Downloaded 341 times











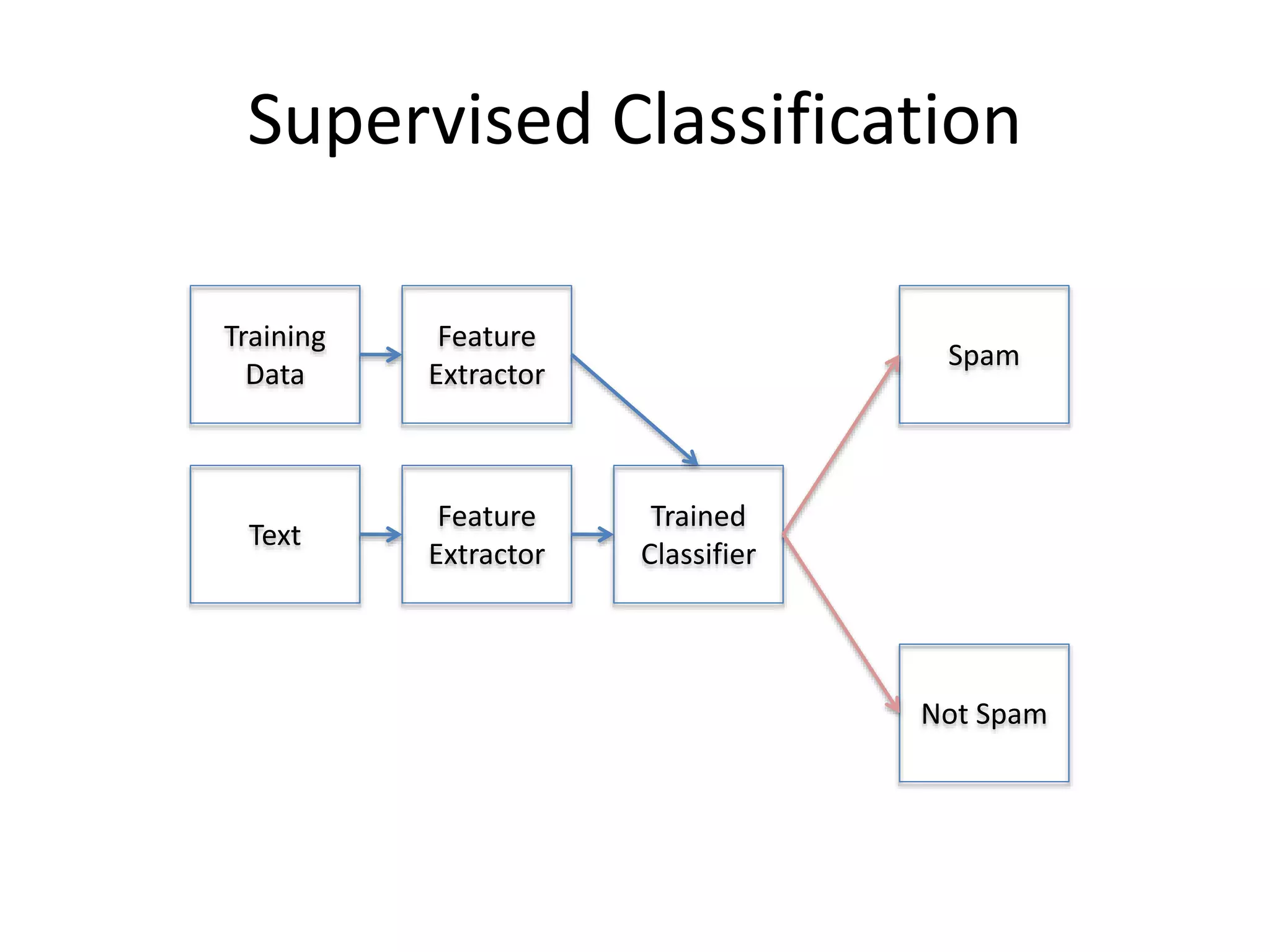

![Features def document_features(self, document): document_words = set(document) features = {} for word in self.word_features: features['contains(%s)' % word] = (word in document_words) return features Break tweets into lists of relevant words.](https://image.slidesharecdn.com/nycpython-090811161045-phpapp02/75/Practical-Data-Analysis-in-Python-19-2048.jpg)


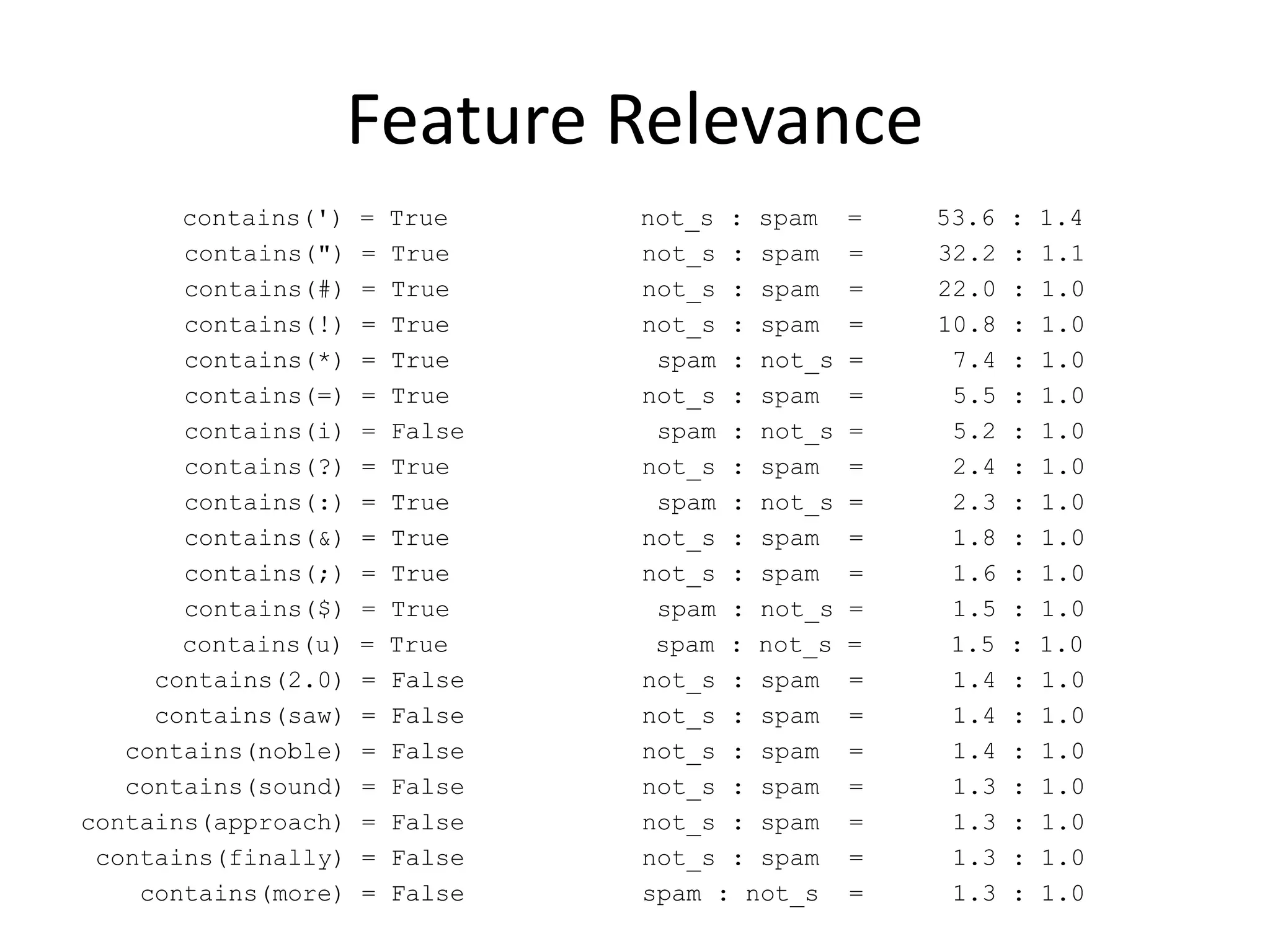




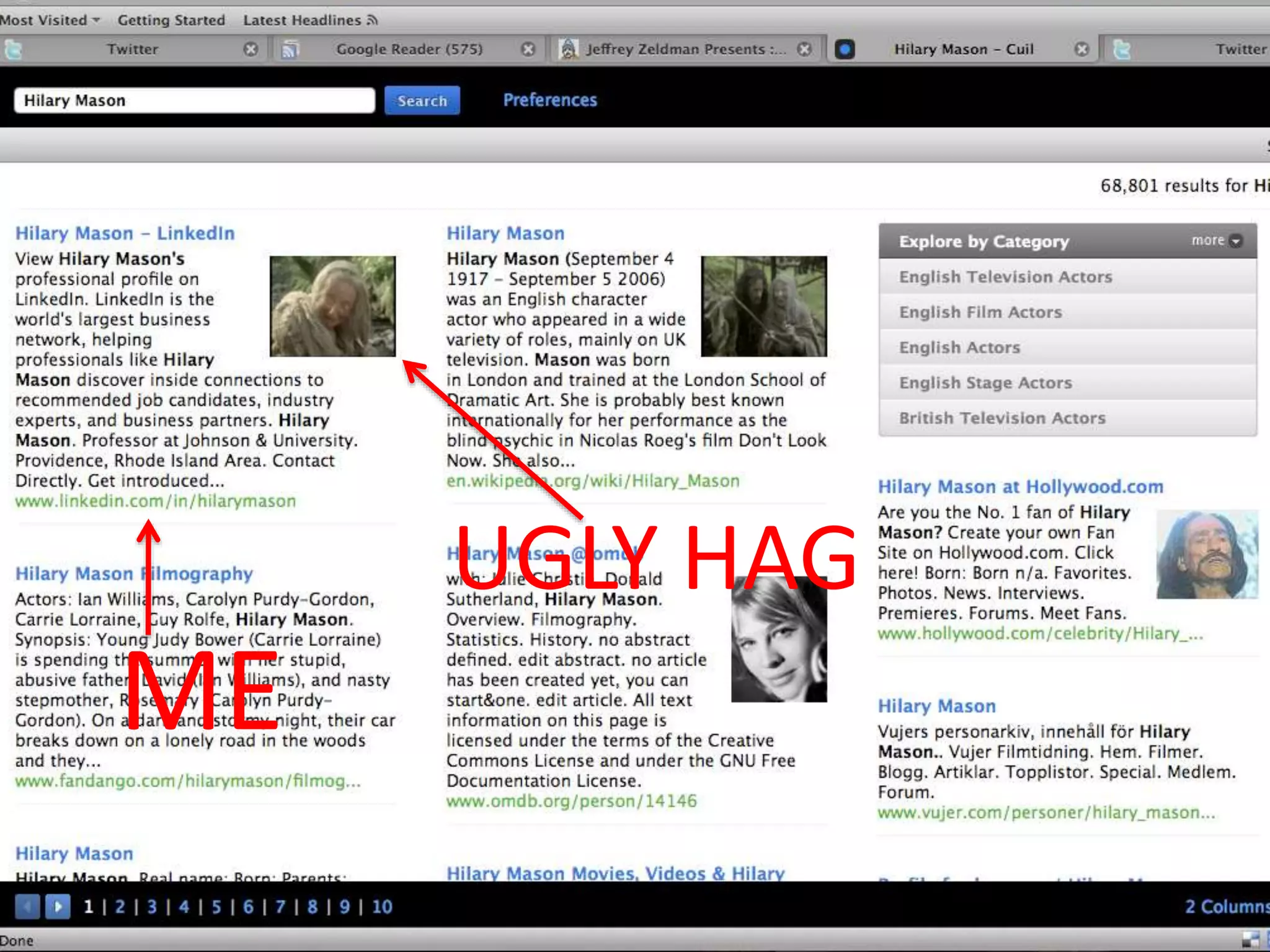
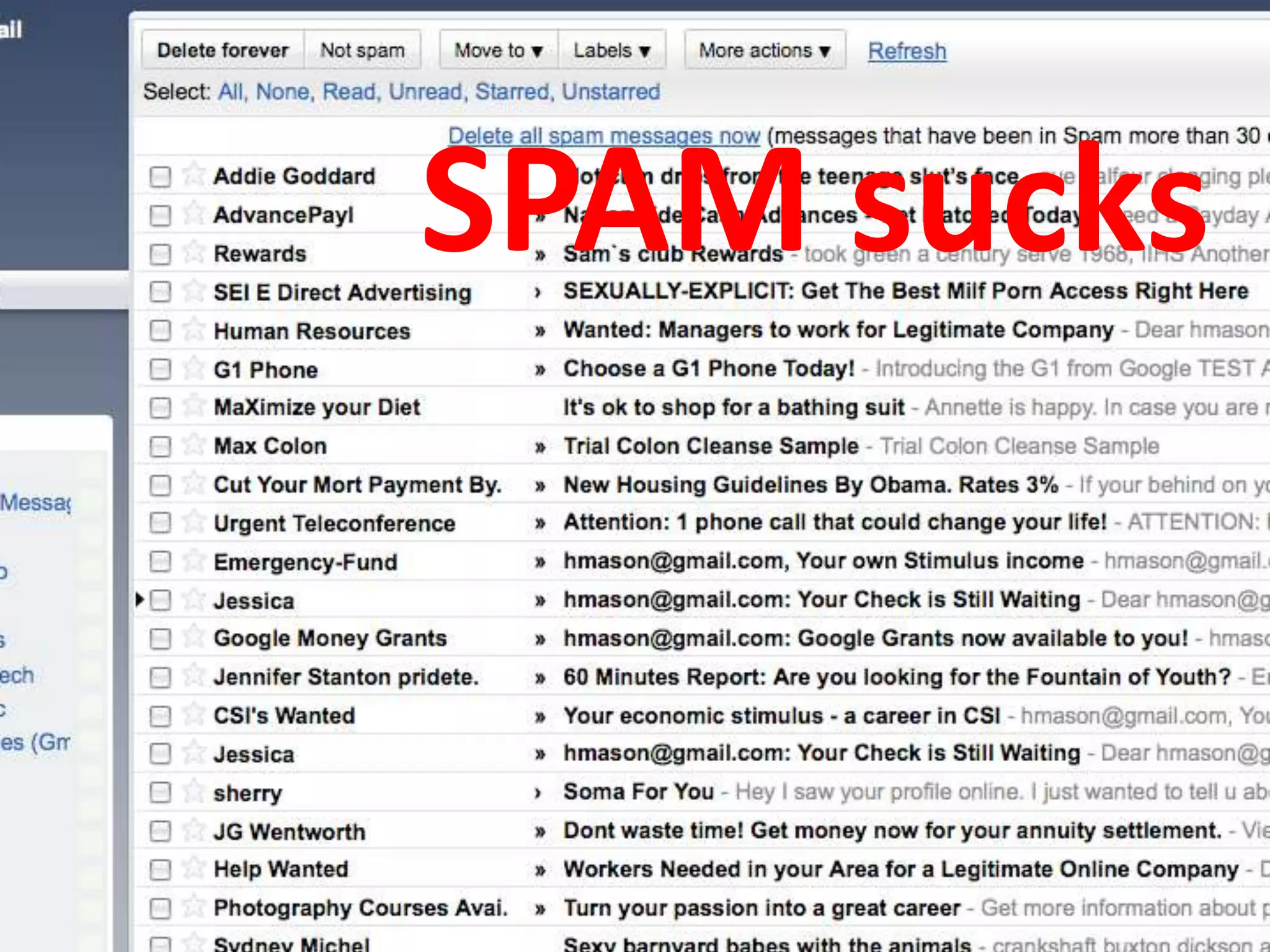
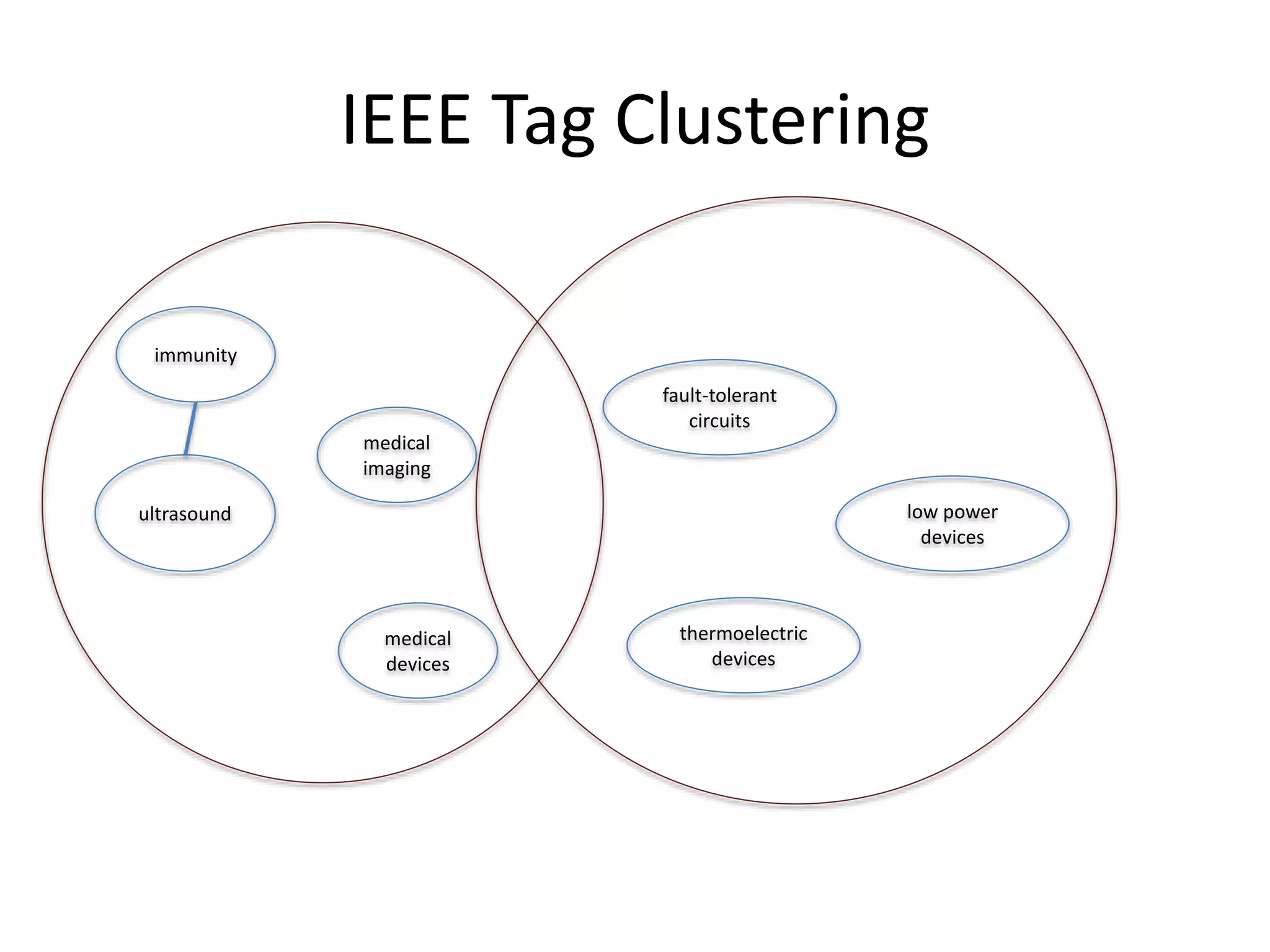
The document discusses practical data analysis in Python, focusing on the challenges of using and analyzing rapidly changing and semi-structured data. It emphasizes the importance of entity disambiguation and various applications of data analysis such as spam classification and recommendation systems, using Python libraries like NLTK and SciPy. Additionally, it showcases a spam classifier trained on tweets, achieving 90% accuracy in identifying spam content.