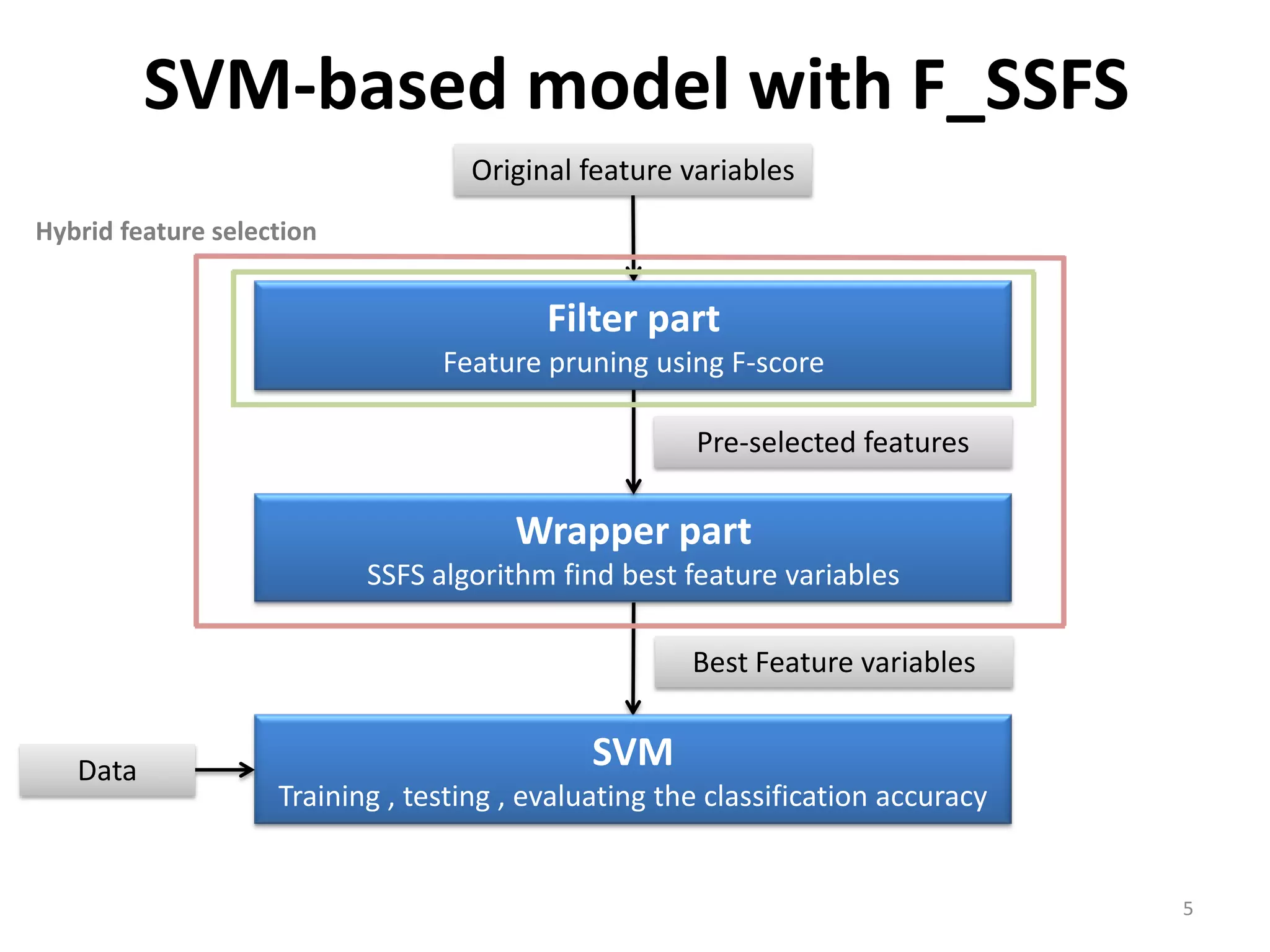
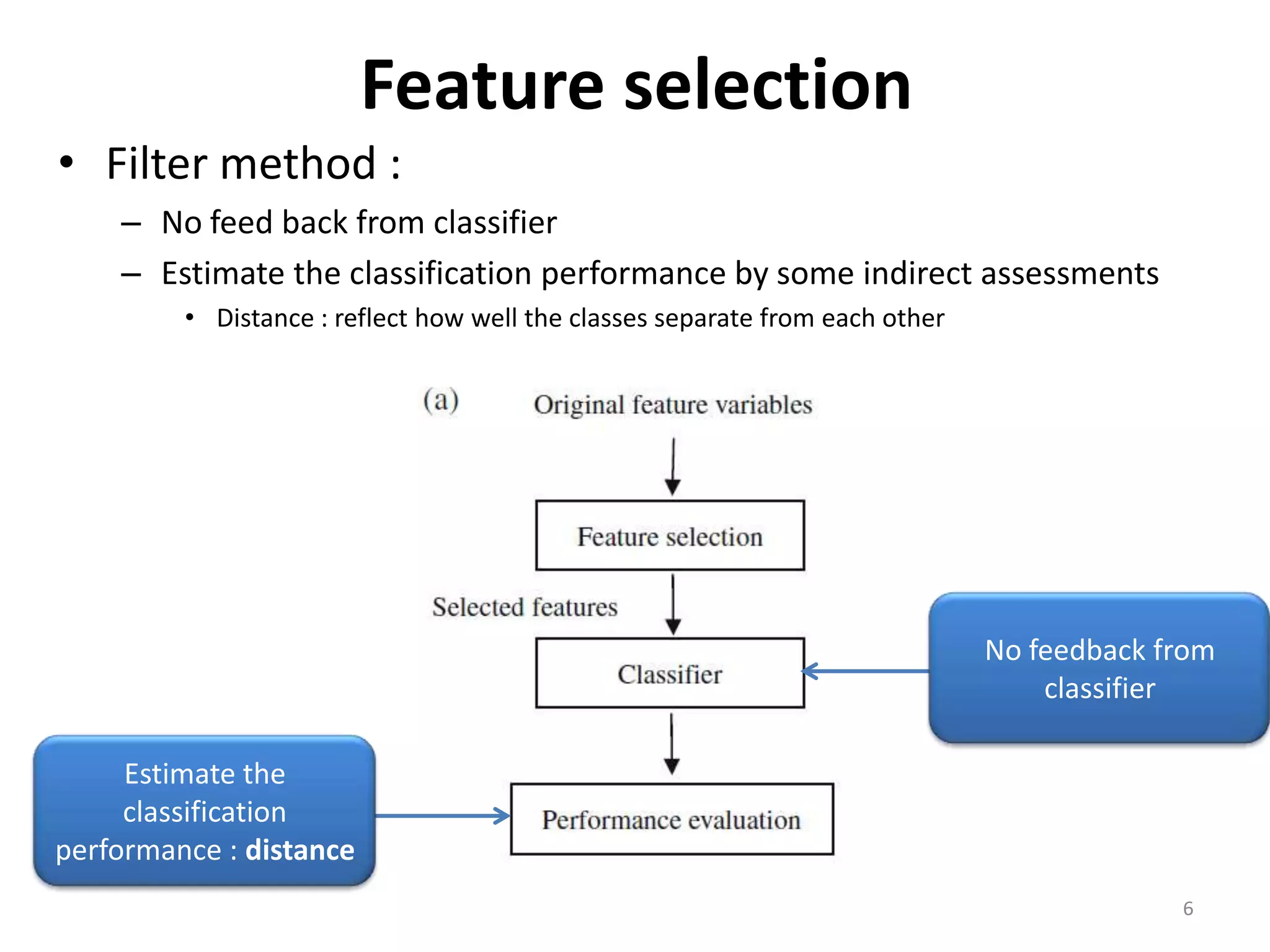
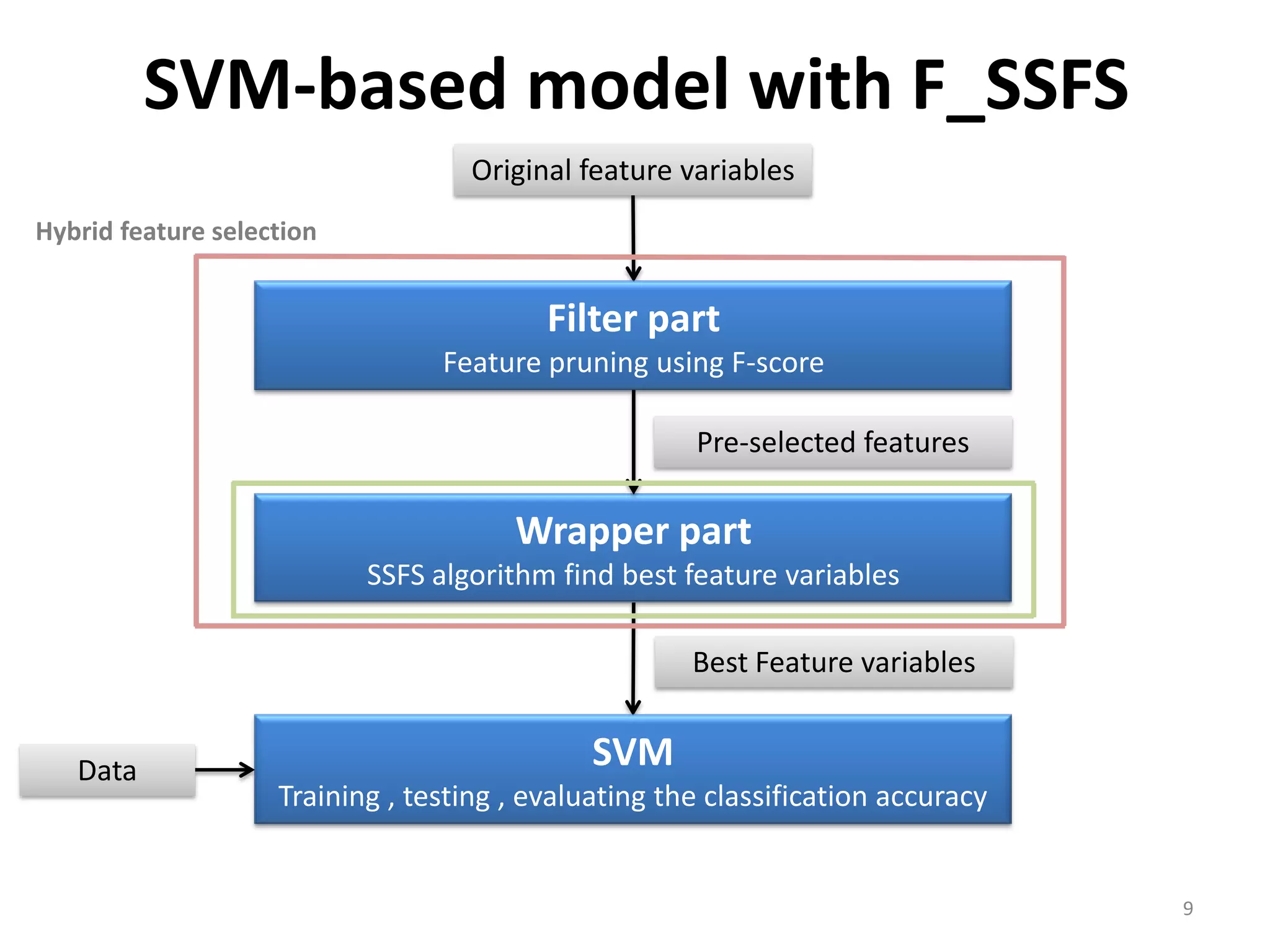
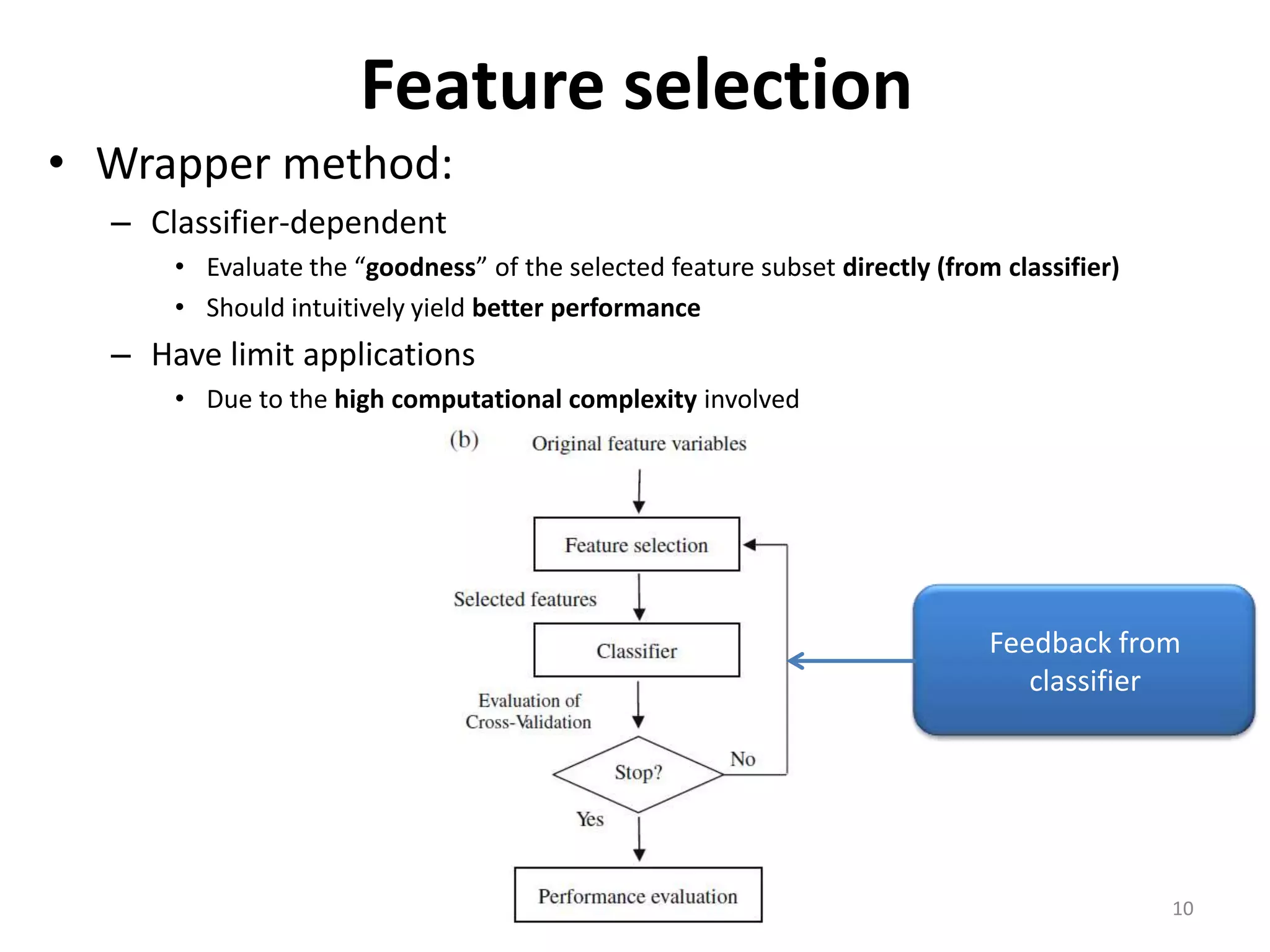
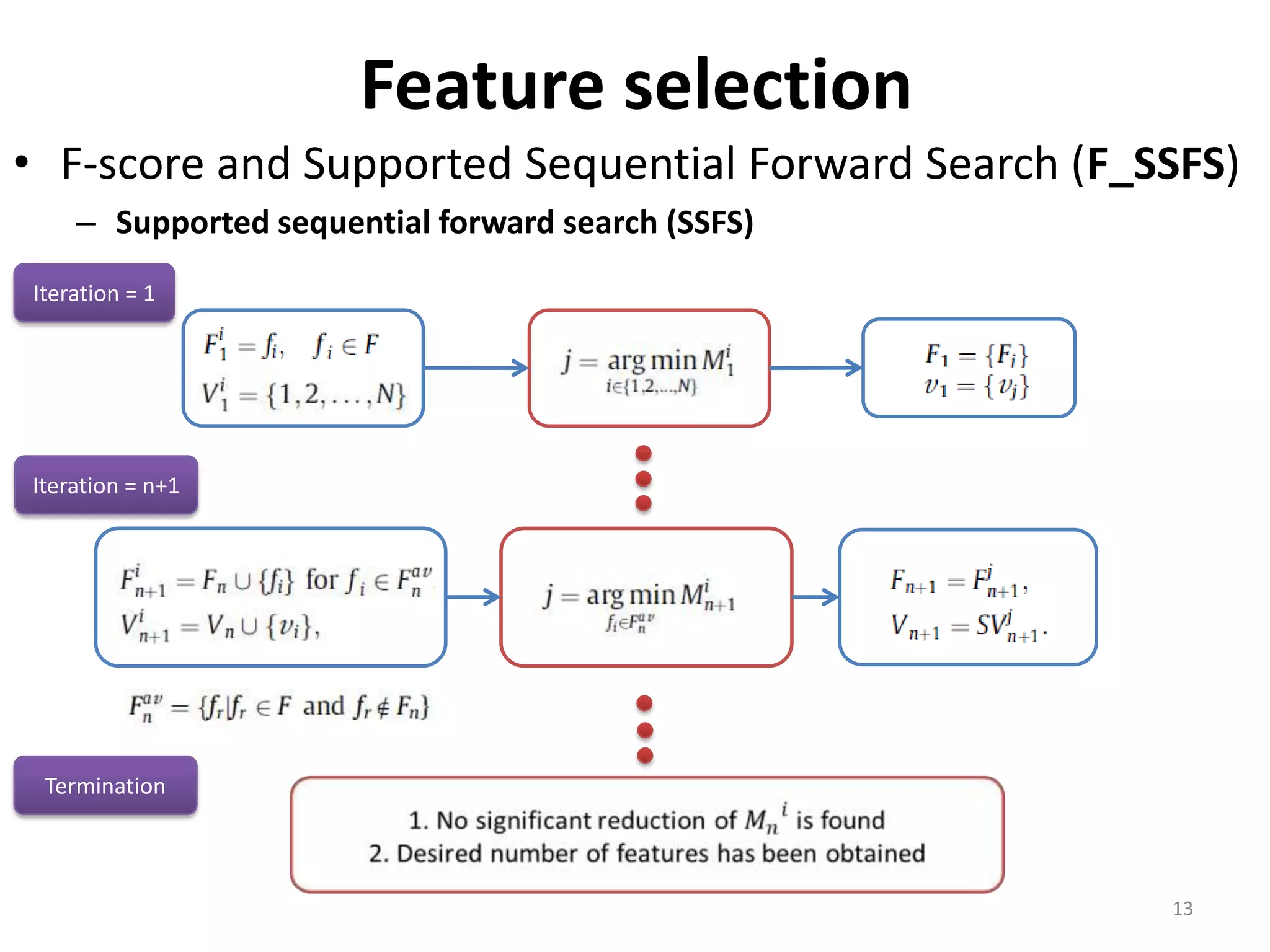
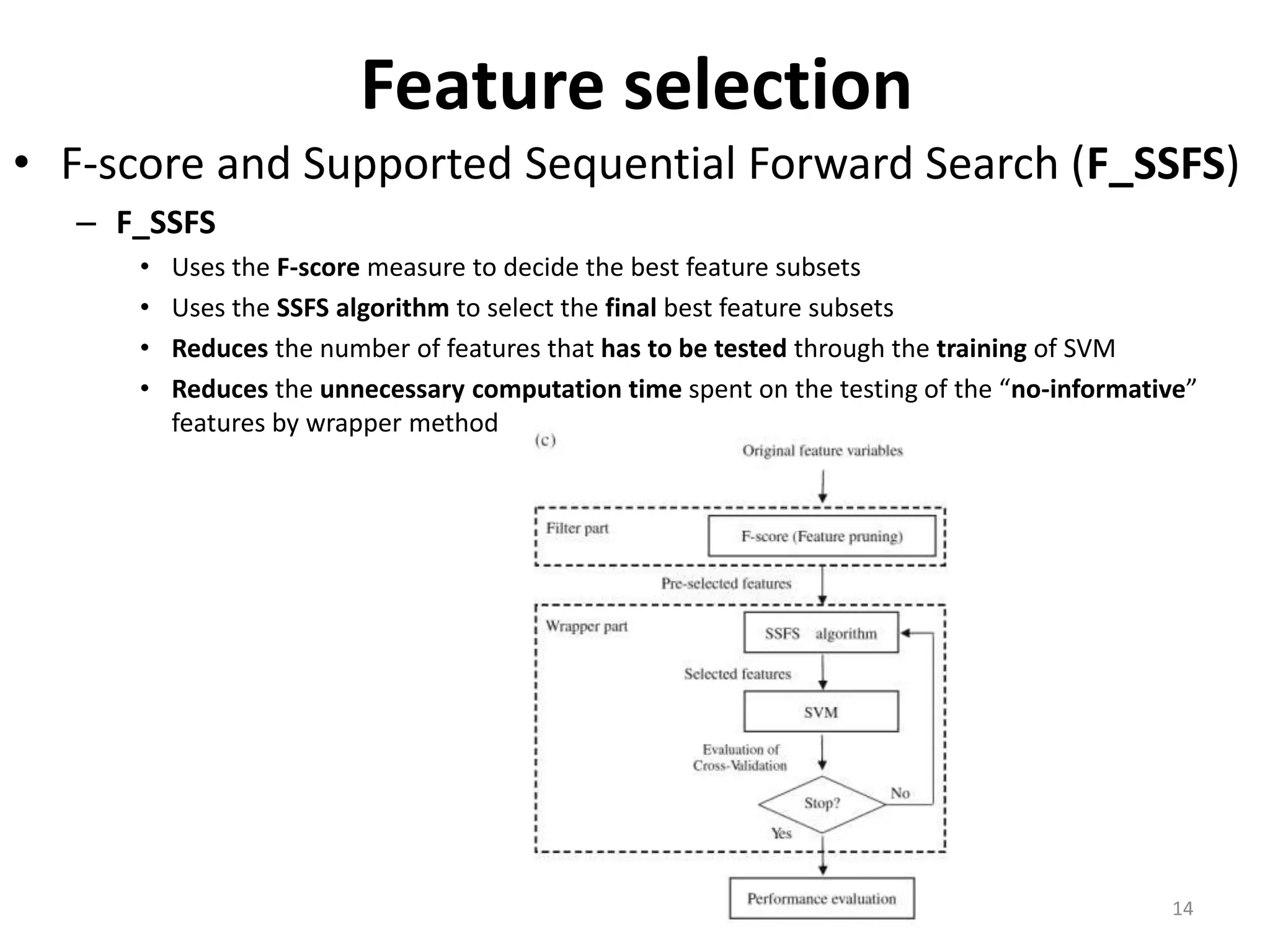
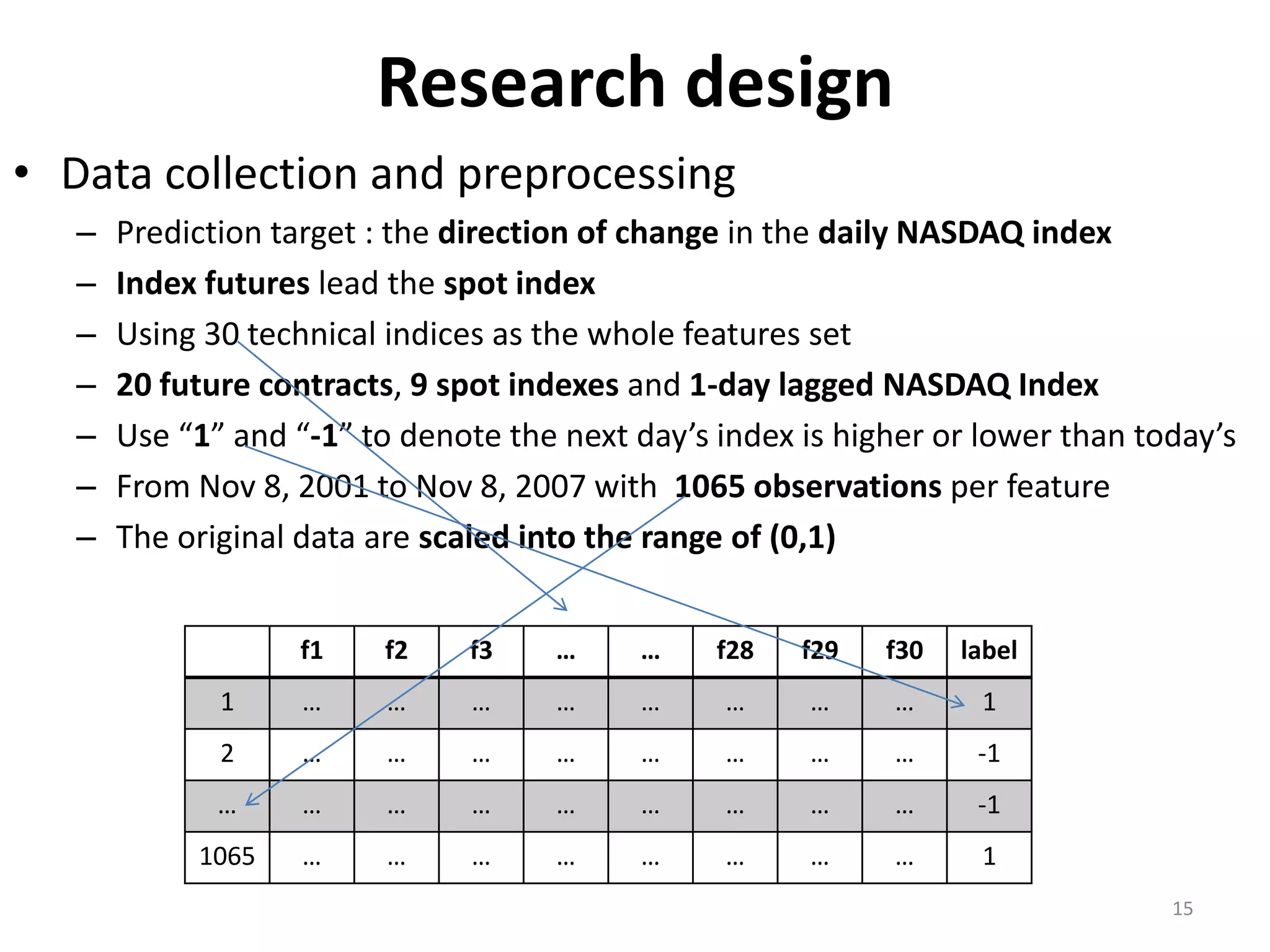
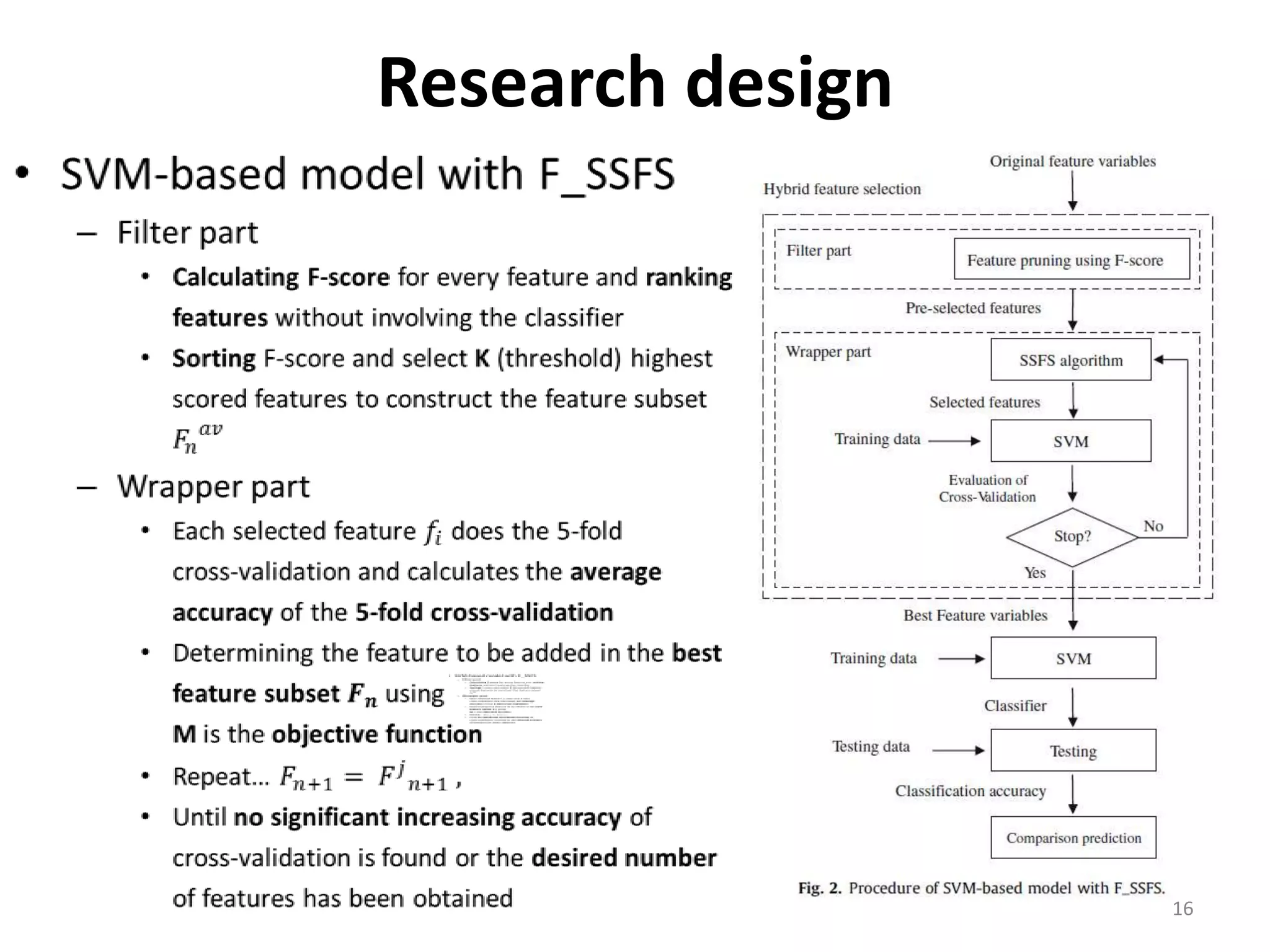
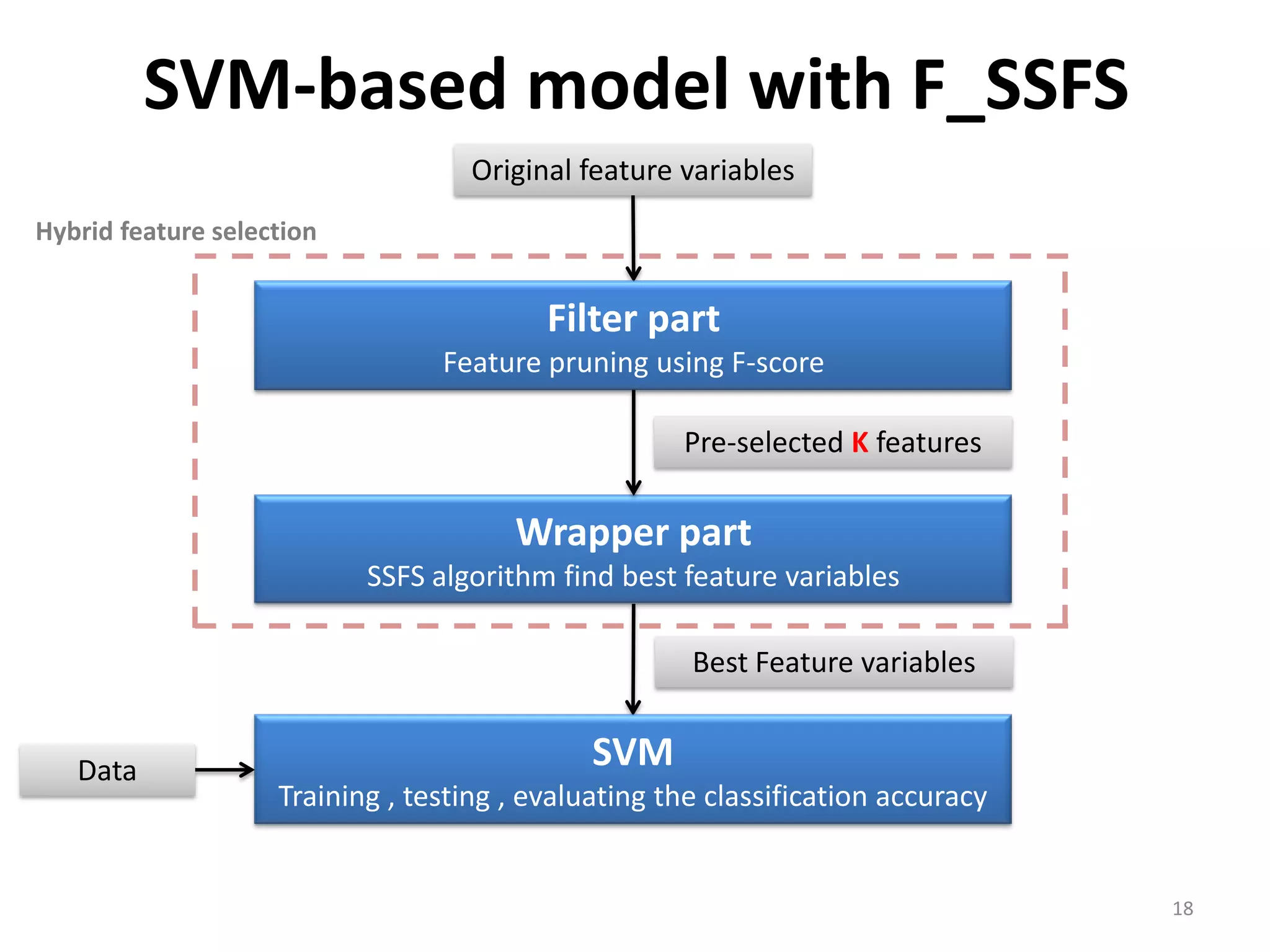
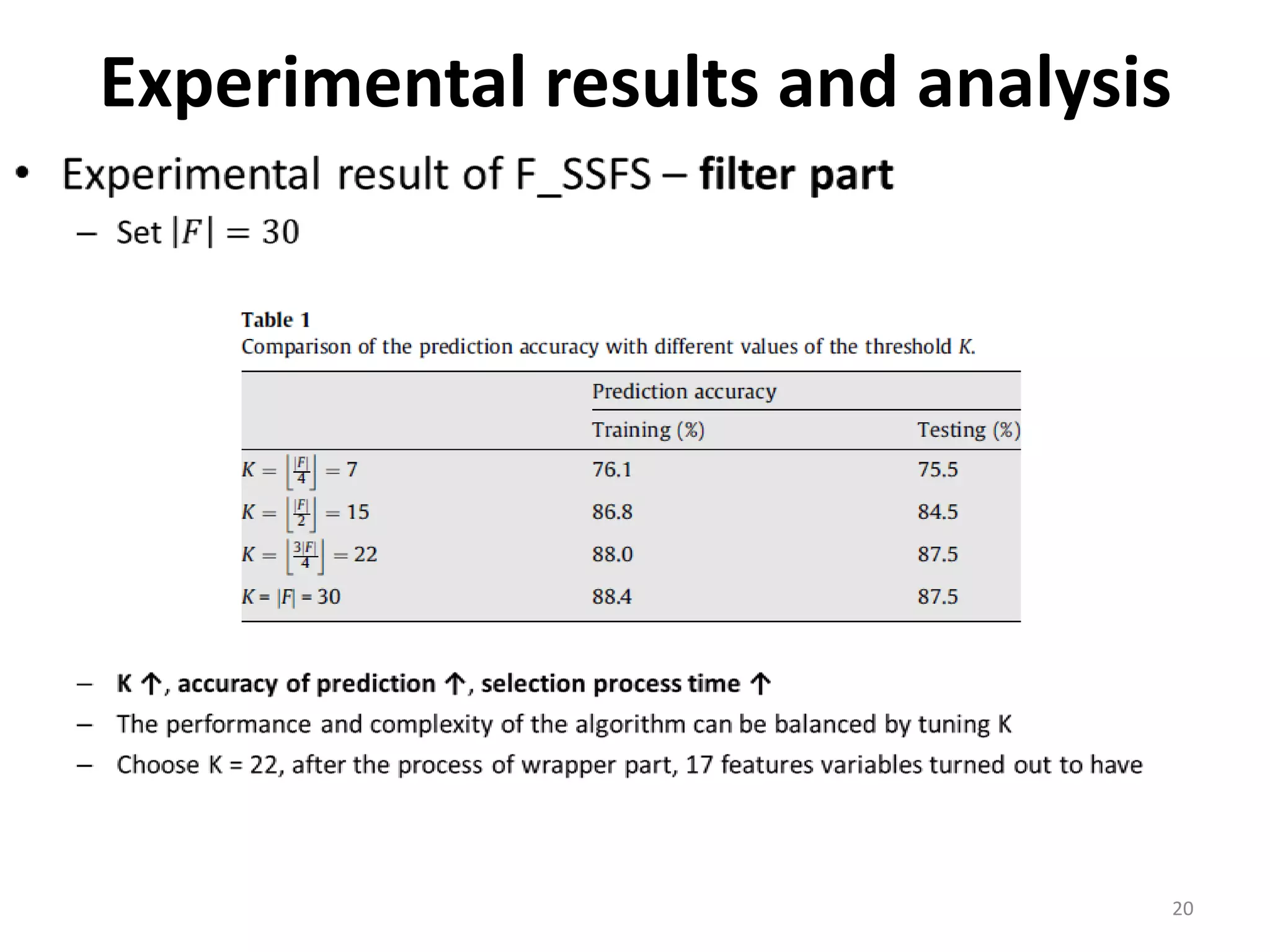
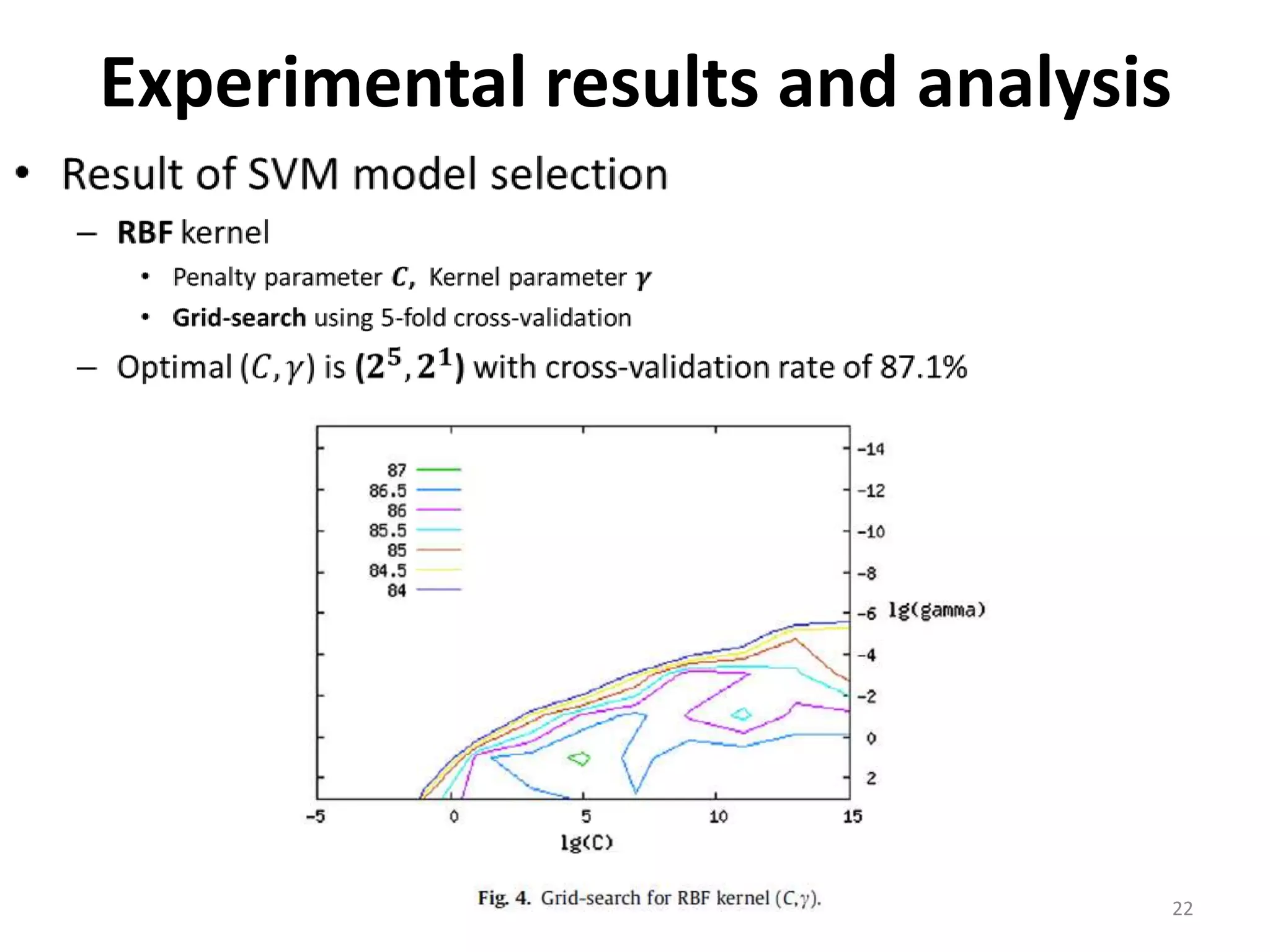
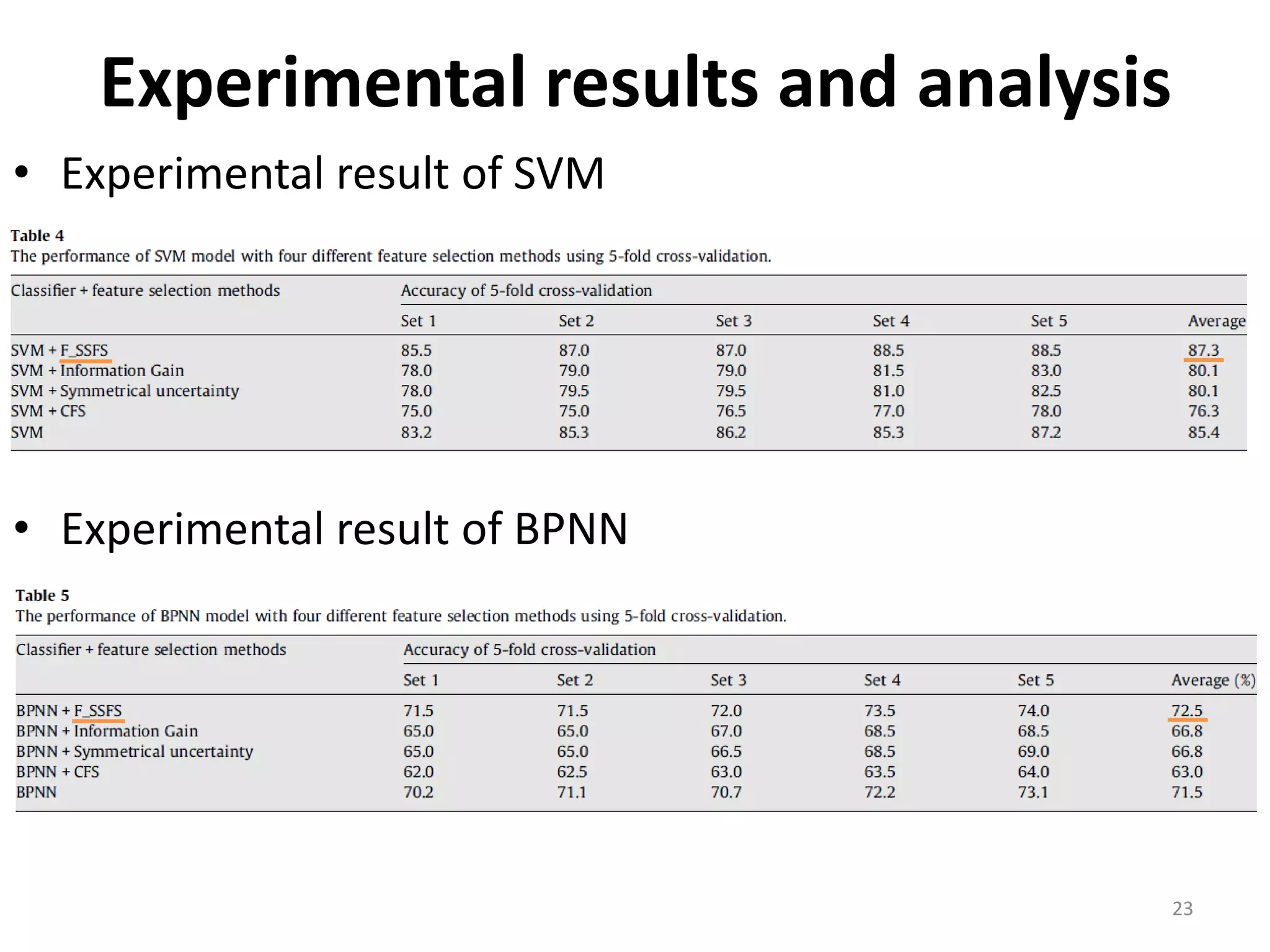
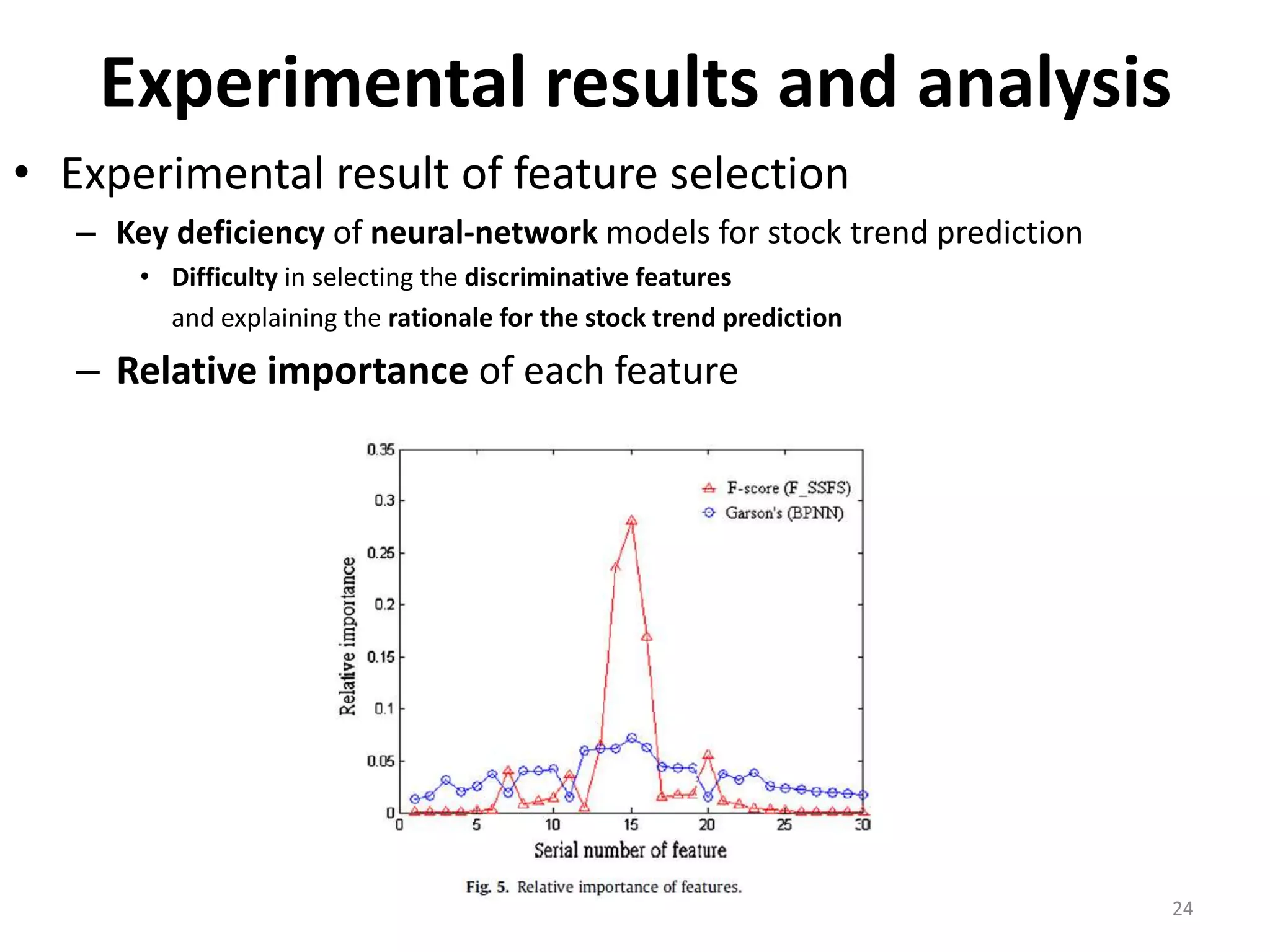
This document discusses using a support vector machine (SVM) with a hybrid feature selection method to predict stock trends. It proposes using F-score filtering followed by a wrapper method called Supported Sequential Forward Search (SSFS) to select optimal features for the SVM. An experiment applies this approach to NASDAQ index data, reducing 30 features to 17 using F_SSFS and achieving a classification accuracy of 81.7% with the SVM, outperforming a backpropagation neural network. The hybrid approach helps address overfitting issues while improving the SVM's prediction performance.