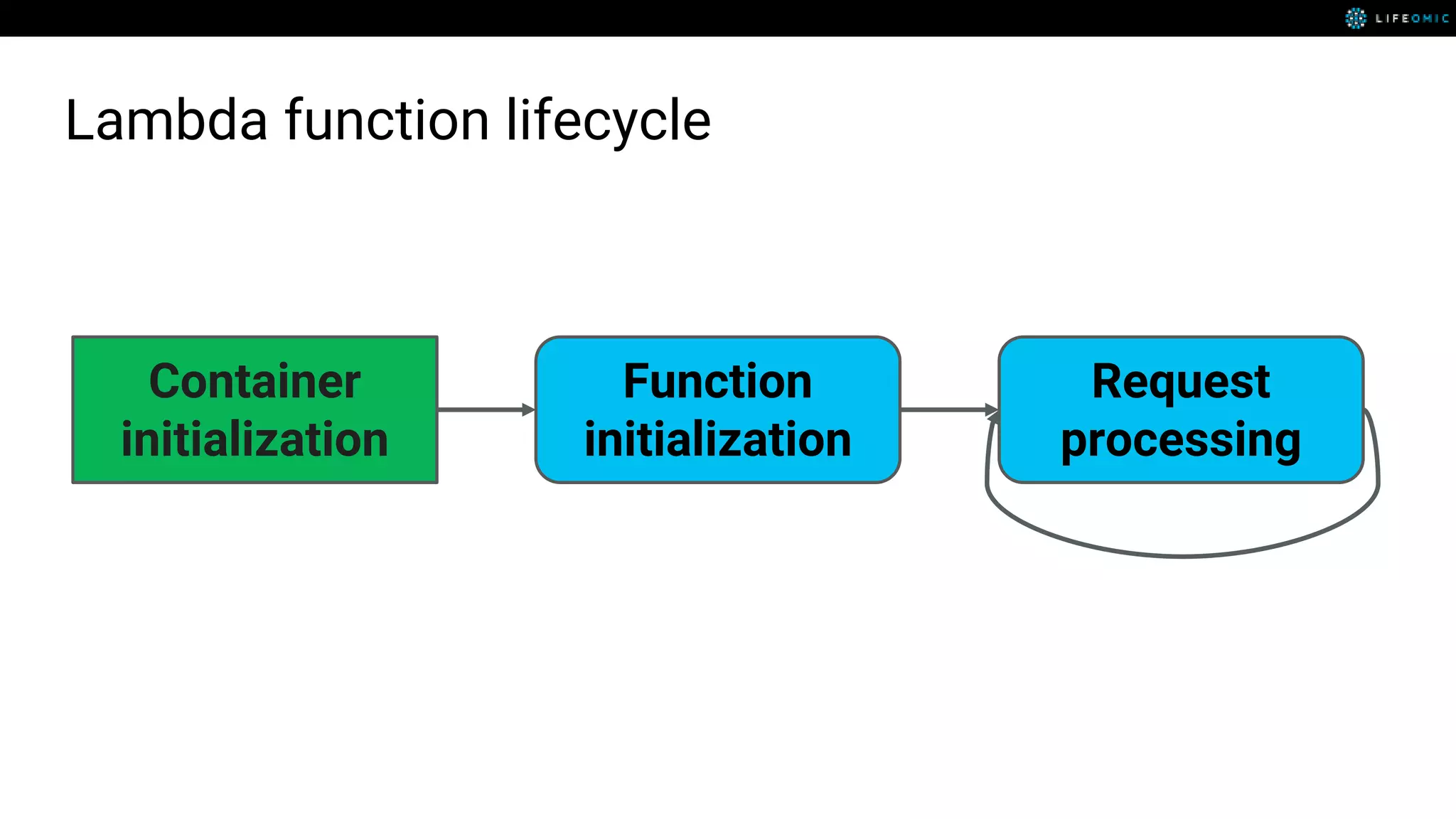
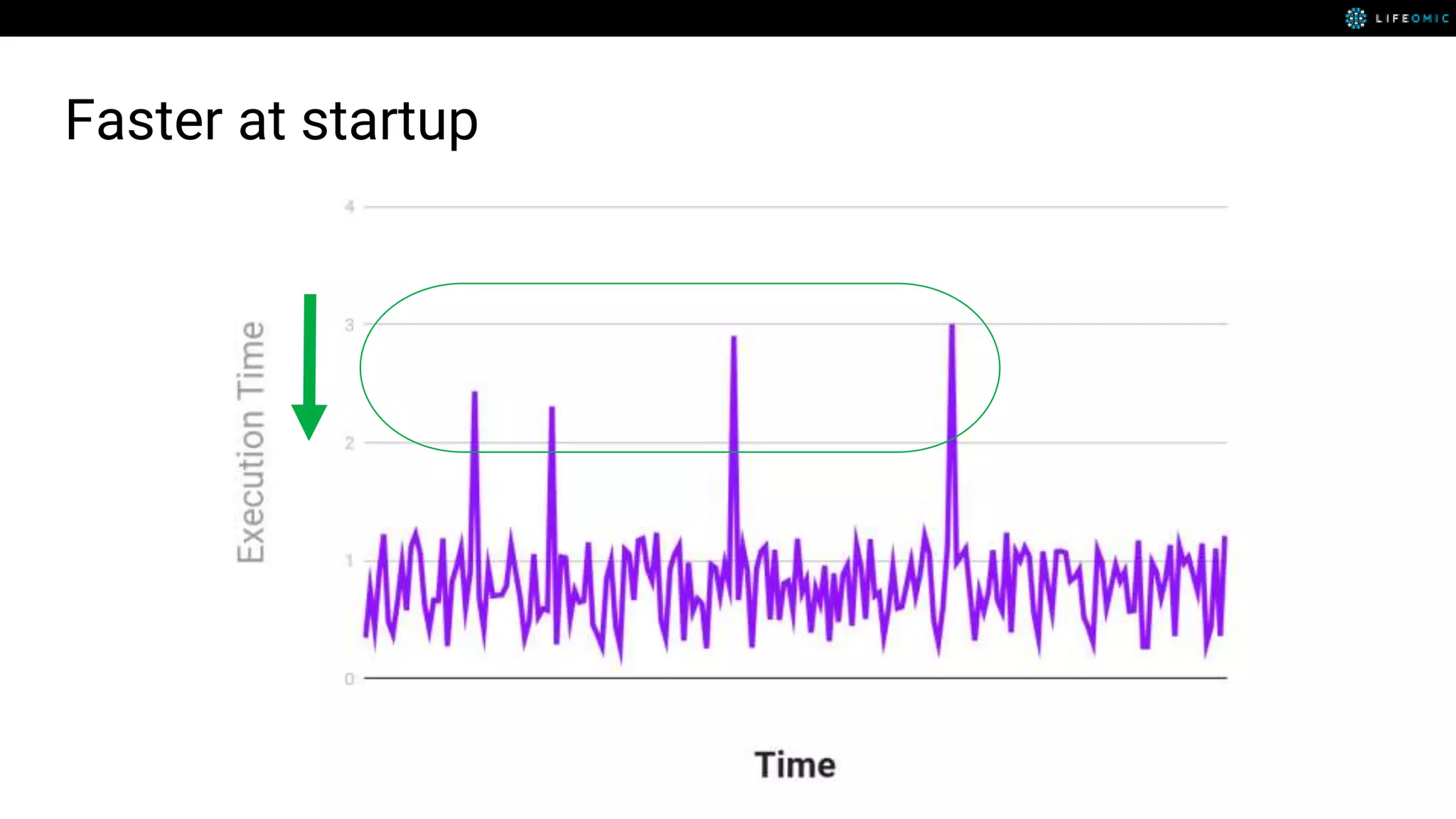
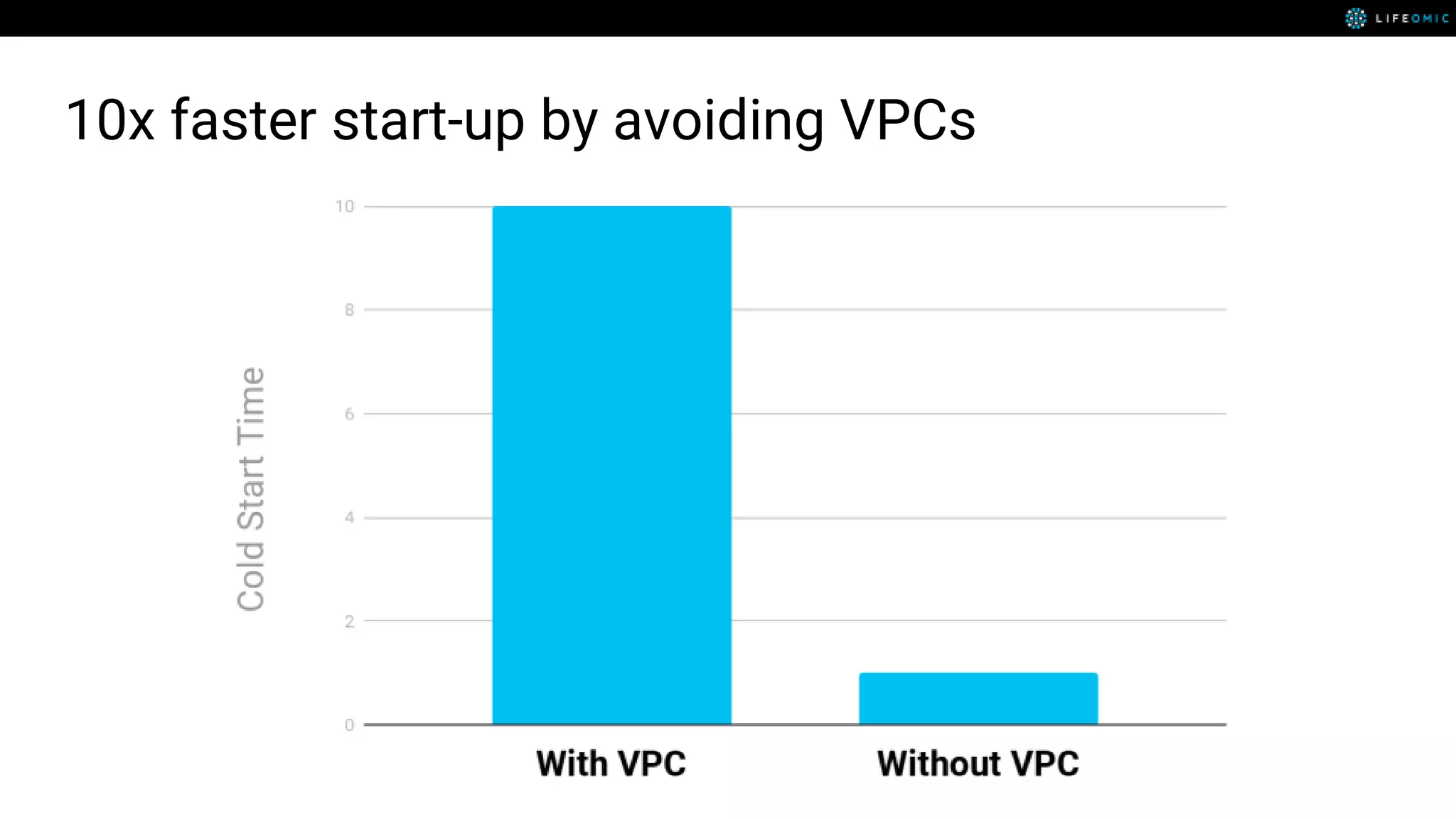
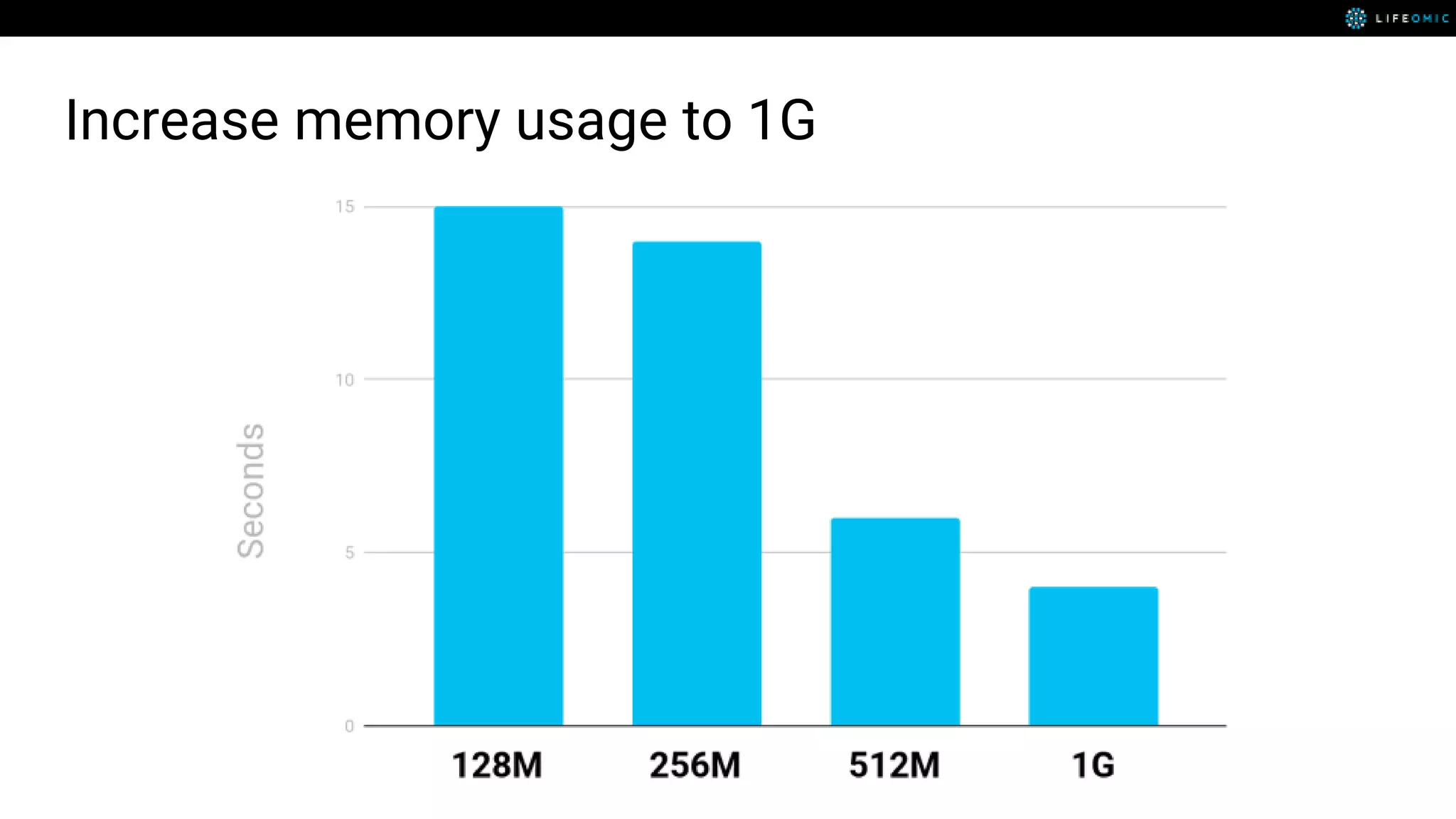
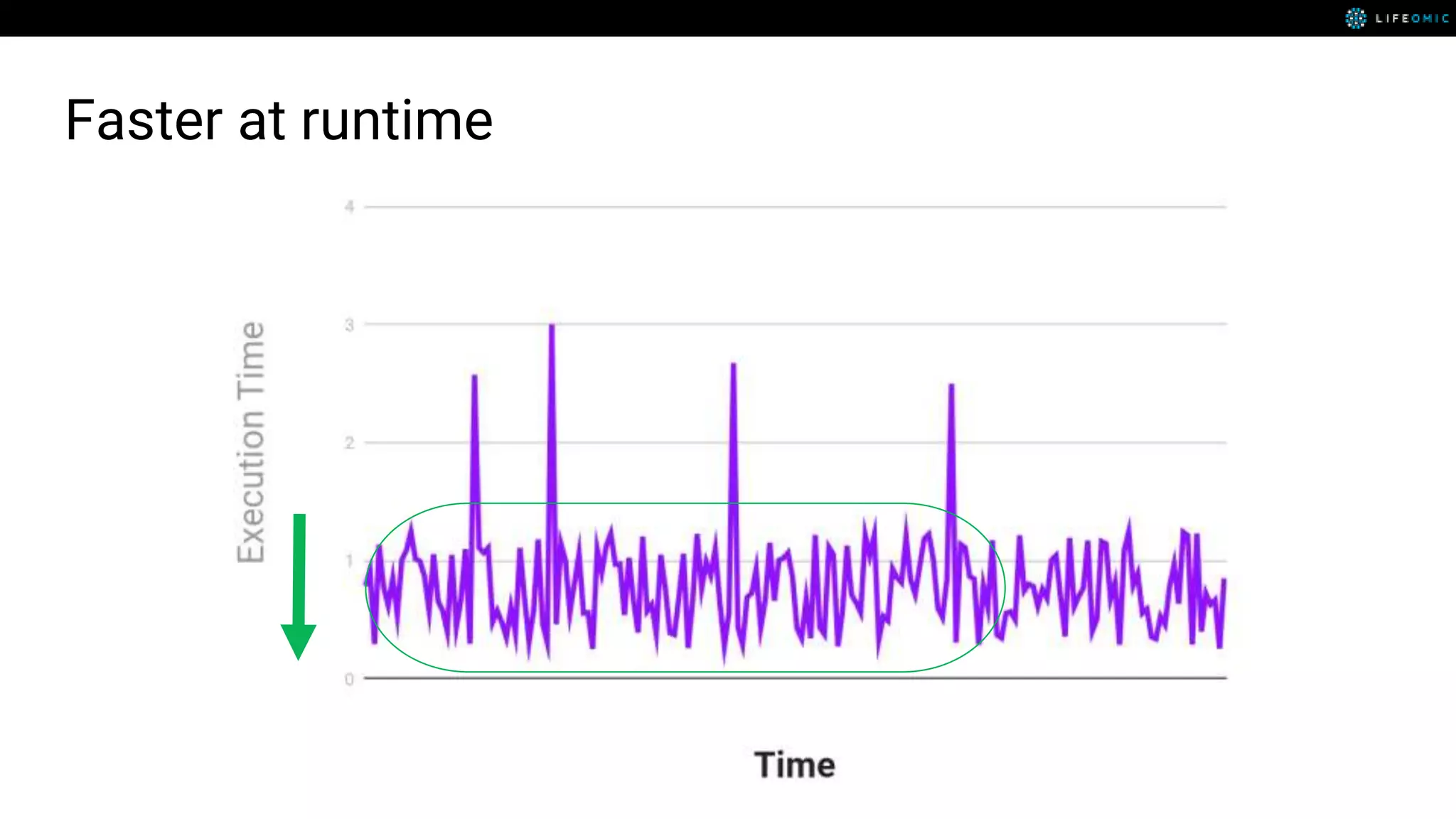
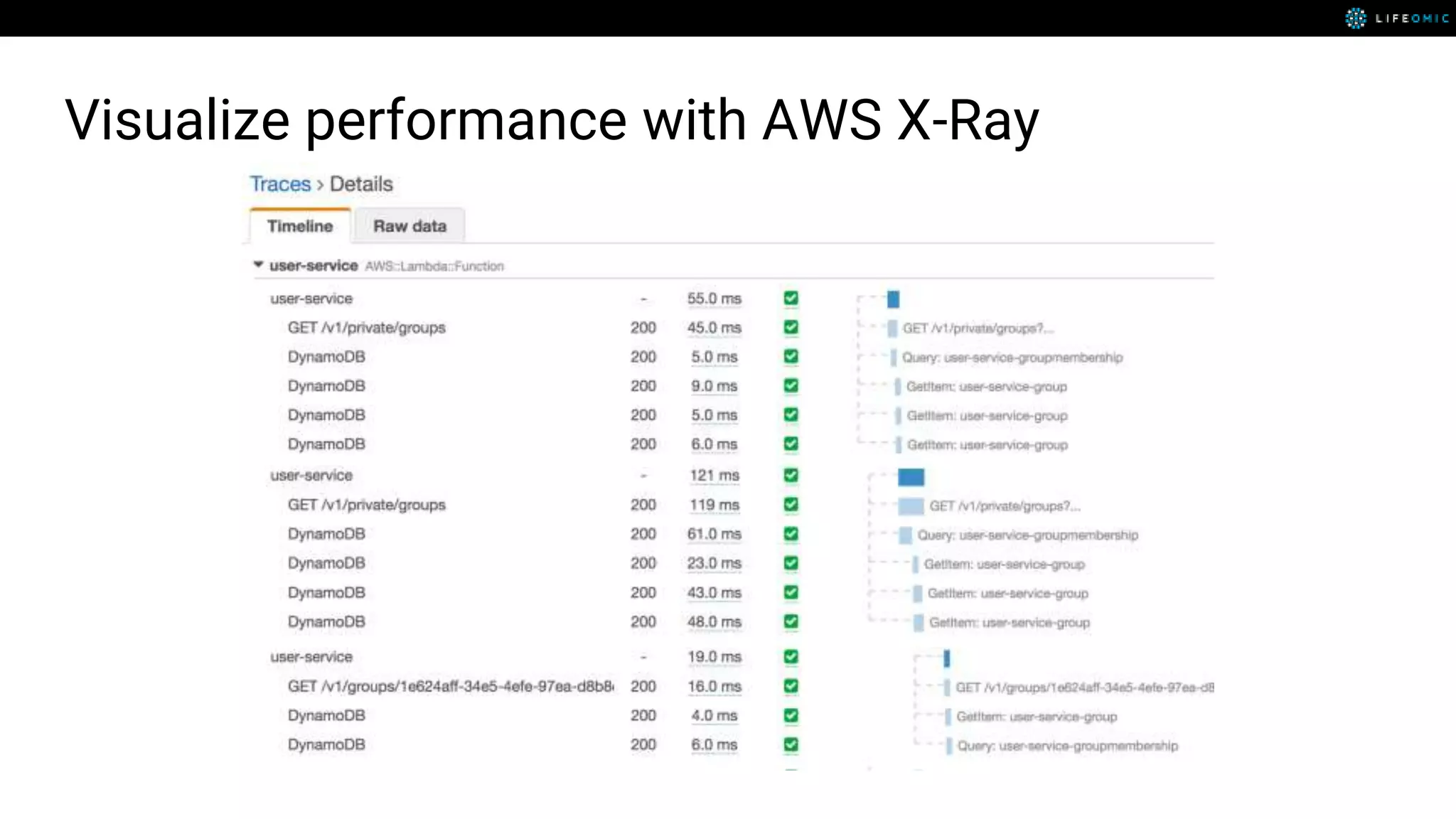
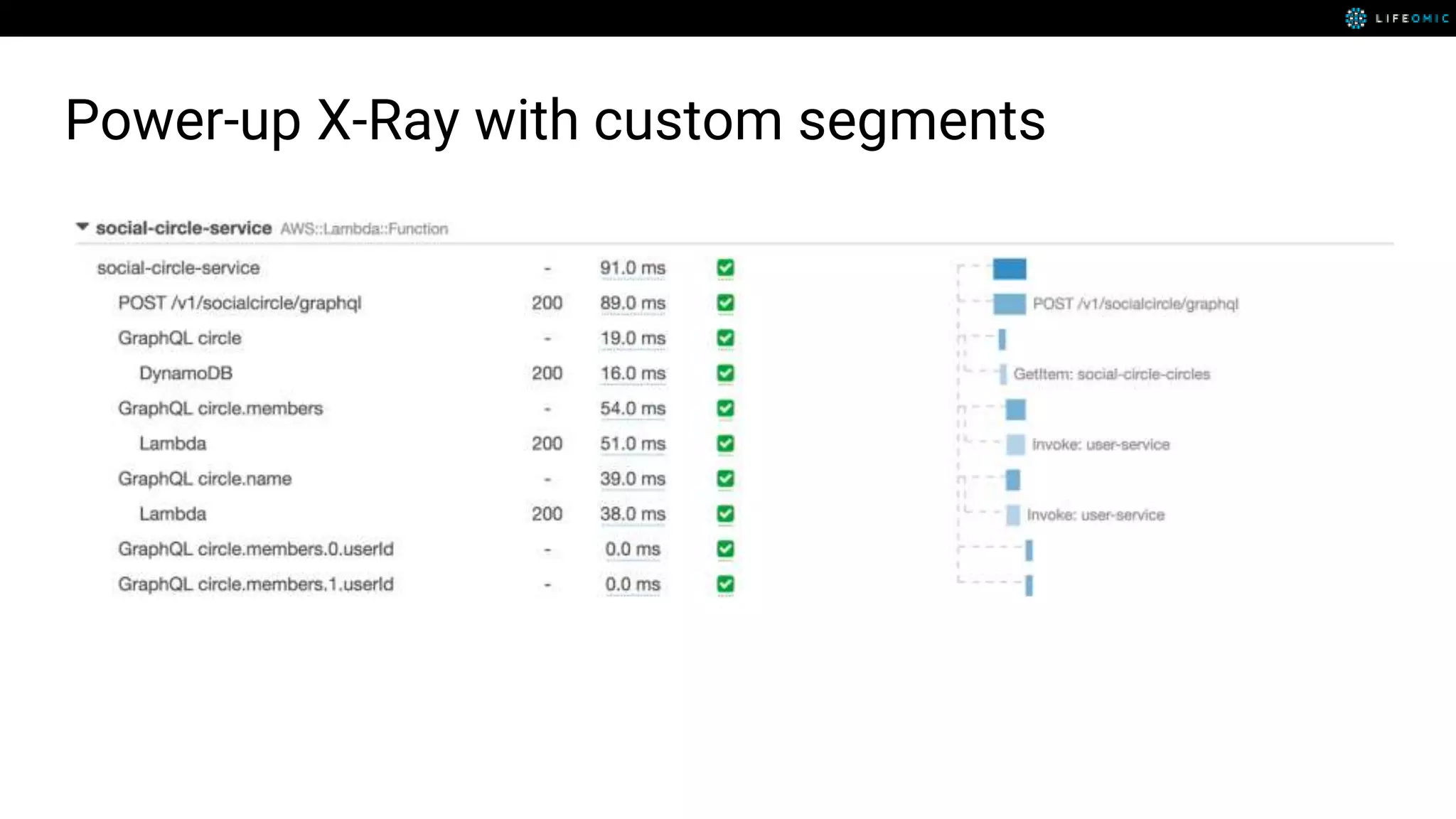
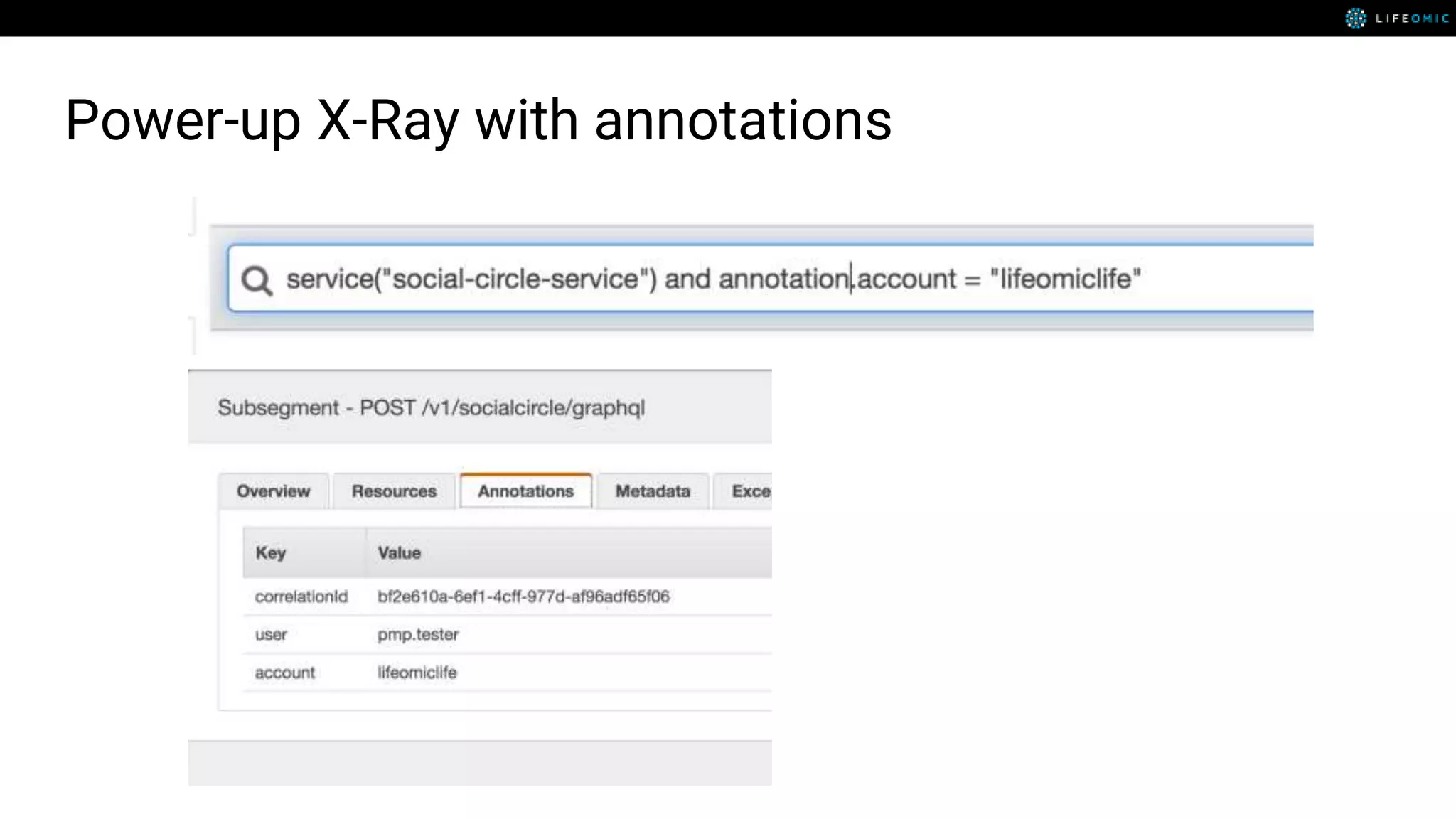
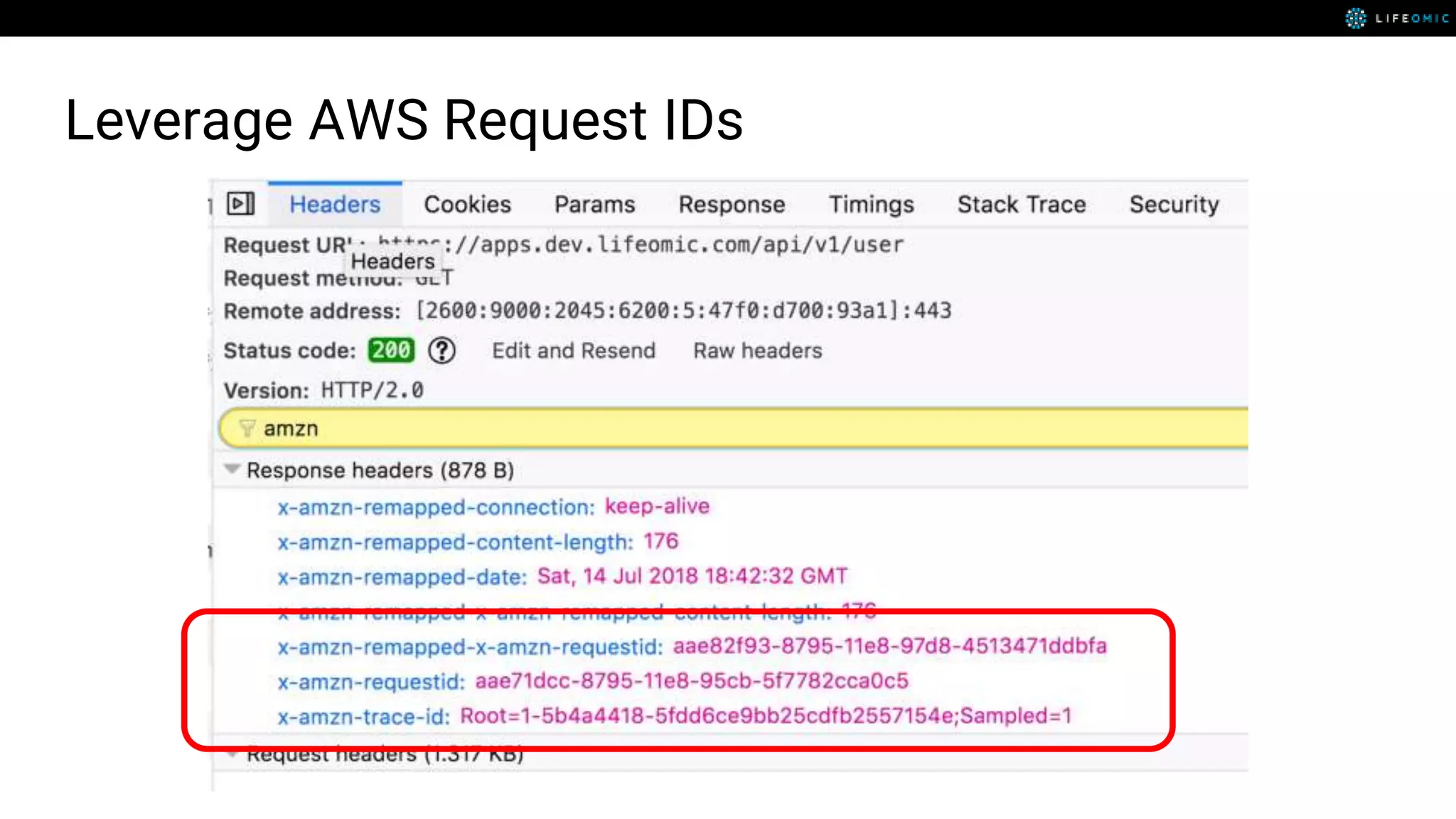
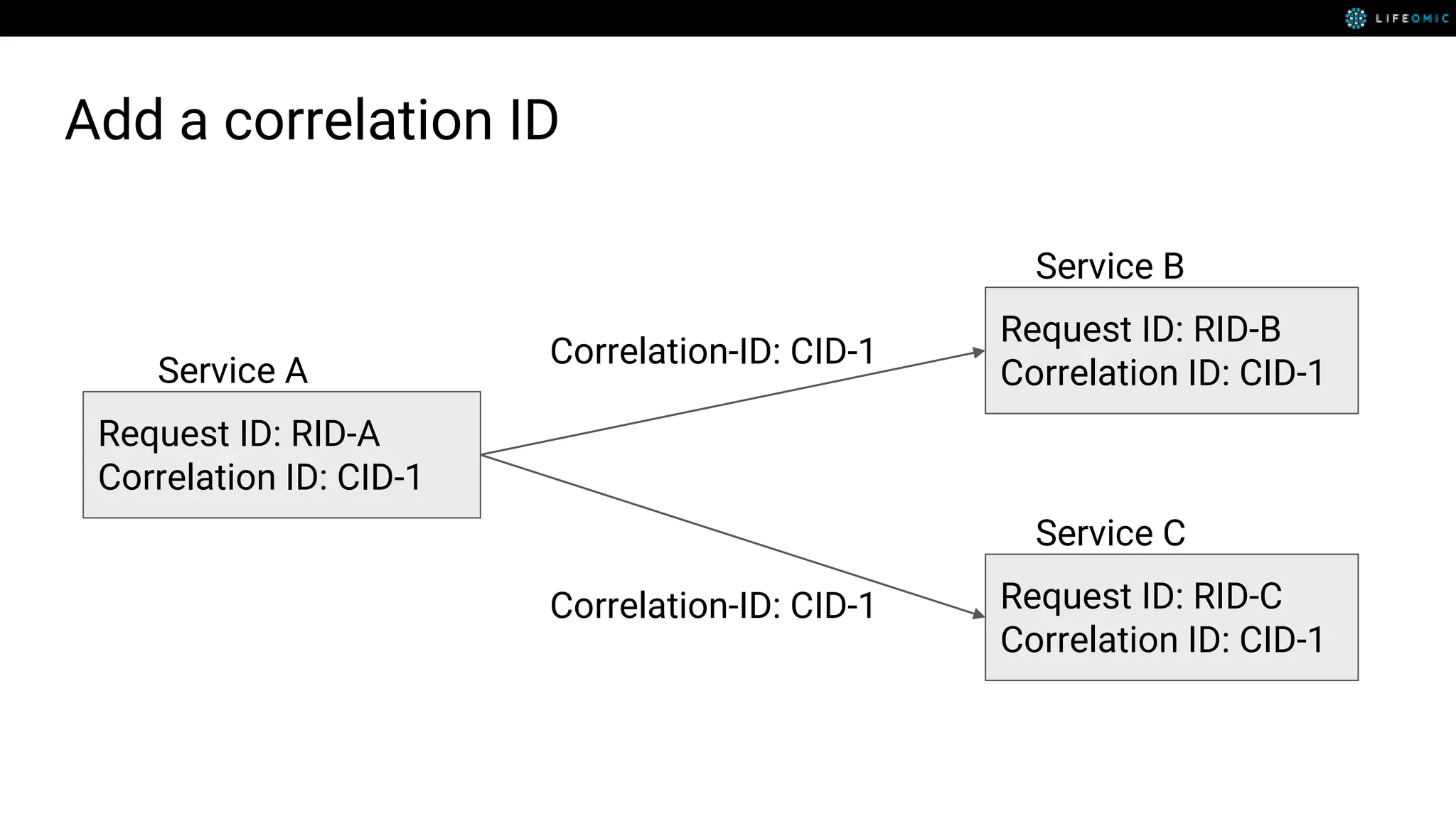
The document provides strategies for optimizing AWS Lambda functions to enhance execution speed and simplify debugging. Key recommendations include improving latency, utilizing cached resources, and integrating AWS X-Ray for performance visualization. Additional tips encompass memory management, effective logging practices, and minimizing package size using webpack.