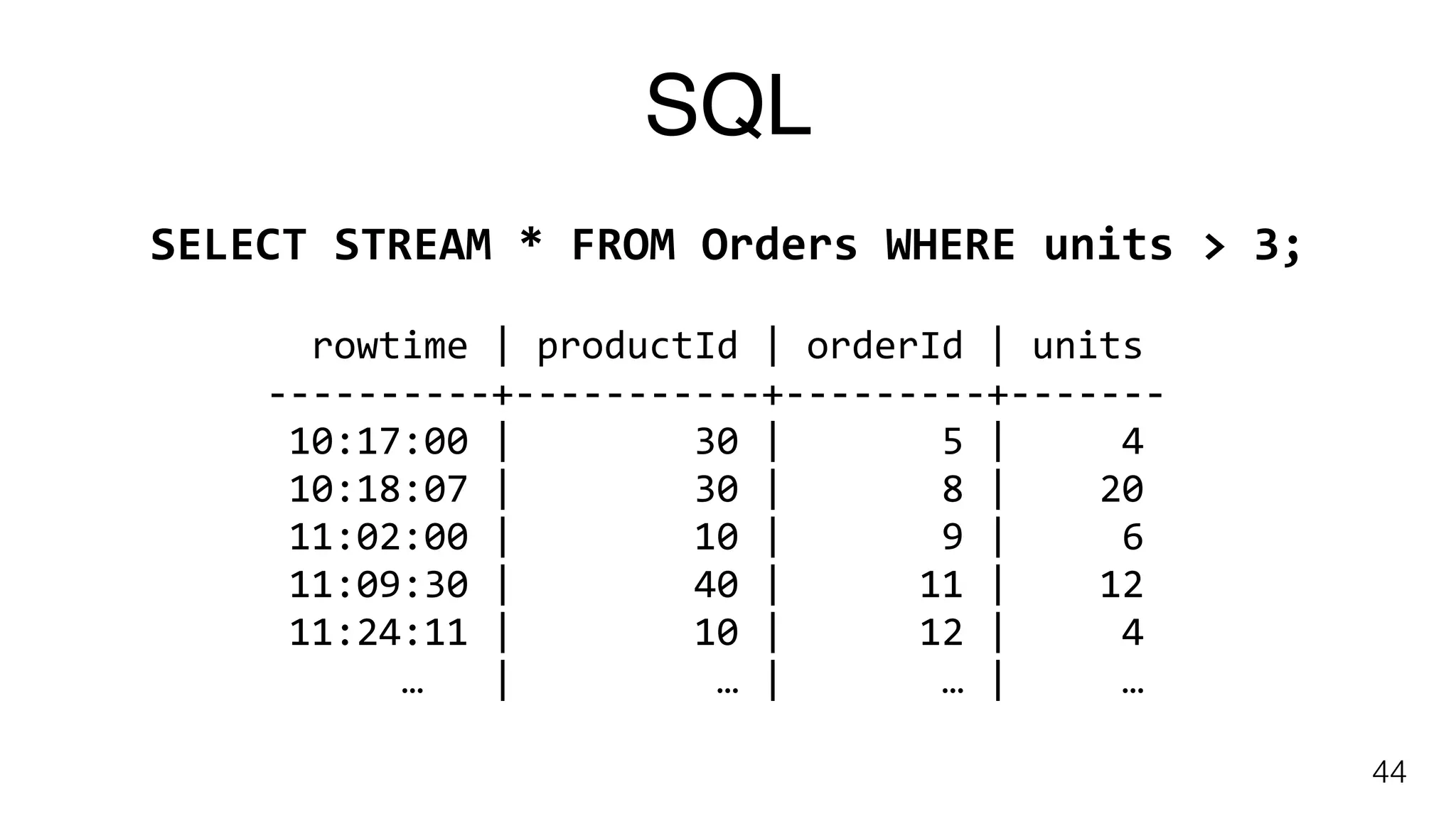
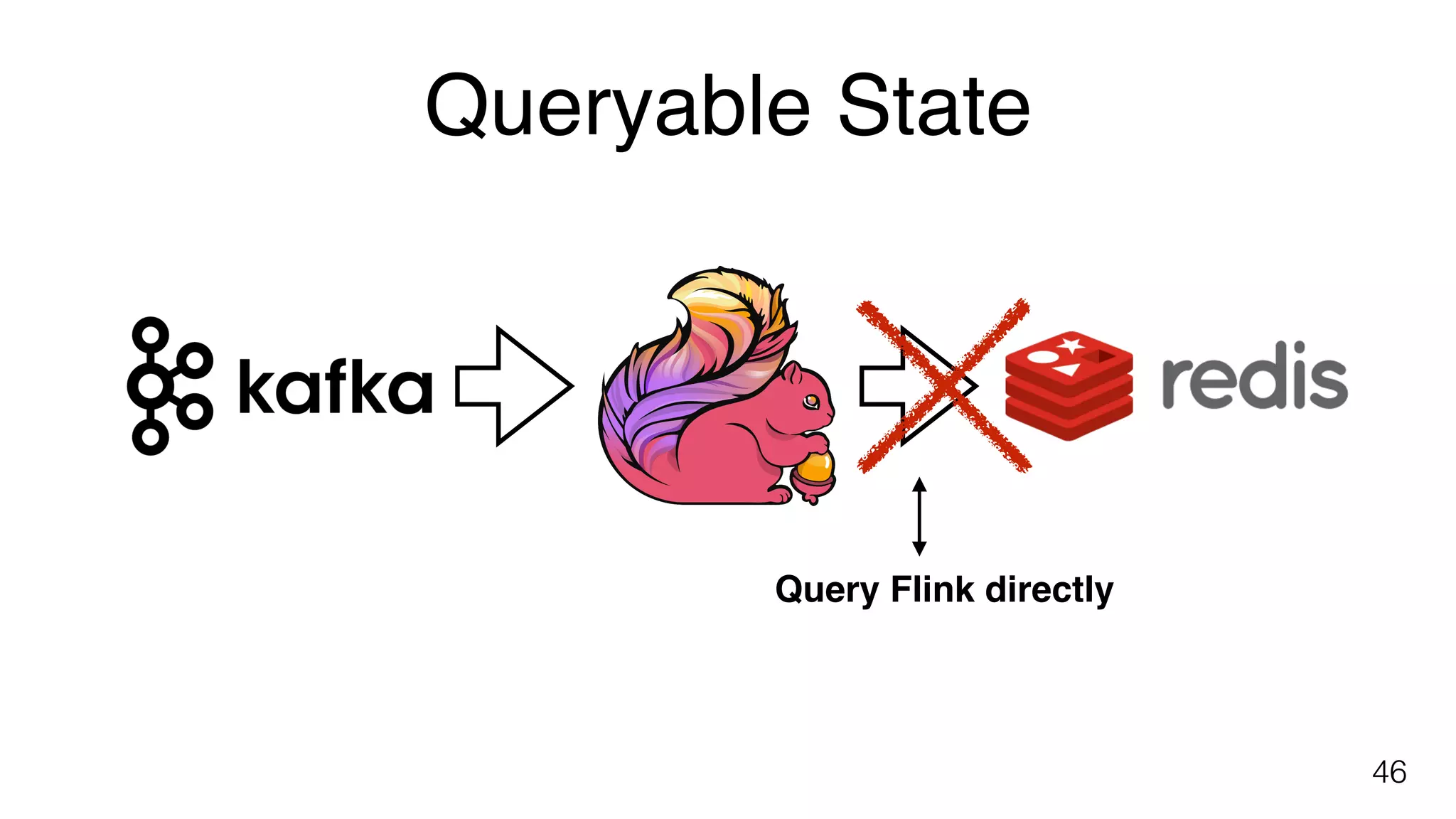
Planned features for Flink including SQL support, dynamic scaling, and queryable state for improved resource management.
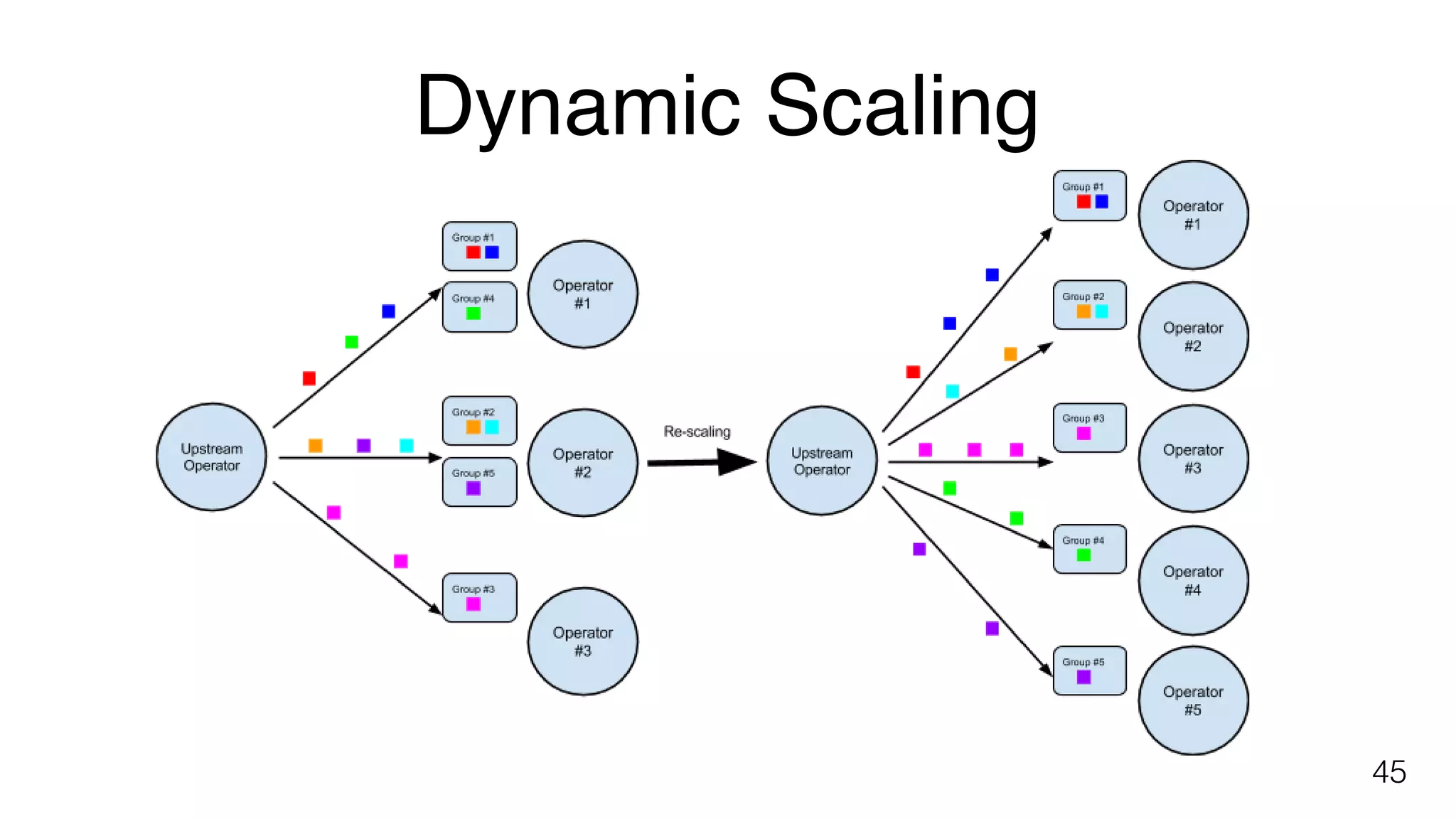
Details on dynamic scaling in Flink jobs and the capability to query data directly within the Flink processing environment.
Encourages collaboration and engagement with the Flink community through blogs and social media.