Downloaded 198 times



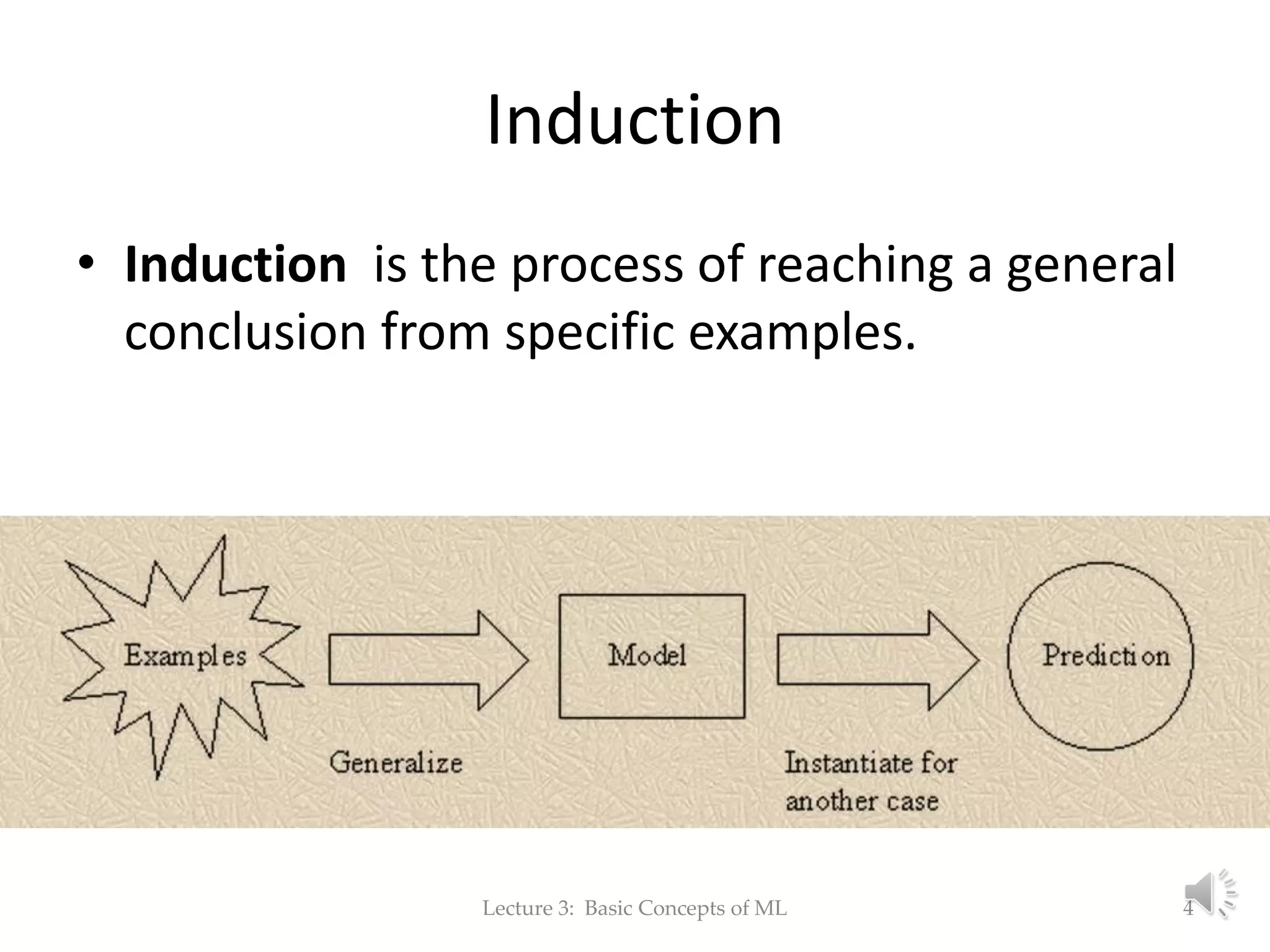

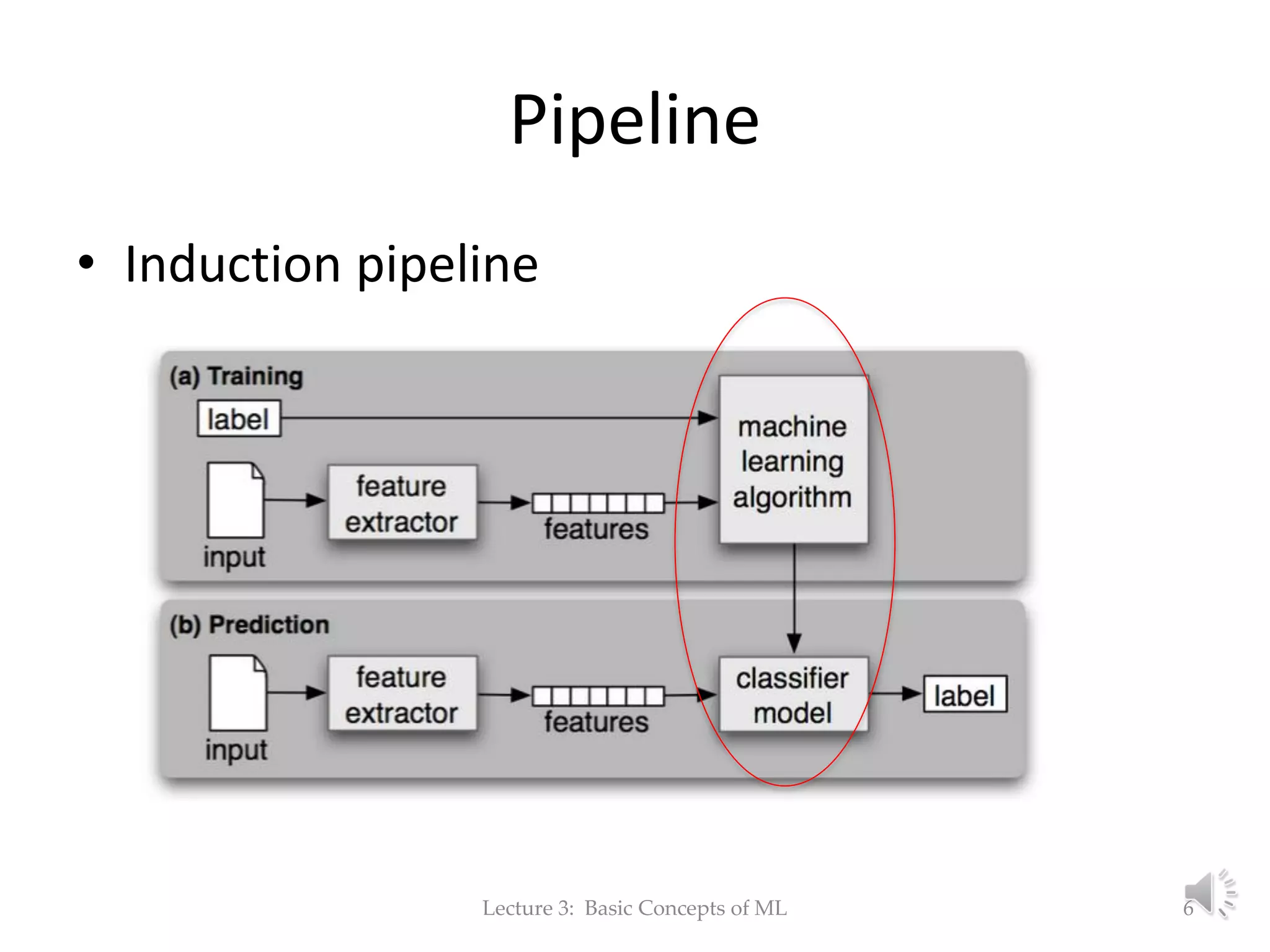
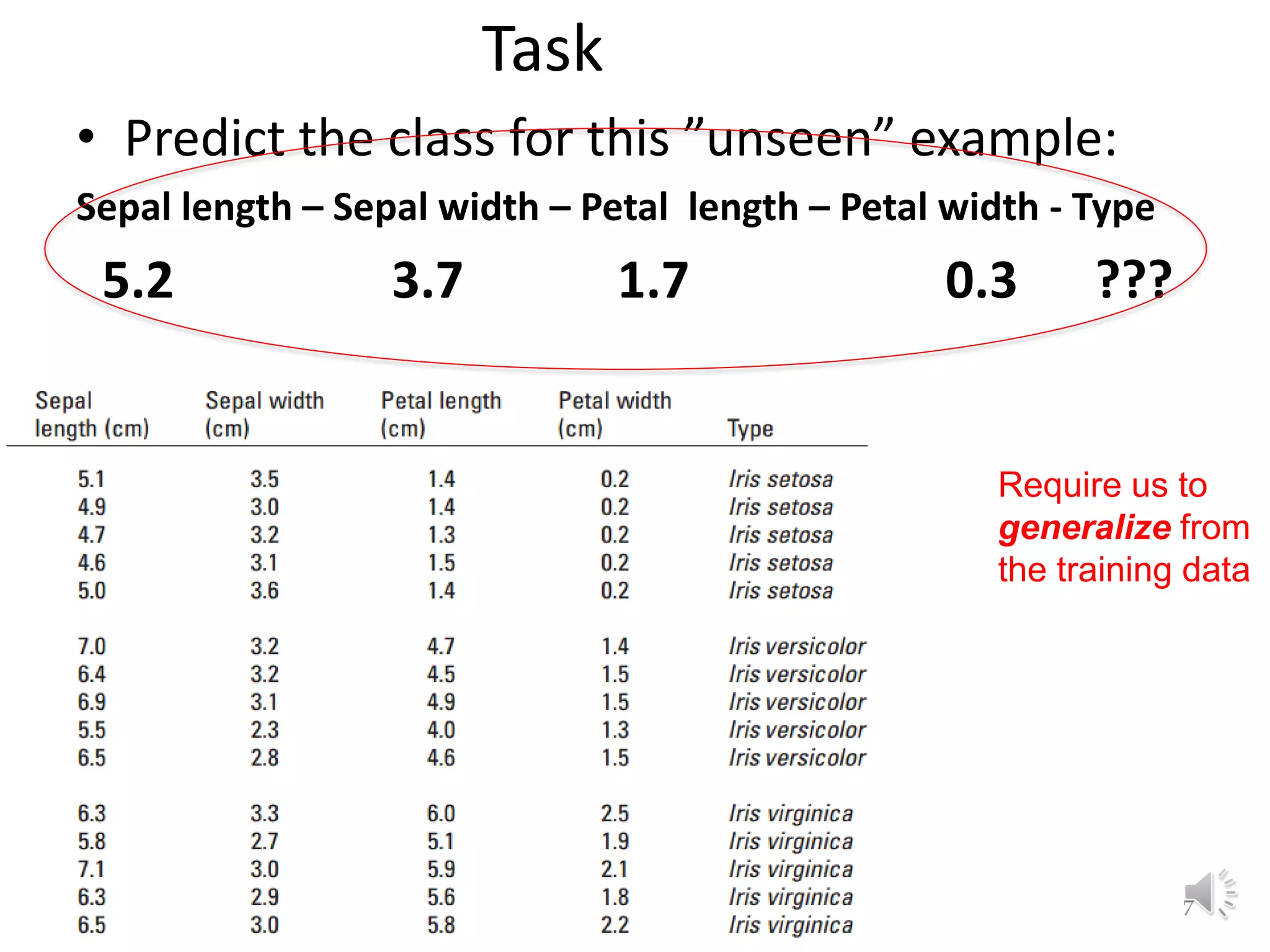
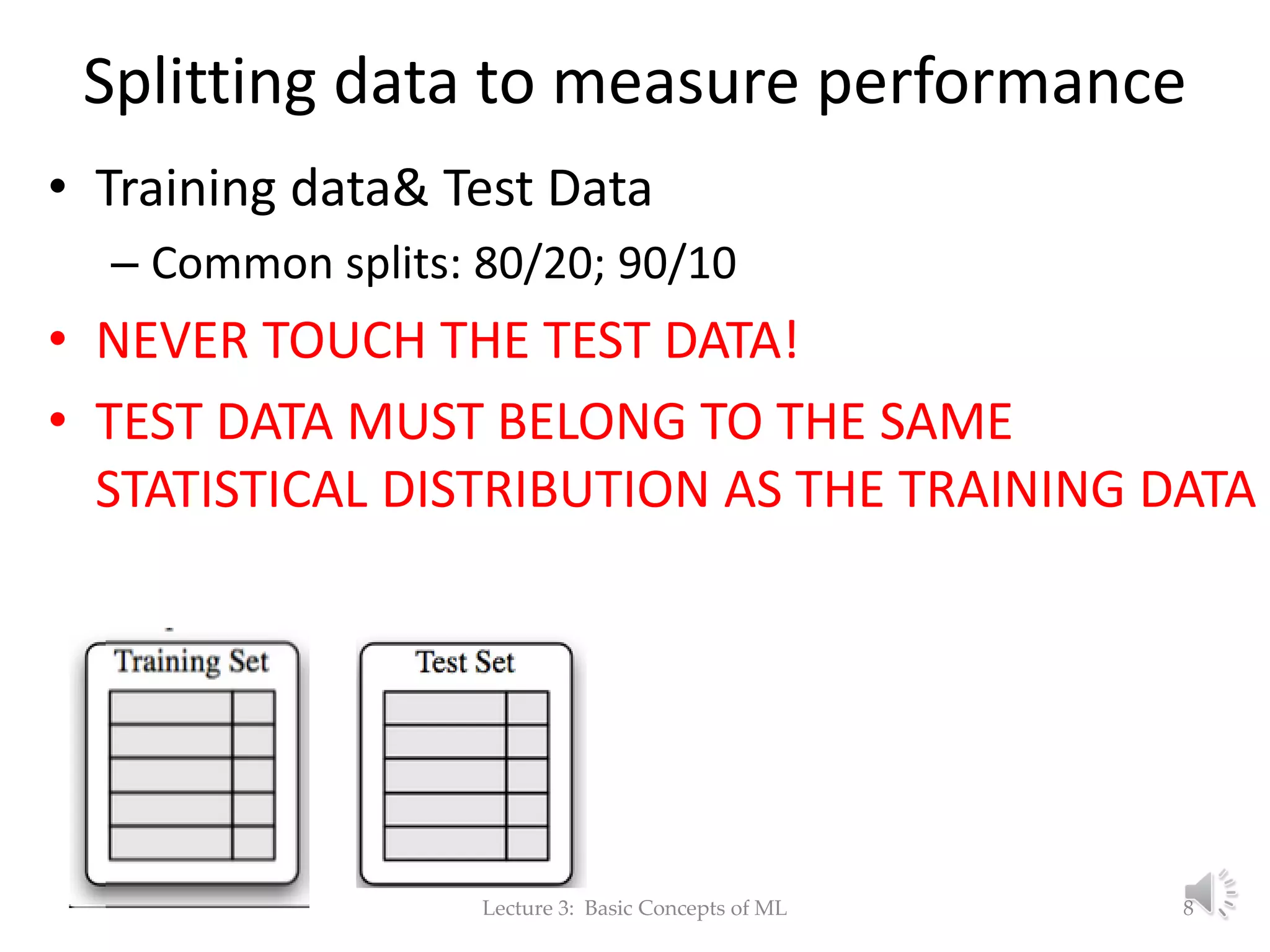


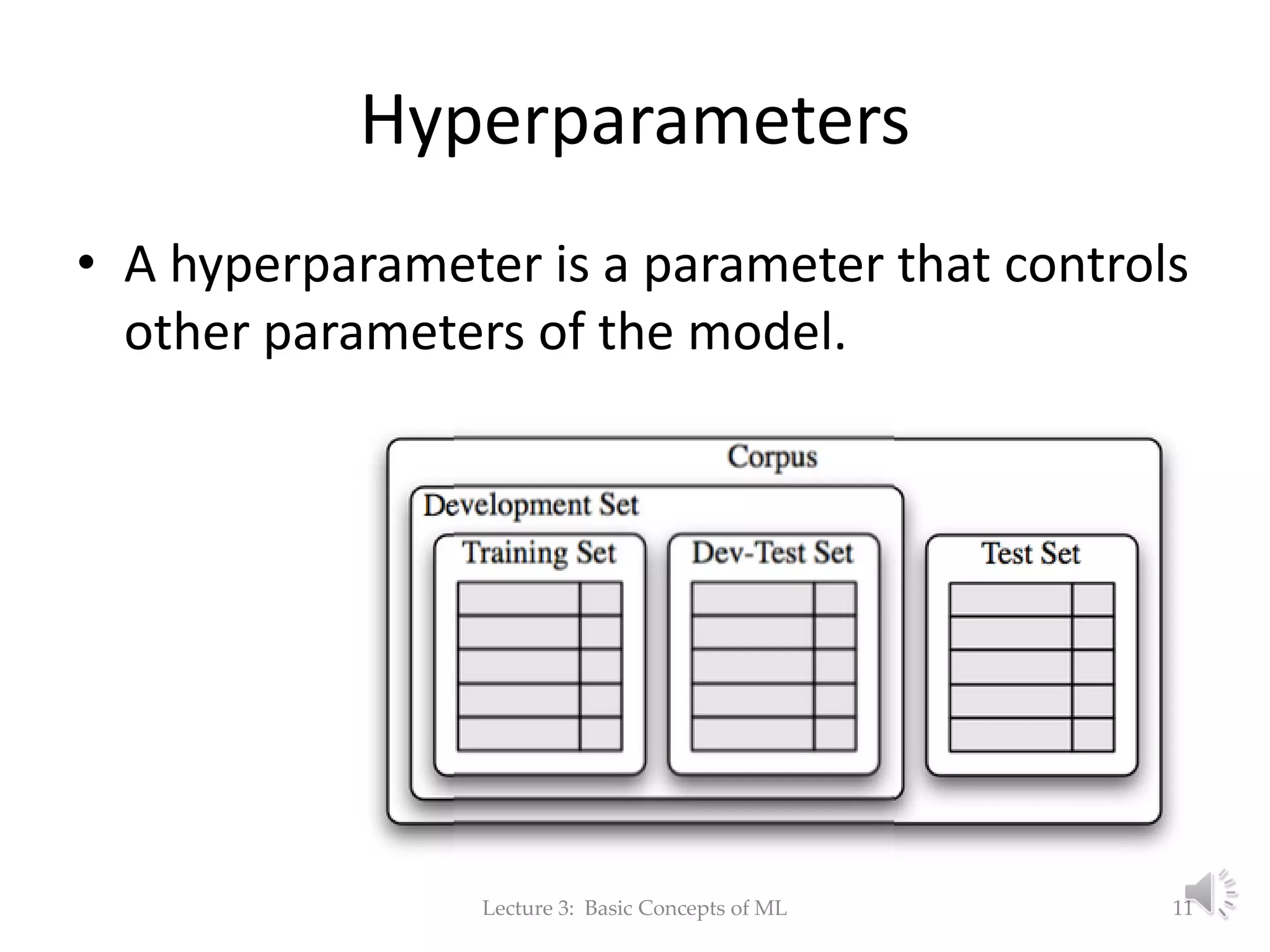










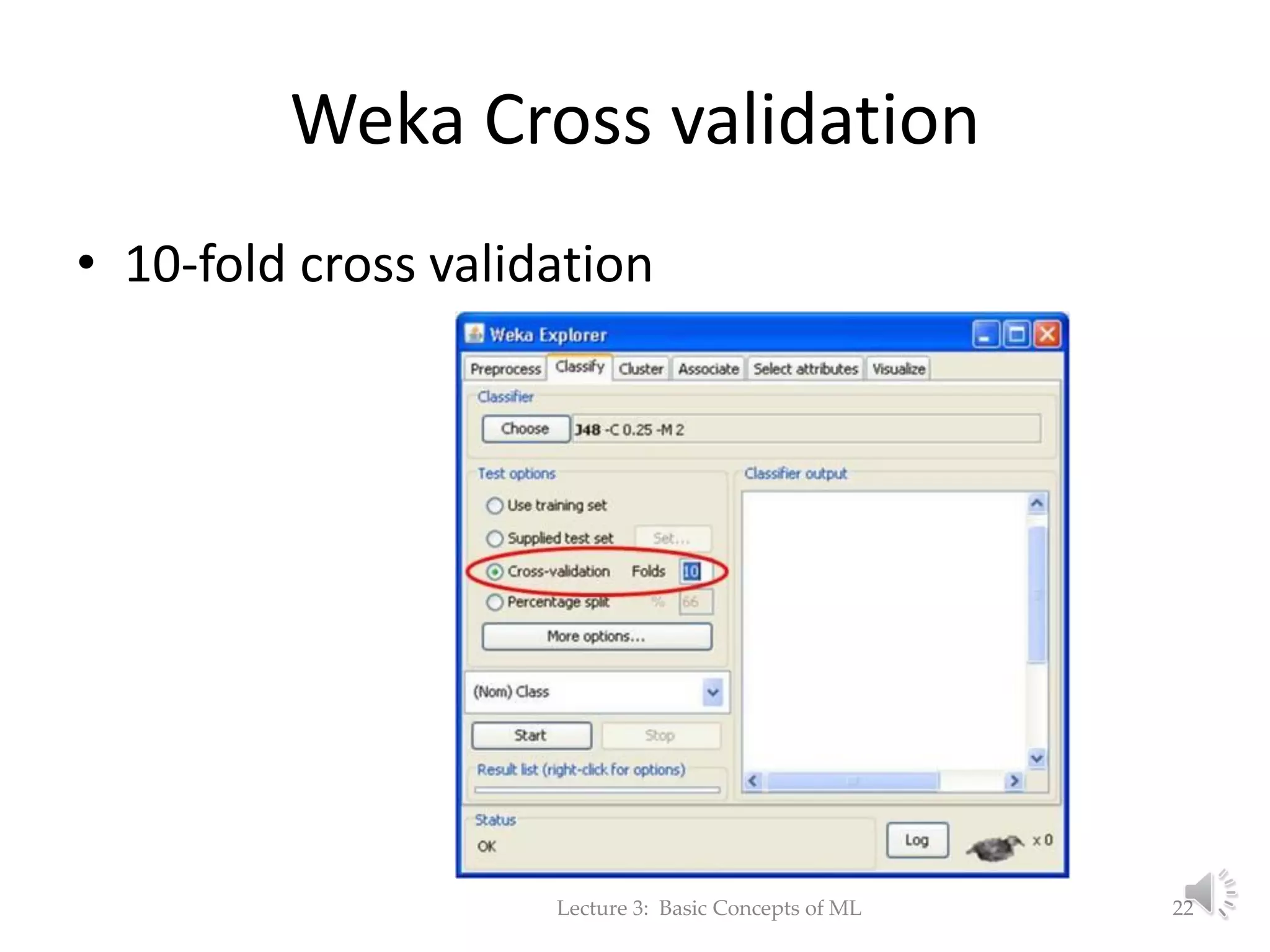
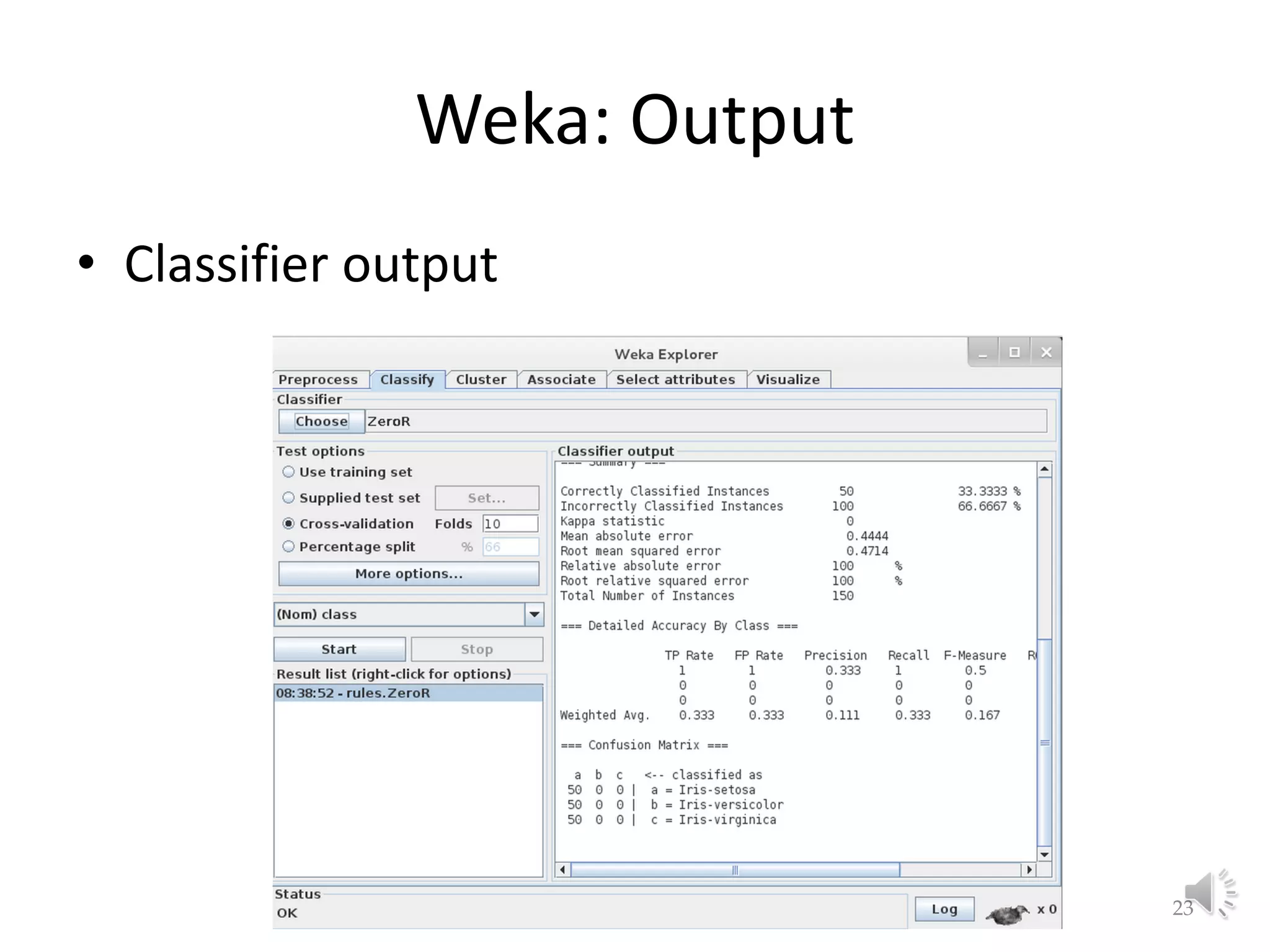









The document discusses fundamental concepts of machine learning, focusing on induction, model evaluation techniques, including accuracy, precision, recall, and the confusion matrix. It outlines the induction pipeline, data splitting strategies, and emphasizes the importance of choosing appropriate models and hyperparameters for effective learning. Additionally, it addresses challenges like underfitting and overfitting, and the need for representative data distributions when training and testing models.