Downloaded 24 times








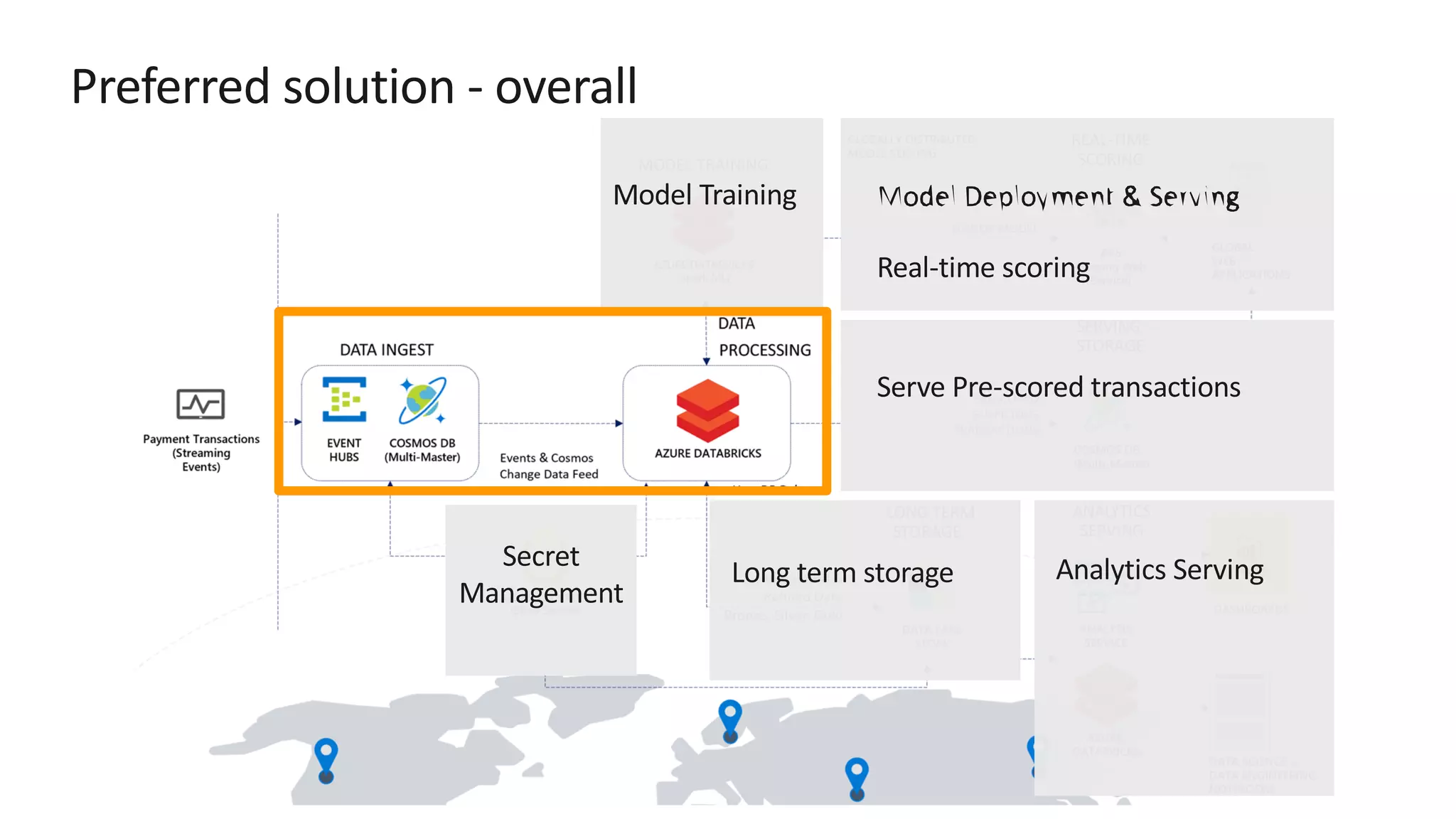





![Preferred solution – Data pipeline processing ž Store secrets such as account keys and connection strings centrally in Azure Key Vault ž Set Key Vault as the source for secret scopes in Azure Databricks. Secrets are [REDACTED].](https://image.slidesharecdn.com/srichintala-191031202107/75/Cosmos-DB-Real-time-Advanced-Analytics-Workshop-18-2048.jpg)

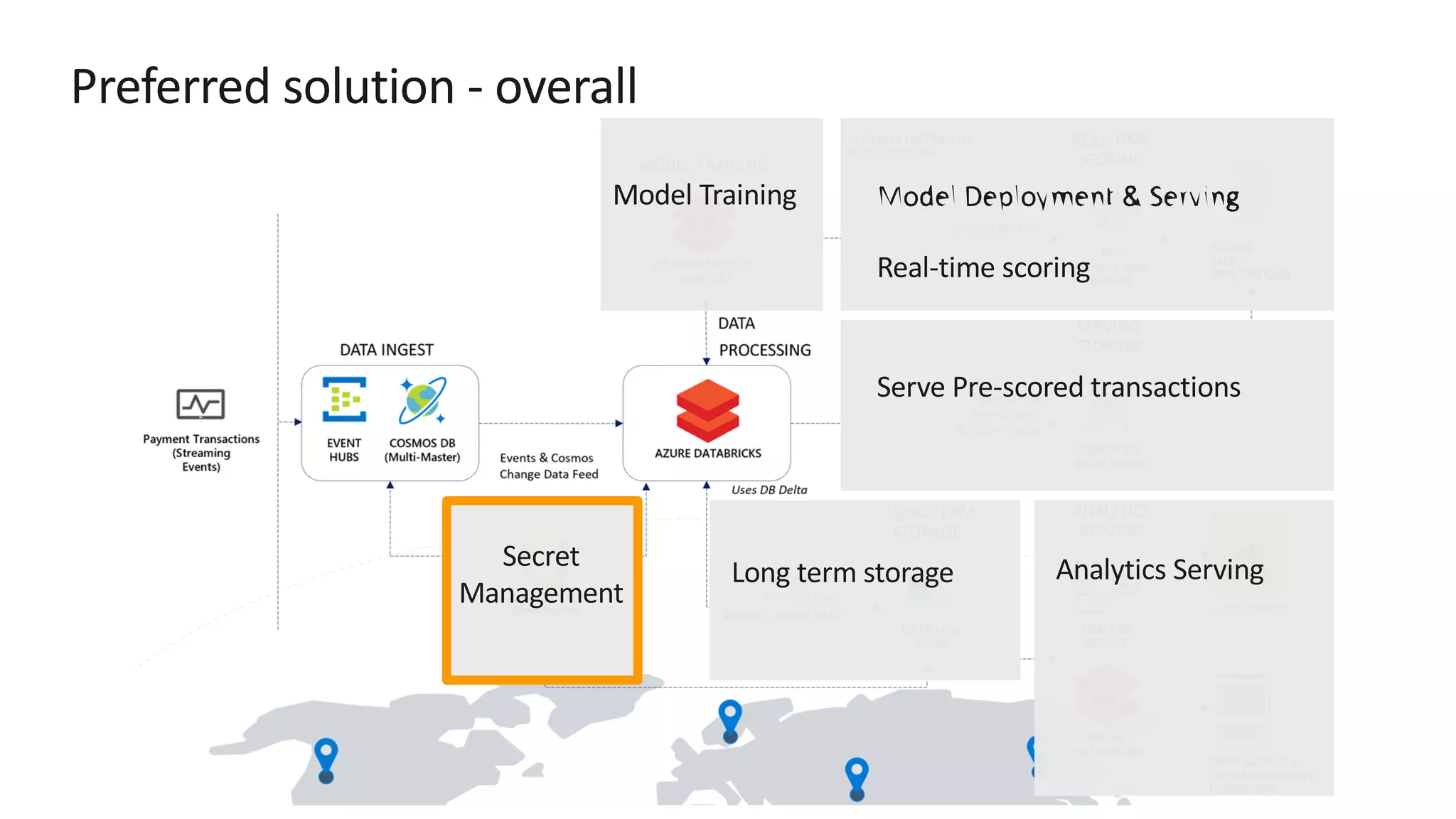
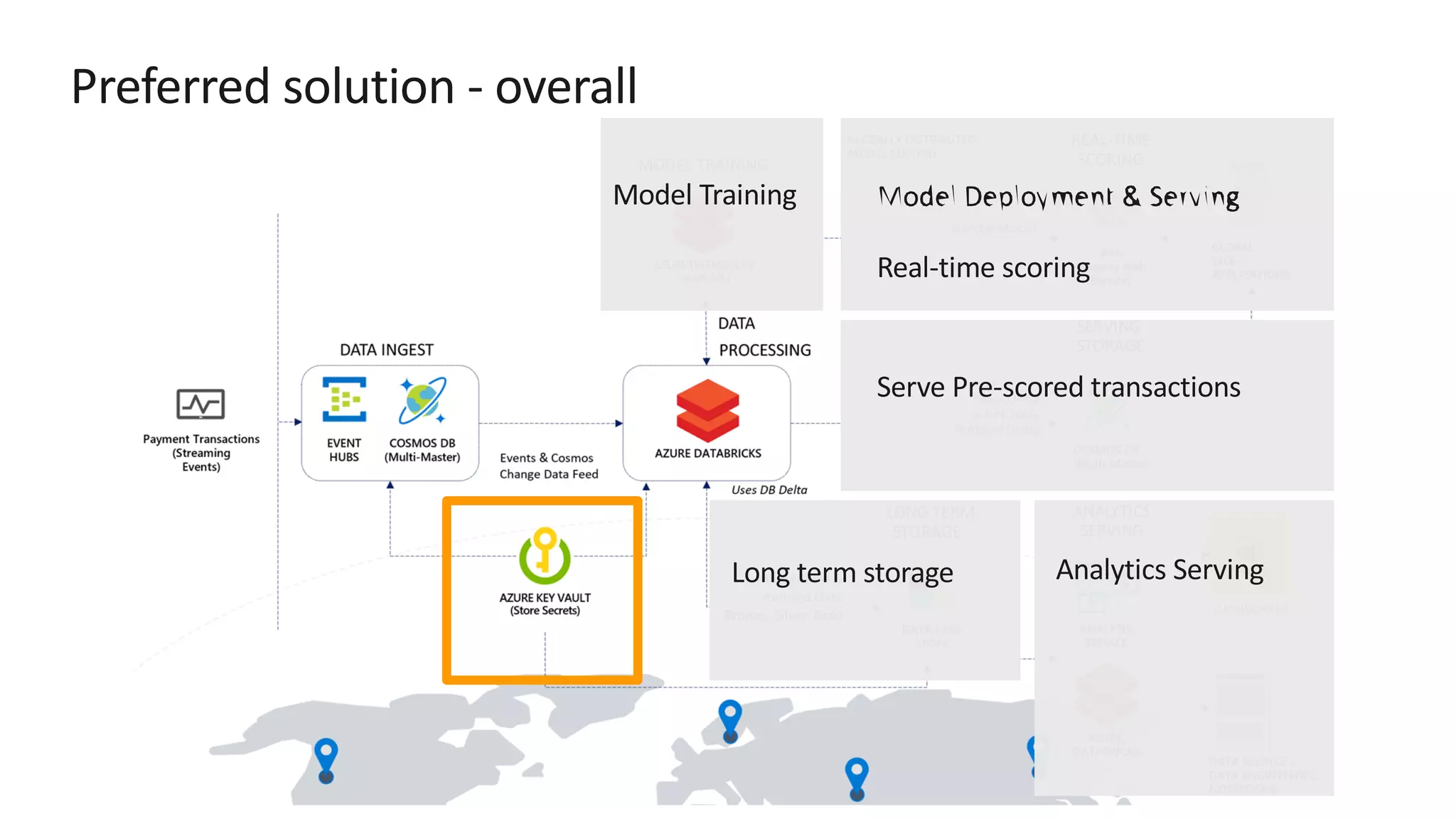
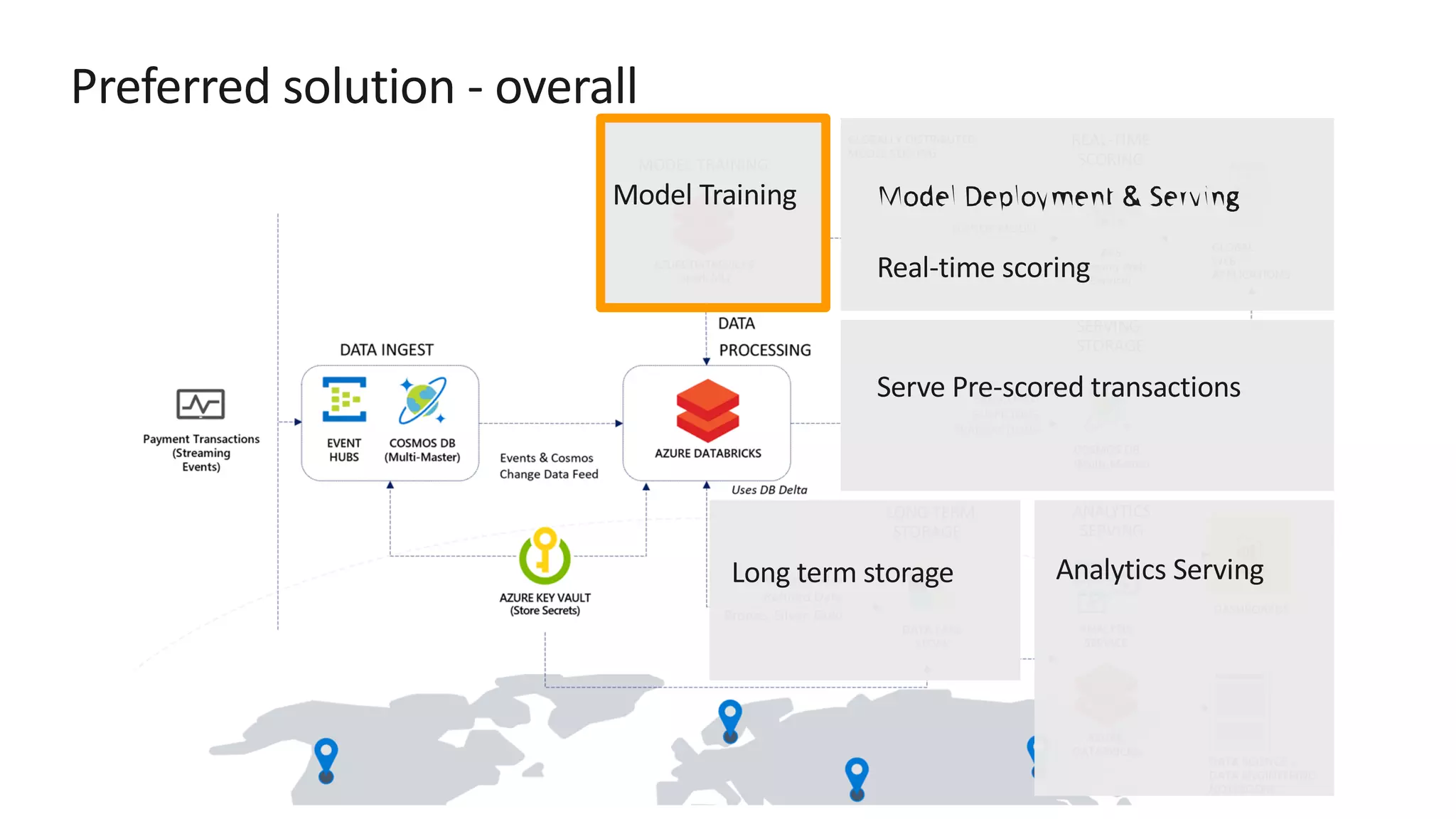
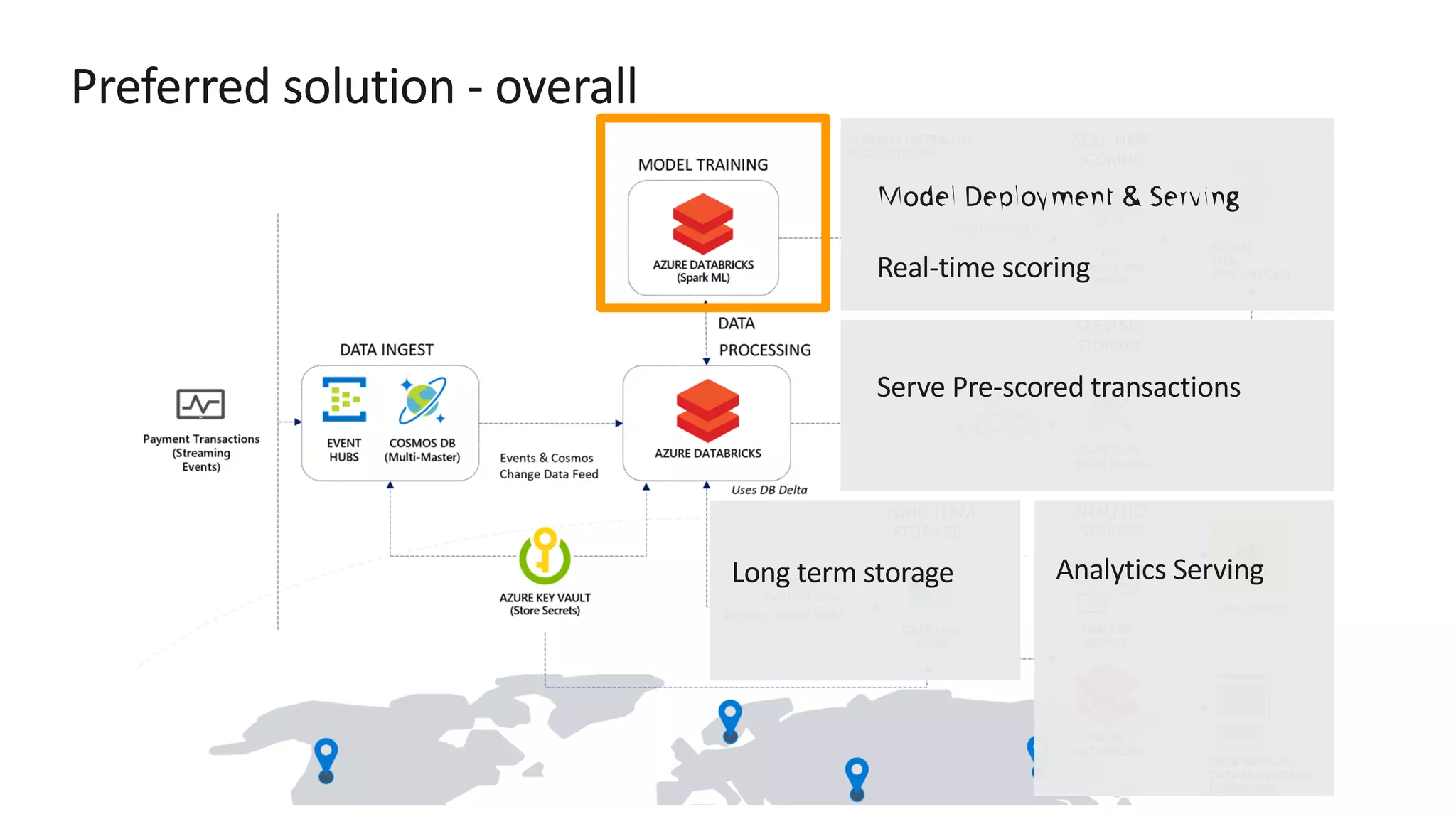

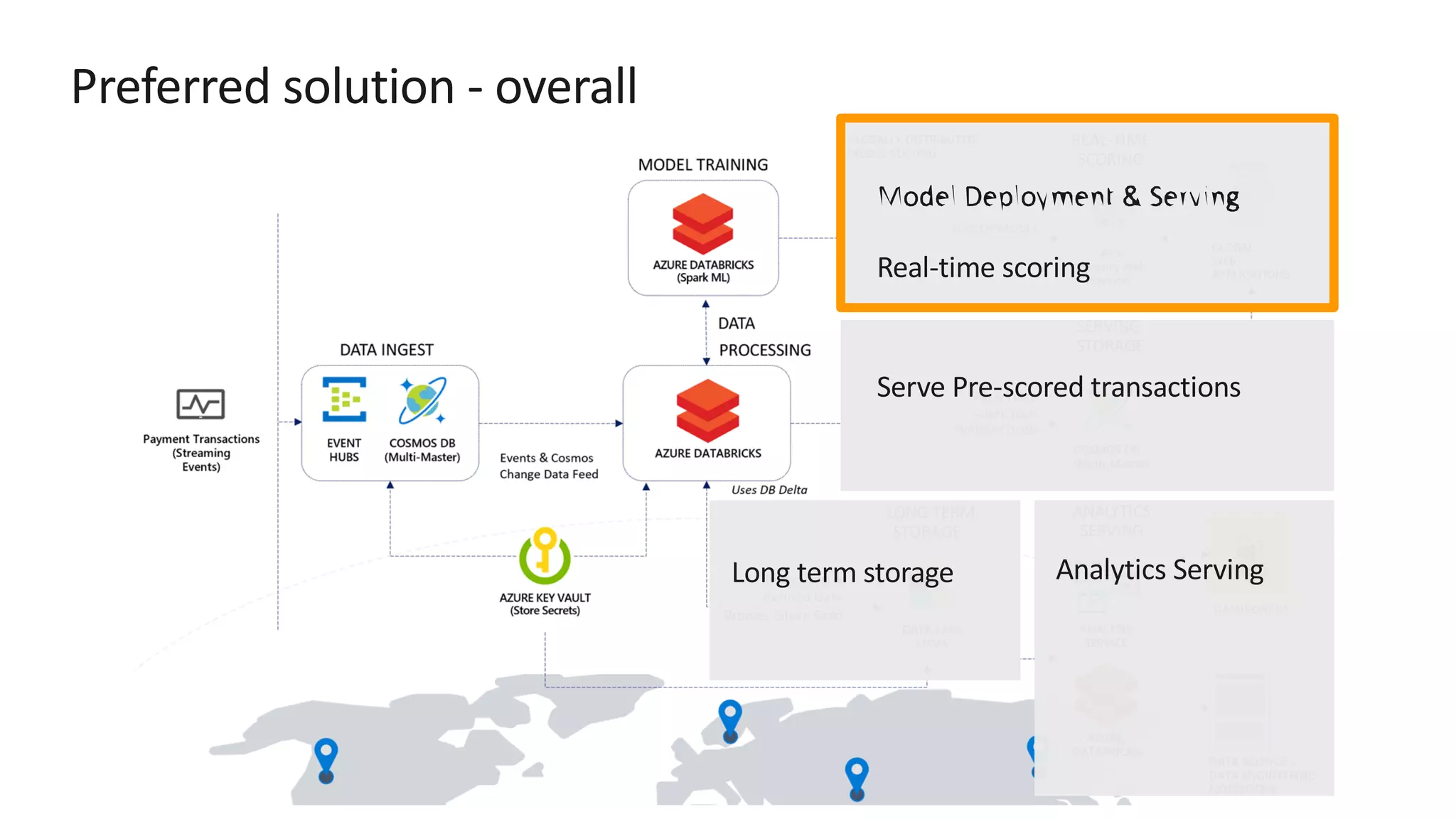
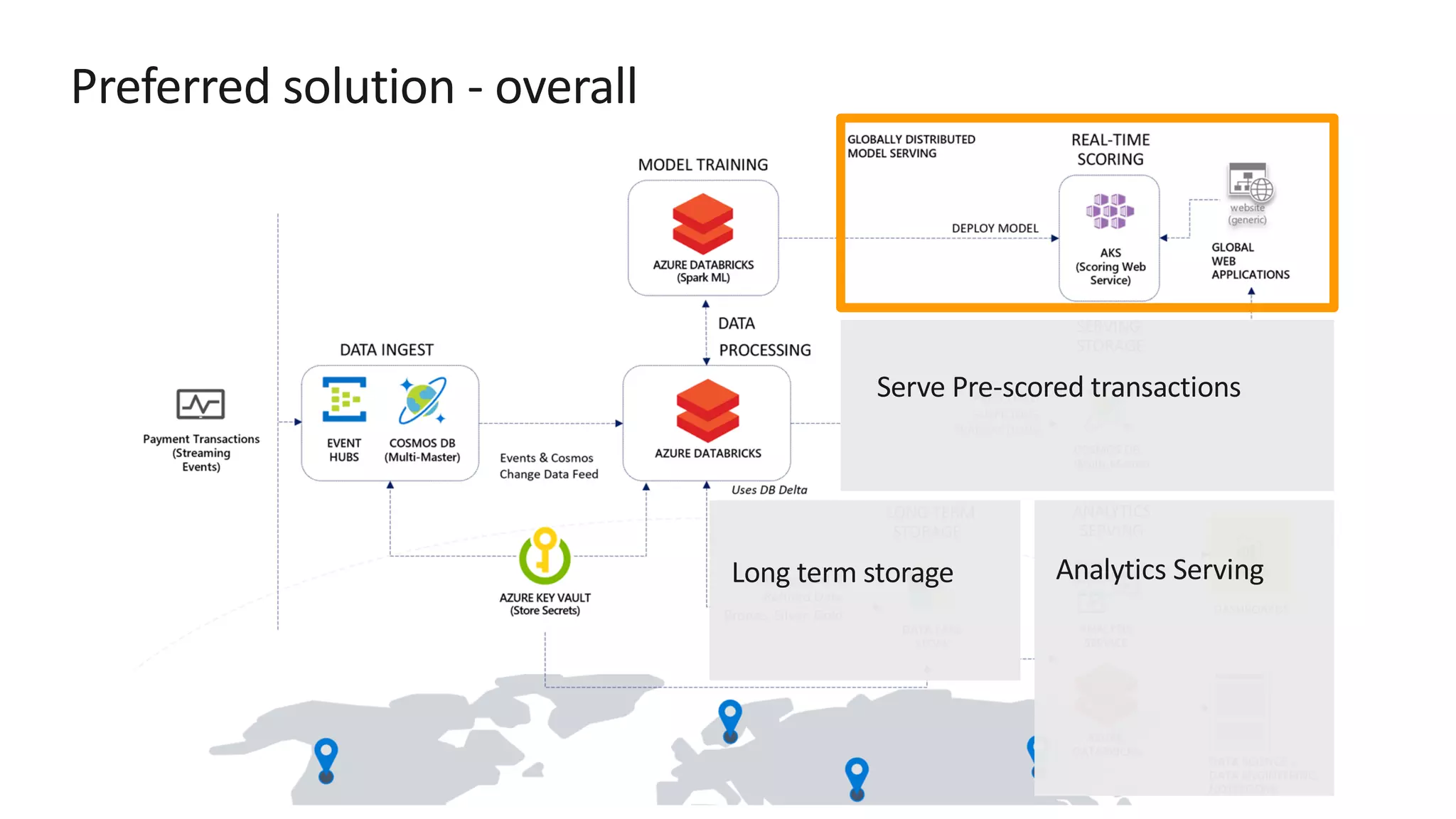

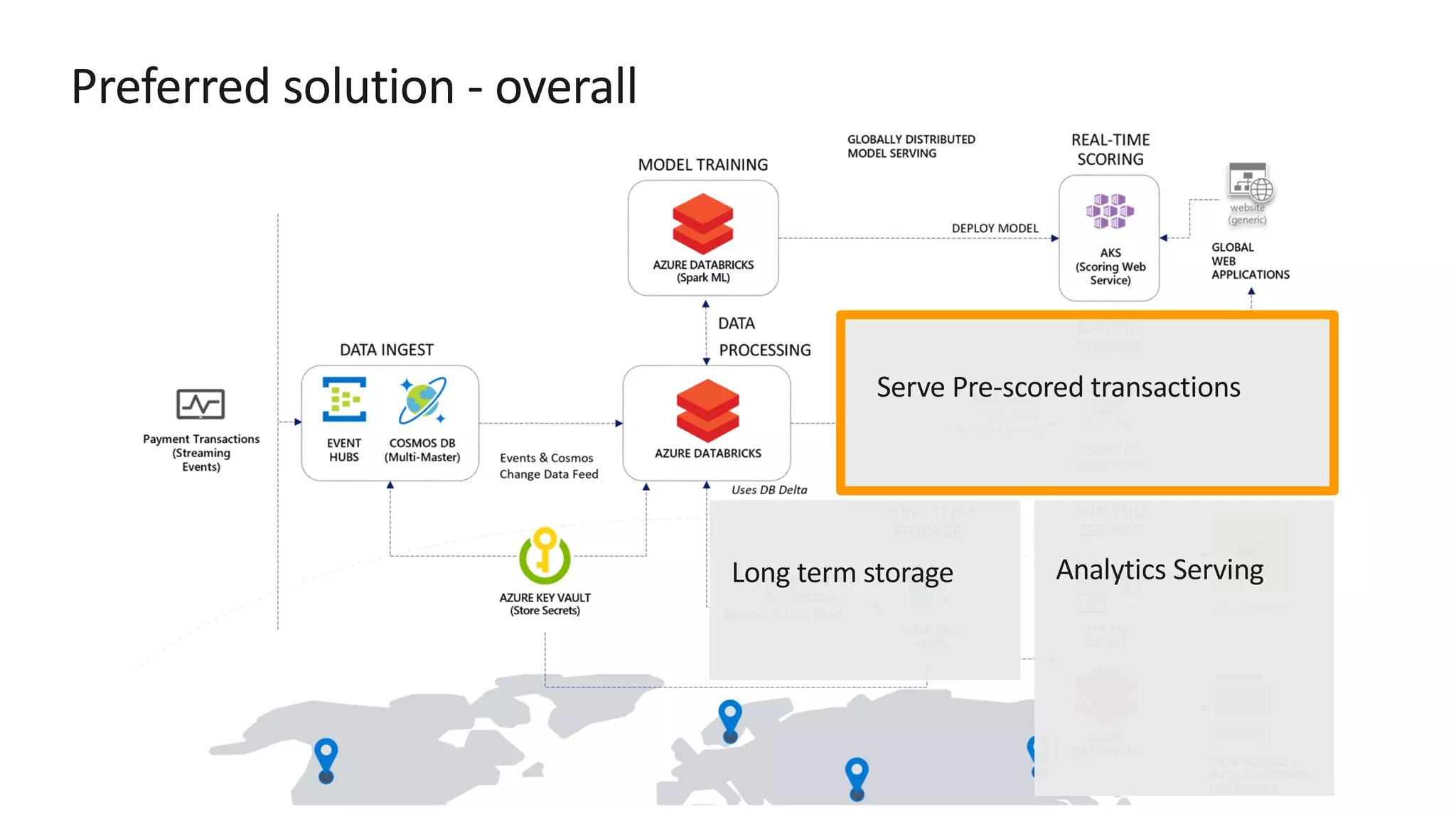
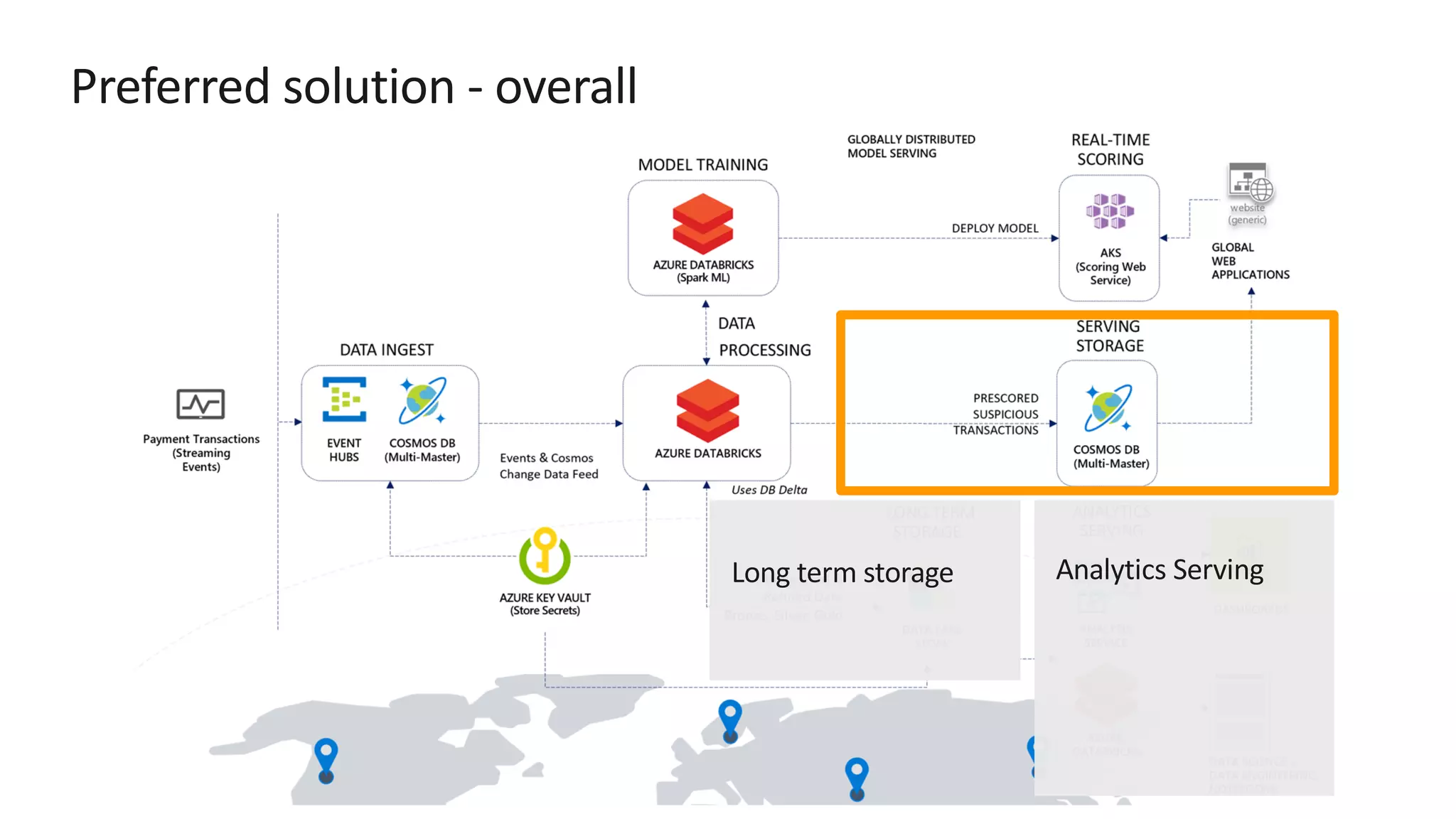

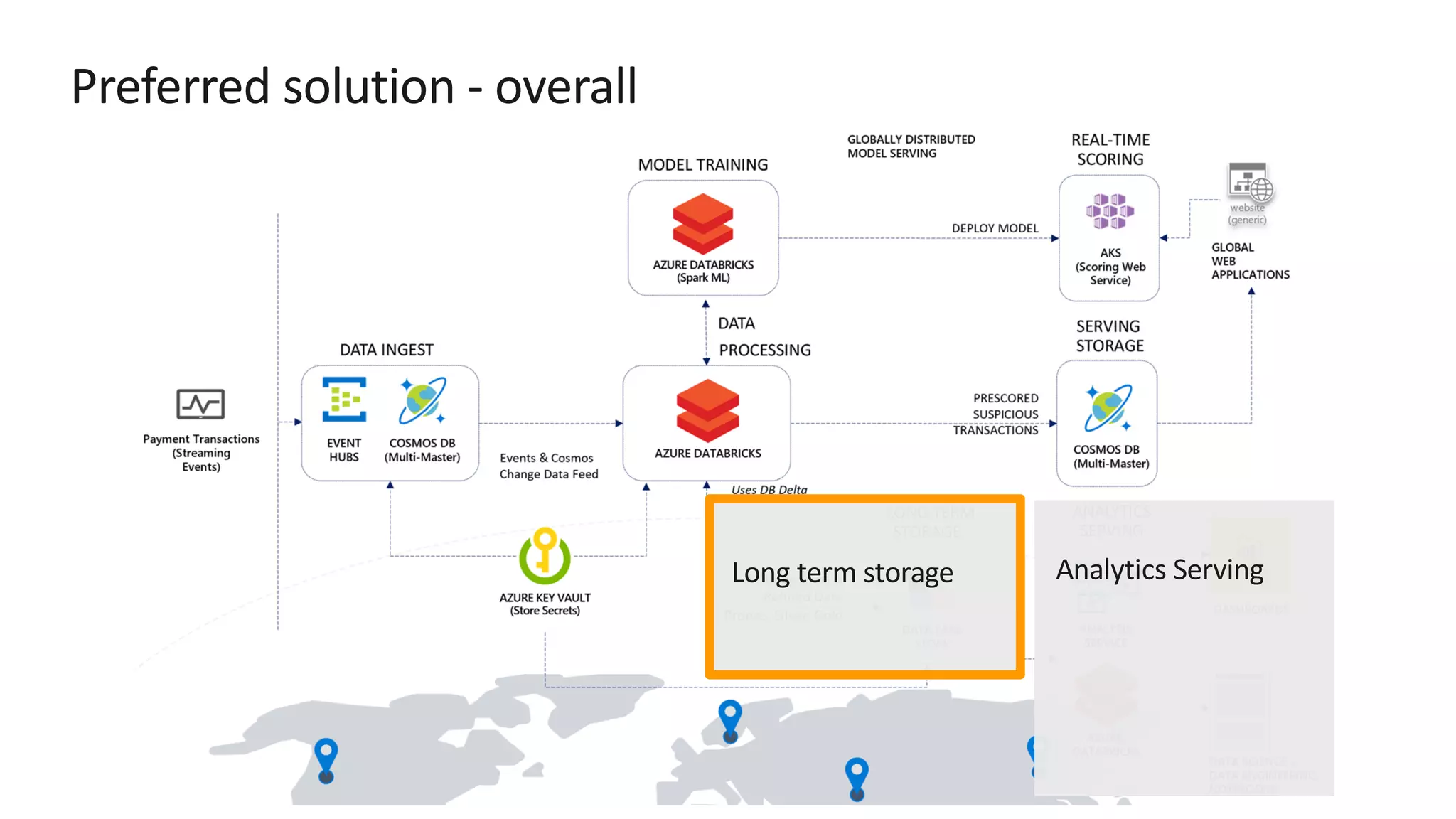
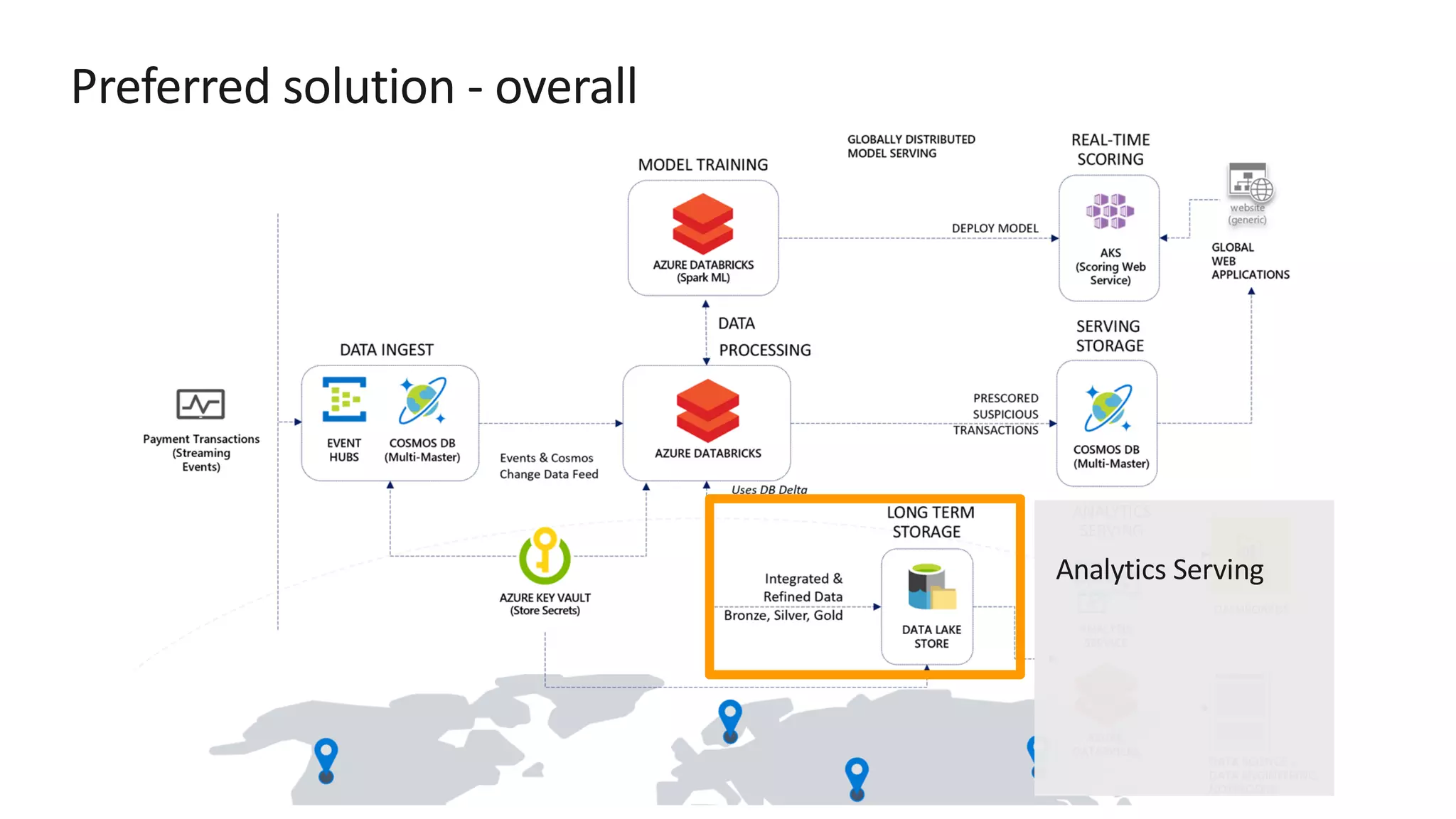

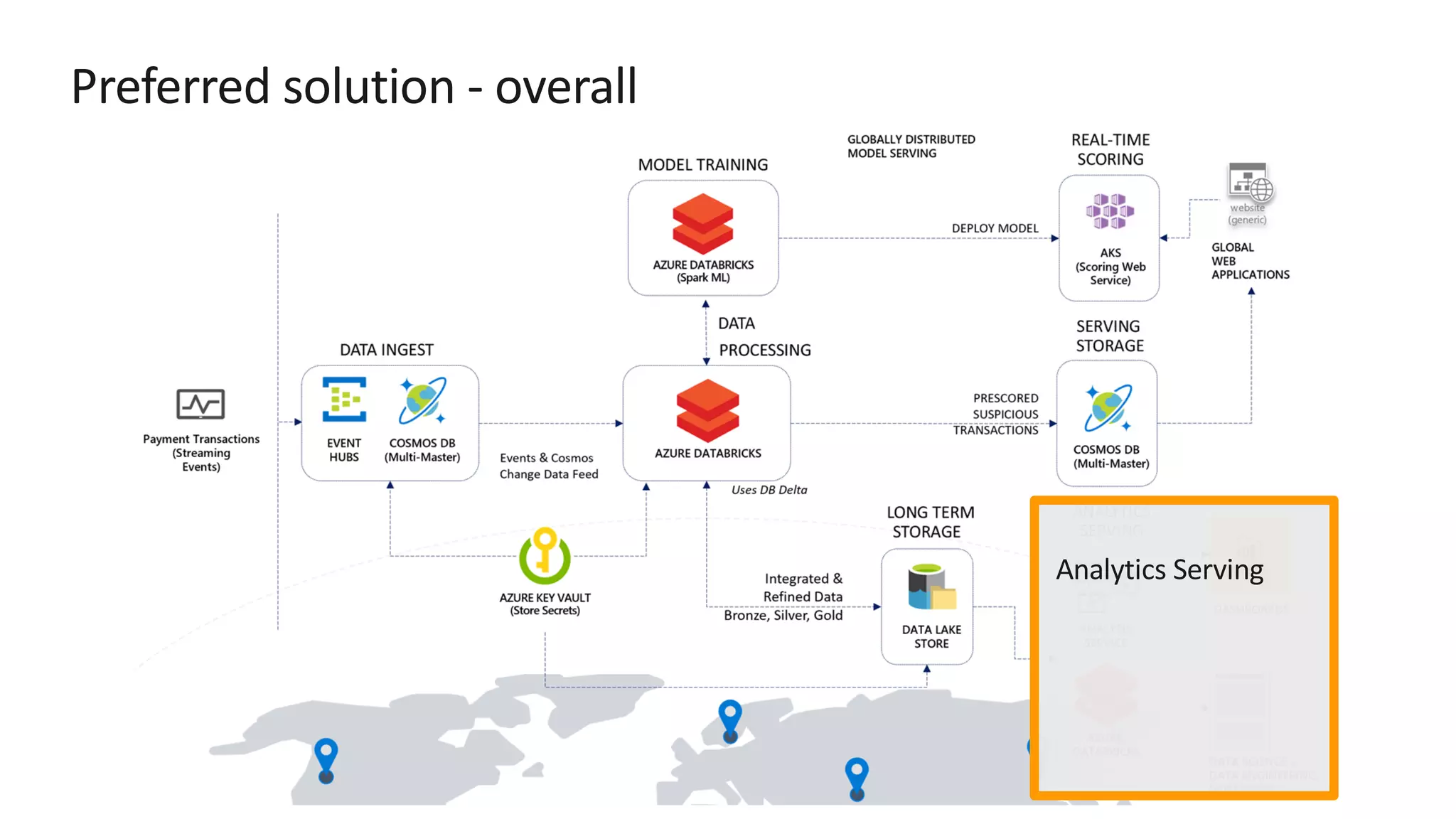
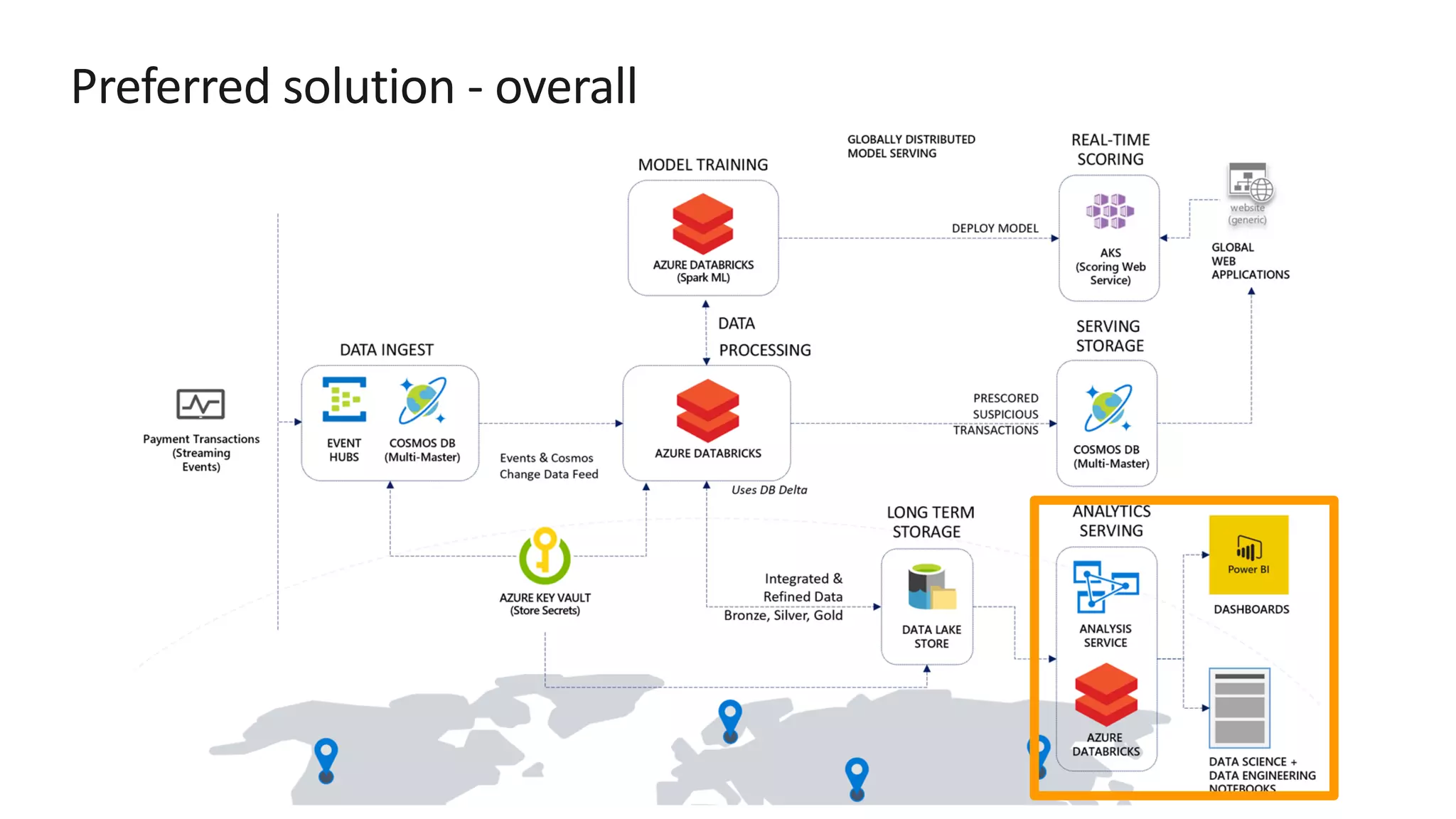


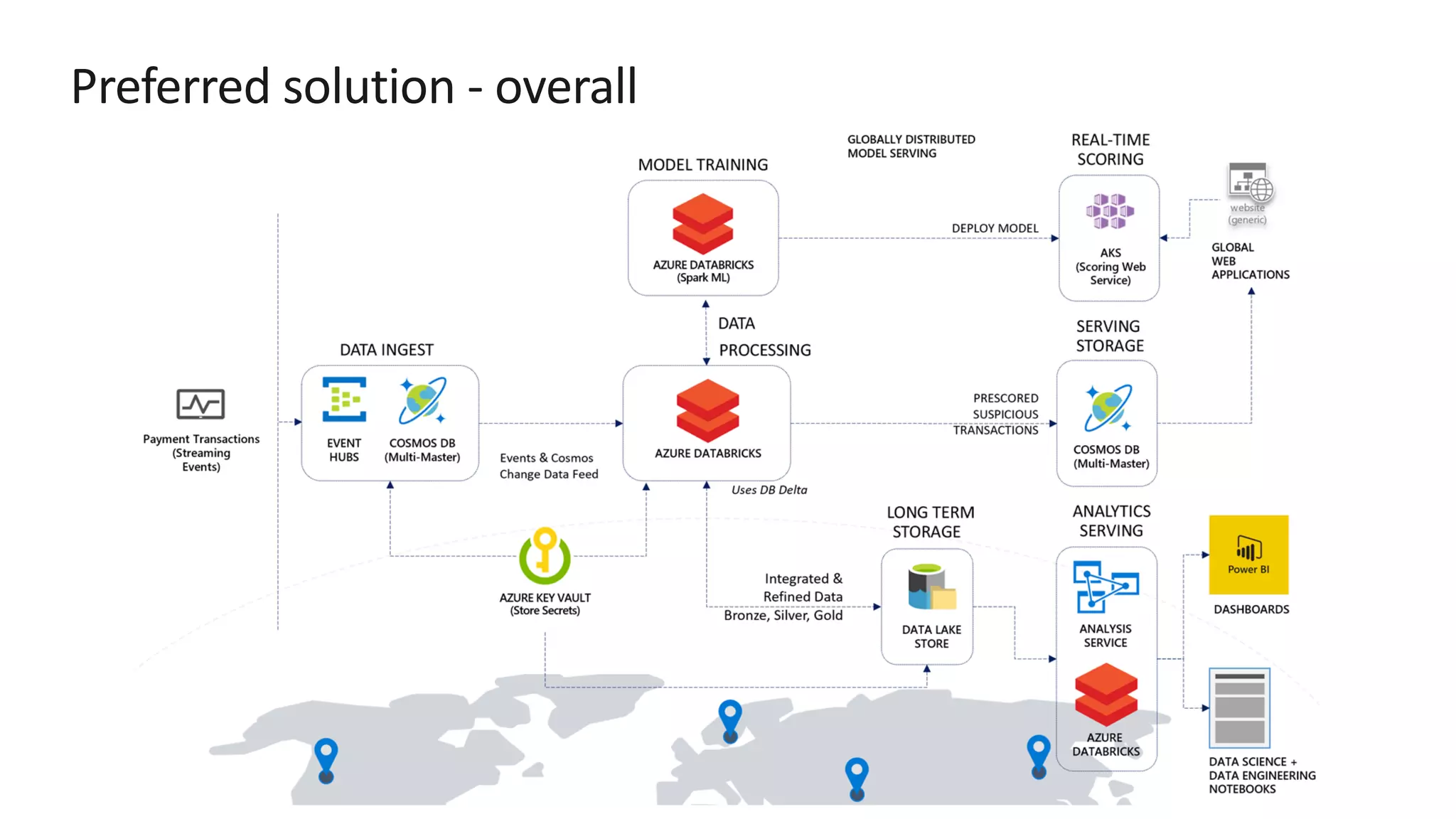



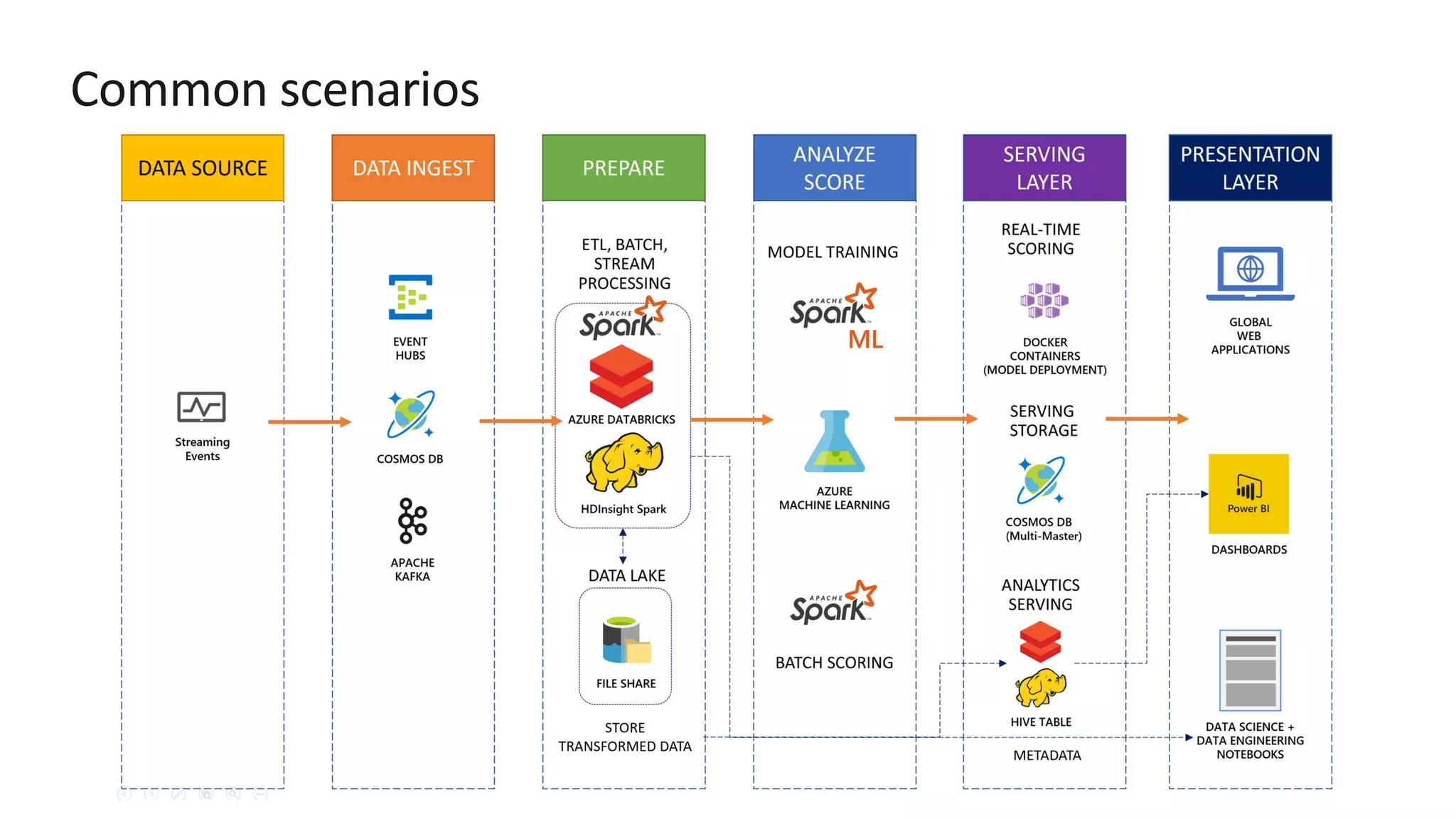
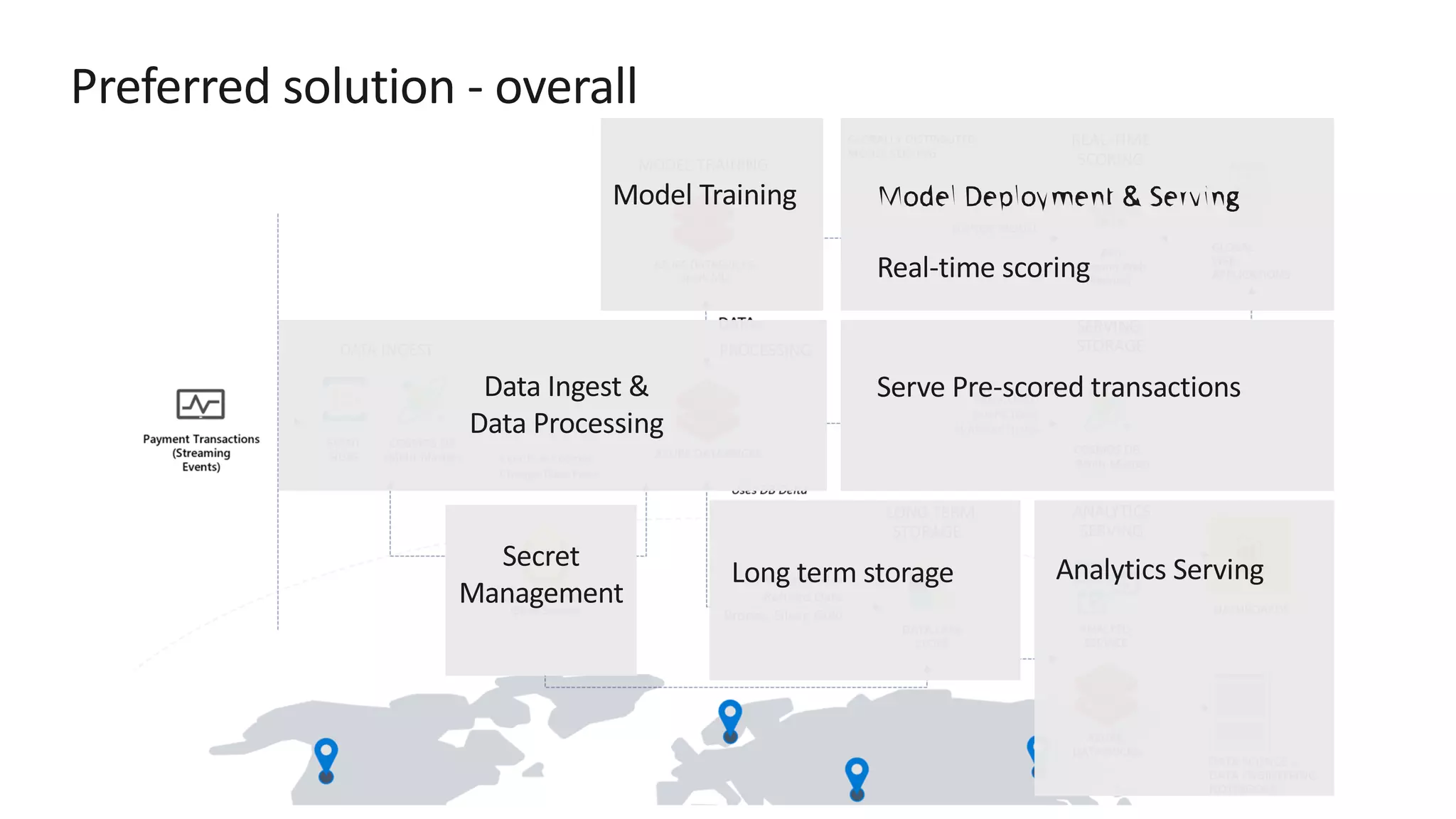
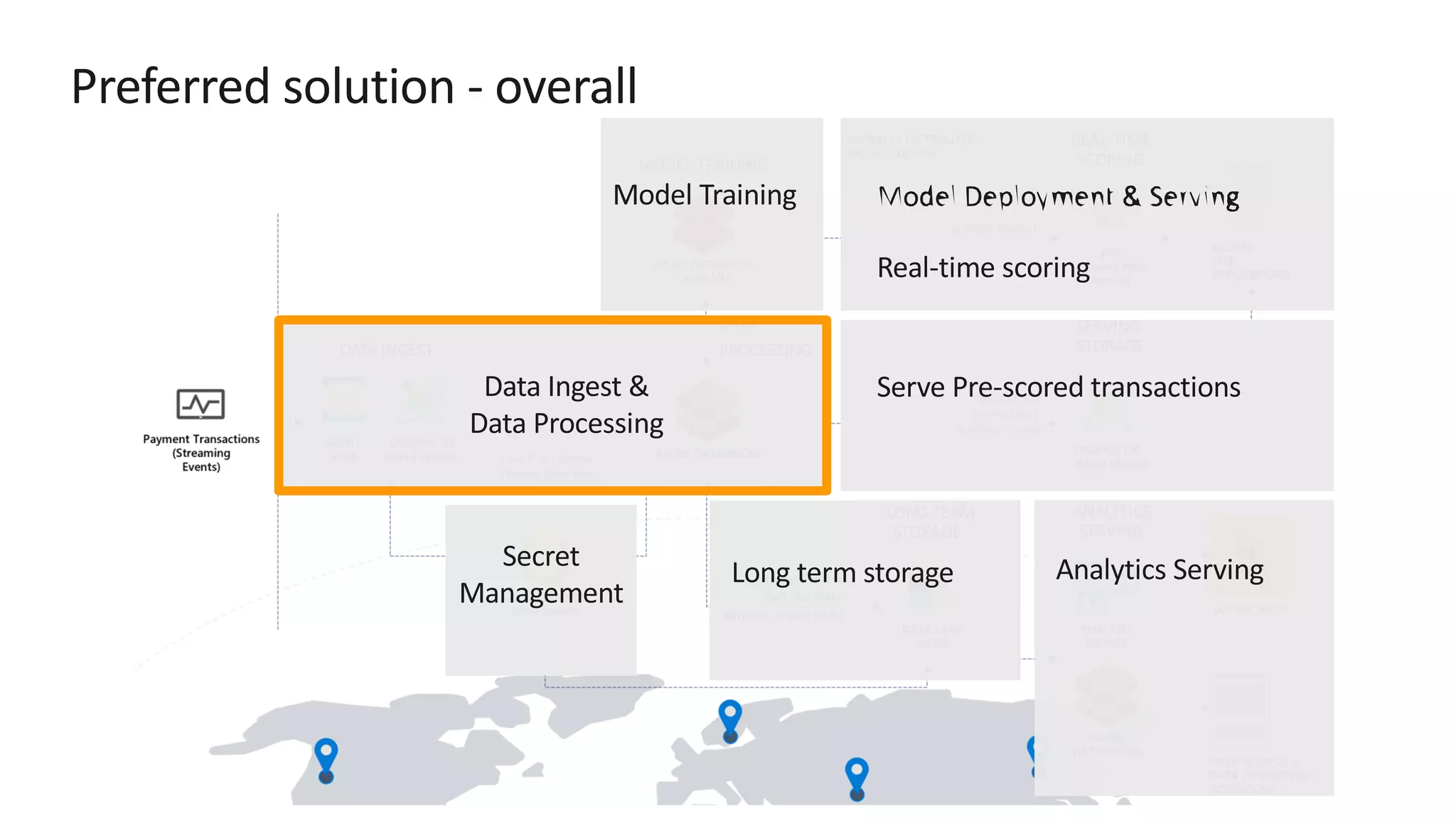
The document discusses the design of a real-time fraud detection solution for Woodgrove Bank using Azure technologies, specifically focusing on Cosmos DB and Azure Databricks for data ingestion, processing, and model deployment. It highlights the bank's need to monitor millions of transactions to prevent financial fraud while ensuring low latency and efficient data storage. The proposed solution includes various components such as machine learning, data lakes for long-term storage, and tools for reporting and dashboard creation with Power BI.